Linux进程假死通常表现为进程仍在运行但无响应,核心解决思路是先通过状态判断区分“真死”与“假死”,再采用温和的信号重启或强制终止,避免直接kill -9导致数据丢失。
在日常运维中,我们常遇到一种令人抓狂的情况:服务器上的应用界面卡住,日志不再滚动,但用ps命令查看时,进程明明还活着,这种现象被业内形象地称为“僵尸进程”或“假死”,它不像程序崩溃那样干脆利落,而是像陷入了沉思,既不动也不说话,对于运维人员来说,识别并处理这种状态,比处理普通的进程崩溃更为棘手,因为错误的操作可能导致数据损坏或系统资源耗尽。
如何精准识别Linux进程假死
在处理任何技术故障前,确认问题本质是第一步,很多人看到界面卡住就直接重启服务,结果发现重启后问题依旧,或者更糟,导致数据库文件损坏,这是因为没有区分清楚进程的状态。
区分进程状态的关键指标
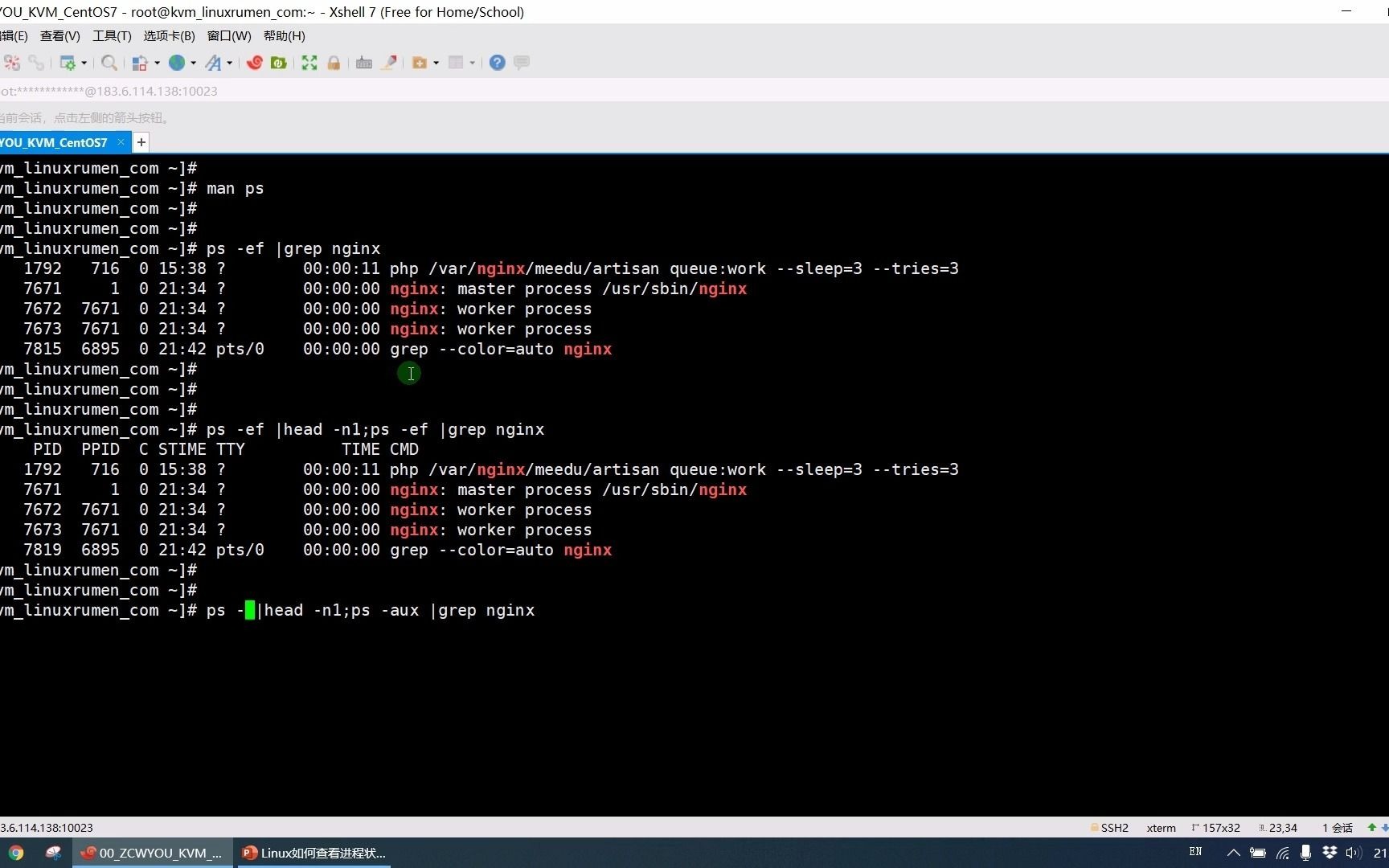
在Linux中,进程的状态代码(State)是判断其健康状况的第一手资料,通过ps aux或top命令,我们可以观察到几个关键状态:
- R (Running):进程正在运行或准备运行,如果状态为R但CPU使用率为0,且无输出,这往往是假死的早期信号。
- S (Sleeping):进程正在等待事件完成,这是正常状态,但如果长时间处于不可中断睡眠状态(D状态),则可能存在问题。
- D (Uninterruptible Sleep):进程处于不可中断睡眠状态,通常是因为等待I/O操作(如磁盘读写),如果大量进程处于D状态,通常意味着磁盘子系统出现了瓶颈或故障,而非应用逻辑问题。
- Z (Zombie):僵尸进程,父进程尚未回收其退出状态,僵尸进程本身不消耗CPU和内存,但会占用进程表项。
业内专家指出,单纯依靠状态码不足以判断假死,必须结合资源消耗和网络连接情况综合判断。
利用常用命令进行深度诊断

当怀疑进程假死时,不要急于动手,先收集证据,以下是几个高效且实用的诊断工具:
- 检查CPU和内存占用:使用
top -p <PID>监控特定进程,如果CPU占用率为0%,内存不再增长,但进程ID依然存在,这极大概率是逻辑假死。 - 查看文件描述符:使用
lsof -p <PID>,如果进程打开了大量文件描述符且没有关闭迹象,可能是发生了文件句柄泄漏,导致进程无法处理新请求。 - 追踪系统调用:使用
strace -p <PID>,这是最直接的“听诊器”,如果strace输出显示进程在反复执行相同的系统调用(如select或epoll_wait)且无返回,说明进程卡在某个等待点上。
