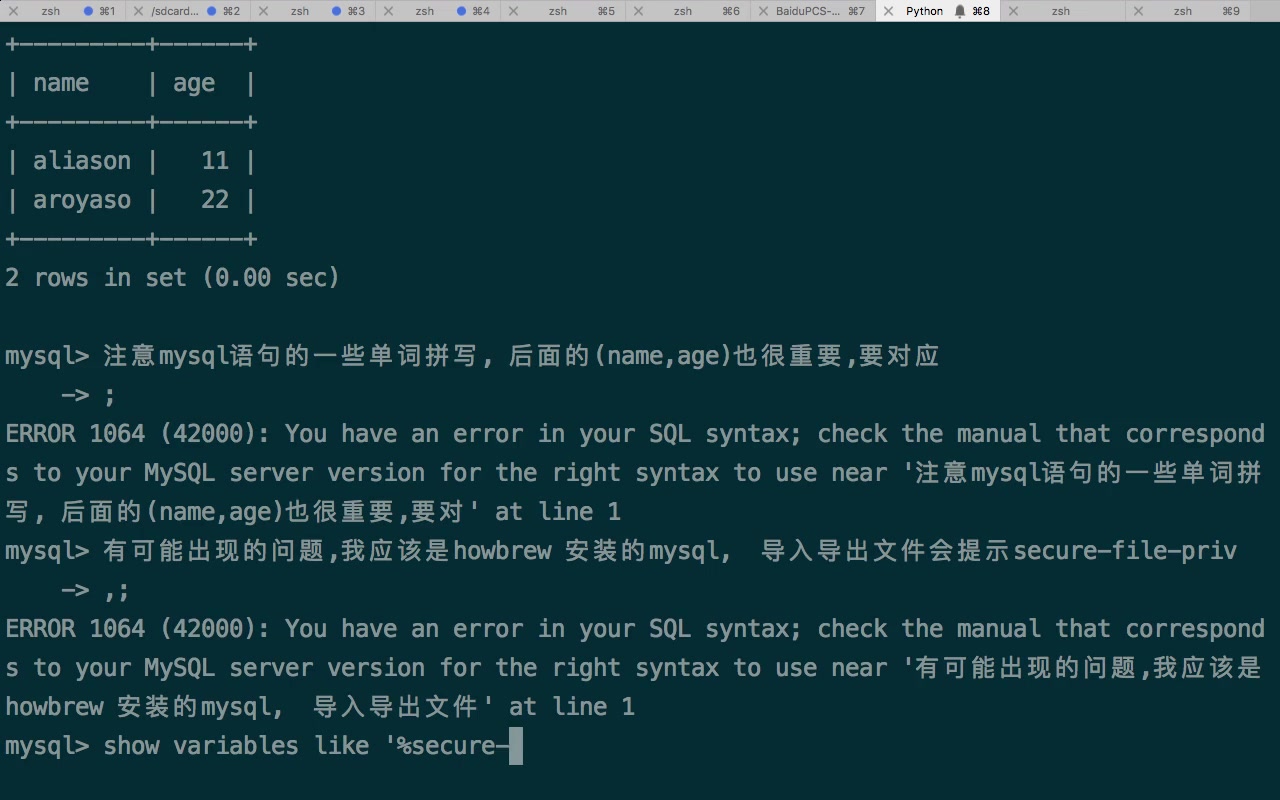
将CSV文件导入MySQL数据库最稳定且高效的方式是使用MySQL自带的LOAD DATA INFILE命令,它能比常规INSERT语句快10倍以上完成数据迁移,是处理百万级数据的首选方案。
在数据驱动业务的今天,CSV文件因其轻量、通用和易于编辑的特性,成为了数据交换的事实标准,当我们需要将这些静态数据转化为动态数据库资源时,许多开发者往往陷入性能瓶颈,业内专家指出,对于大规模数据迁移,盲目使用图形化界面或逐行插入代码,不仅耗时耗力,还极易导致数据库锁表或服务中断,掌握正确的导入技巧,不仅是技术能力的体现,更是保障业务连续性的关键。
CSV文件输入MySQL的核心原理与优势对比
理解底层机制是解决技术难题的前提,MySQL处理CSV数据并非简单的文本读取,而是涉及文件解析、类型转换和事务日志记录等多个环节。
传统INSERT语句与LOAD DATA的性能鸿沟
很多初学者习惯使用Python或Java编写循环,逐行生成INSERT语句并执行,这种方法在数据量小于1000条时尚可接受,但一旦数据量达到万级或十万级,性能差距将呈指数级放大。
- 事务开销巨大:每条INSERT语句默认开启一个事务,频繁提交事务会产生大量的I/O操作。
- 索引重建频繁:每插入一行,数据库可能需要重新平衡B+树索引,导致CPU飙升。
- 网络往返延迟:客户端与服务器之间的多次握手增加了网络延迟。
相比之下,LOAD DATA INFILE命令允许服务器直接读取本地或远程文件,并在服务器端进行批量解析,它禁用了部分索引检查,批量提交事务,甚至支持并行处理,速度通常比INSERT快10到100倍。
不同导入场景的选型建议
根据数据规模和业务需求,选择合适的导入工具至关重要。
小规模数据(<1万行)
对于测试环境或小型报表,使用Navicat、DBeaver等数据库管理工具的图形化导入功能最为便捷,这些工具自动处理分隔符和转义字符,无需编写SQL,适合非技术人员操作。