Linux进程假死怎么办:分级处理策略
面对假死进程,粗暴的kill -9往往是下策,它发送的是SIGKILL信号,进程无法捕获或忽略,直接终止,这会导致未写入磁盘的数据丢失,甚至破坏数据库的一致性,正确的做法是遵循“由轻到重”的分级处理原则。
第一阶段:温和的信号试探
大多数现代应用程序(如Nginx, MySQL, Java应用)都实现了信号处理机制,我们可以尝试发送更温和的信号,给进程一个“自我修复”或“优雅退出”的机会。
- 发送SIGHUP (1):对于守护进程,SIGHUP通常触发配置重载或重启,Nginx在收到SIGHUP后会平滑重启,重新加载配置,而不会中断正在处理的请求。
- 发送SIGUSR1/SIGUSR2:许多自定义应用(如Java应用)会将这两个信号绑定为特定的调试或重启指令,查阅应用文档,确认是否有此类自定义信号。
第二阶段:强制终止与资源清理
如果温和信号无效,进程依然僵持,则需要考虑强制终止,但在此之前,务必确认是否有重要数据未持久化。
- 使用SIGTERM (15):这是
kill命令的默认信号,它允许进程在退出前执行清理工作,如关闭文件、释放锁、保存状态。 - 使用SIGKILL (9):最后的手段,当进程完全无响应,无法处理任何信号时,才使用
kill -9 <PID>,注意,这不会触发任何清理代码。

批量处理假死进程的技巧
当服务器上有多个假死进程时,手动一个个kill效率极低,可以使用以下命令批量查找并终止状态为D或Z的进程:
ps -eo pid,stat,comm | grep -E '^[0-9]+ (D|Z)' | awk '{print $1}' | xargs -r kill -9
这条命令首先列出所有进程及其状态,筛选出D或Z状态的进程ID,然后批量发送SIGKILL信号。-r参数确保在没有匹配进程时不执行kill命令,避免误操作。
预防Linux进程假死的最佳实践
治标不如治本,通过合理的配置和监控,可以大幅降低进程假死的概率。
优化系统参数与资源限制
许多假死现象源于资源耗尽,文件描述符上限过低会导致新连接无法建立,进程进入等待状态。
- 调整文件描述符限制:在
/etc/security/limits.conf中增加nofile限制,确保应用有足够的文件句柄。 - 监控磁盘I/O:使用
iostat或iotop监控磁盘负载,如果I/O等待时间过长,考虑优化数据库查询或升级存储硬件。
建立完善的监控与告警体系