中大规模数据(1万-100万行)
此时图形化工具可能因内存溢出而崩溃,建议使用MySQL命令行客户端配合LOAD DATA命令,通过调整参数,可以精确控制导入过程,确保数据一致性。
超大规模数据(>100万行)
对于TB级数据,单一服务器可能无法承受,此时需考虑使用mysqldump的反向操作,或采用ETL工具如Apache NiFi、Kettle,甚至利用云数据库提供的专用迁移服务。
实操指南:使用LOAD DATA INFILE高效导入
这是目前公认最标准的CSV文件输入方法,以下步骤基于Linux环境下的MySQL 8.0+版本,适用于绝大多数生产场景。
准备工作:环境与安全配置
在执行导入前,必须确保MySQL用户具备必要的权限,并且文件路径符合安全策略。
- 权限检查:执行用户需拥有FILE权限,若没有,请联系DBA授权,切勿随意赋予root权限。
- 文件位置:LOAD DATA默认读取服务器本地文件,若CSV在客户端,需使用LOAD DATA LOCAL INFILE,但这需要客户端和服务器端同时启用local_infile参数。
- 字符集统一:确保CSV文件的编码(如UTF-8)与MySQL表的字符集一致,避免乱码。
标准导入语句详解
一条完整的LOAD DATA语句包含文件路径、字段分隔符、行终止符和列映射等关键信息。
LOAD DATA INFILE '/path/to/your/data.csv' INTO TABLE your_table_name CHARACTER SET utf8mb4 FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY 'n' IGNORE 1 LINES (column1, column2, column3);
关键参数解析
- FIELDS TERMINATED BY ‘,’:定义字段分隔符,CSV通常使用逗号,但若数据中包含逗号,需配合ENCLOSED BY使用。
- ENCLOSED BY ‘”‘:定义字段包裹符,大多数CSV文件用双引号包裹含特殊字符的字段,此参数确保数据被正确识别。
- LINES TERMINATED BY ‘n’:定义行分隔符,Windows系统通常为rn,Linux为n,需根据文件来源调整。
- IGNORE 1 LINES:跳过CSV文件的第一行表头,这是防止表头被当作数据插入的关键步骤。
- 列映射:若CSV列顺序与表结构不一致,或在末尾添加空列,必须显式指定列名映射,否则数据将错位。

处理常见错误与异常
导入过程中常遇到数据截断、类型不匹配等问题。
- 数据截断警告:若字段长度不足,MySQL默认会截断数据并给出警告,可通过SET sql_mode = ”临时关闭严格模式,或修改表结构增加字段长度。
- 日期格式错误:CSV中的日期格式(如YYYY-MM-DD)需与MySQL期望格式一致,若不匹配,可在导入时使用函数转换,如STR_TO_DATE(@var, ‘%Y/%m/%d’)。
- 空值处理:CSV中的空值可能被解析为NULL或空字符串,可根据业务需求,在导入前替换为空值标记,或在SQL中使用NULLIF函数处理。
CSV文件输入MySQL的高级技巧与避坑指南
掌握基础操作后,进一步优化导入过程能显著提升效率并降低风险。
批量提交与事务控制
虽然LOAD DATA本身是批量的,但在某些复杂场景下,手动控制事务仍有帮助。
- 禁用自动提交:在执行LOAD DATA前,执行SET autocommit = 0,导入完成后手动COMMIT,这能减少磁盘I/O,提升速度。
- 暂停索引维护:对于非唯一索引,可在导入前DROP,导入后重建,但这仅适用于允许短暂数据不可用的场景,需谨慎操作。
数据清洗前置处理
“垃圾进,垃圾出”是数据领域的铁律,在导入前对CSV进行清洗,能避免后续大量的数据修复工作。
- 去除BOM头:Excel保存的CSV文件常带有UTF-8 BOM头,导致第一列数据出现乱码,使用文本编辑器移除BOM头,或在导入时指定CHARACTER SET utf8mb4。
- 统一换行符:确保CSV文件使用Unix风格的换行符,避免Windows风格导致的解析错误。
- 处理特殊字符:若数据中包含换行符或制表符,需确保ENCLOSED BY参数正确包裹字段,防止行解析错误。

验证导入结果
导入完成后,务必进行数据验证。
- 行数对比:使用SELECT COUNT()对比CSV文件行数与数据库记录数,确保无遗漏。
- 抽样检查:随机抽取几条数据,核对关键字段是否与源文件一致。
- 完整性约束:检查外键约束和唯一性约束是否被违反,若有报错,需定位并修复脏数据。
CSV文件输入MySQL常见问题解答
为什么LOAD DATA INFILE比INSERT快得多?
LOAD DATA INFILE在服务器端直接读取文件,避免了客户端与服务端之间的网络往返延迟,它采用批量解析和批量插入机制,减少了事务提交次数和索引重建频率,它可以暂时禁用唯一性检查(通过IGNORE关键字),进一步加速处理,据行业共识认为,这种底层优化使其在处理百万级数据时,性能优势极为显著。
导入时遇到“File not found”错误怎么办?
此错误通常由文件路径或权限问题引起,首先确认文件确实存在于MySQL服务器指定的路径下,而非客户端本地,检查MySQL进程用户(通常是mysql)是否对该文件及父目录具有读取权限,若使用相对路径,请确保其相对于MySQL的数据目录,对于权限问题,可通过chmod命令调整文件权限,或联系系统管理员协助。
如何处理CSV中包含逗号的数据字段?
本身包含逗号,必须使用引号(通常是双引号)包裹该字段,在LOAD DATA语句中,必须指定ENCLOSED BY ‘”‘参数,告诉MySQL将引号内的内容视为一个整体字段,即使其中包含分隔符,字段值为”New, York”,在CSV中应存储为”New, York”,导入时MySQL会将其正确解析为单个字段”New, York”,而非两个字段。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/452141.html