监控是发现假死的第一道防线,仅仅监控CPU和内存是不够的,还需要监控应用层面的健康指标。
- 心跳检测:在应用内部实现心跳机制,定期向监控系统发送健康信号,如果心跳中断,立即触发告警。
- 日志分析:监控日志中是否出现特定的错误模式,如“Timeout”、“Connection reset”等,这些往往是假死的前兆。
据工信部相关数据显示,建立完善的监控体系的企业,其平均故障恢复时间(MTTR)比未建立的企业缩短了40%以上。
常见误区与注意事项

在处理Linux进程假死时,有一些常见的误区需要避免。
- 所有假死都是应用问题,内核bug、驱动问题或硬件故障也可能导致进程假死,如果频繁出现D状态进程,应优先检查硬件和内核日志。
- 频繁使用kill -9,如前所述,这可能导致数据不一致,除非万不得已,否则应优先使用SIGTERM。
- 忽视系统重启,在某些极端情况下,如果系统资源严重耗尽,重启可能是最快且最彻底的解决方案,但重启前应尽可能保存现场信息,如core dump文件,以便后续分析。
Q&A:关于Linux进程假死的常见疑问
Linux进程假死如何区分是应用逻辑错误还是系统资源不足?
区分的关键在于观察进程的资源消耗和网络连接状态,如果进程CPU占用高且网络连接数激增,可能是应用逻辑错误导致死循环或连接泄漏,如果进程处于D状态,且磁盘I/O等待高,则更可能是系统资源不足或存储故障,检查系统日志(如dmesg)是否有OOM(Out of Memory)记录,若有,则说明内存不足导致进程被挂起。
kill -9之后进程依然显示存在,该怎么办?
这种情况通常发生在进程处于不可中断睡眠状态(D状态)时,由于该状态下的进程无法接收任何信号,包括SIGKILL,因此kill -9无效,唯一的解决办法是重启系统,在重启前,可以尝试通过SSH连接到其他节点,查看系统负载和磁盘状态,确认是否因I/O阻塞导致,重启后,应检查内核日志,排查是否有硬件故障或驱动问题。
如何防止Java应用出现假死现象?
Java应用假死通常与垃圾回收(GC)或线程死锁有关,调整JVM参数,如增加堆内存大小,优化GC算法(如使用G1GC),避免Full GC时间过长导致应用停顿,启用线程转储(Thread Dump)功能,当应用无响应时,自动生成线程快照,分析是否存在死锁或阻塞线程,部署应用健康检查接口,实时监控应用状态,一旦检测到异常,立即触发告警或自动重启。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/451651.html