Hash存储结构通过哈希函数将键映射到固定长度的数组索引,实现平均时间复杂度为O(1)的高效数据检索,是解决海量数据快速查询的核心技术方案。
想象一下,你走进一个拥有百万本书的图书馆,却不想一页页翻找,传统的线性查找就像是在书架前盲目漫步,而Hash存储结构则像是一位拥有“记忆地图”的管理员,你只需报出书名(Key),他就能瞬间指向书架的具体位置(Value),这种机制并非魔法,而是计算机科学中平衡空间与时间的经典艺术。
Hash存储结构的核心原理与工作机制
要理解Hash,首先要明白它如何打破线性搜索的瓶颈,在数组中查找一个元素,最坏情况需要遍历整个列表,效率随数据量线性下降,Hash结构引入了一个关键的中间层哈希函数(Hash Function)。
哈希函数的角色定位
哈希函数就像是一个精密的翻译官,它接收任意长度的输入(Key),经过一系列数学运算,输出一个固定长度的整数(Hash Code),这个整数的作用是将无序的数据映射到有限的存储空间中。
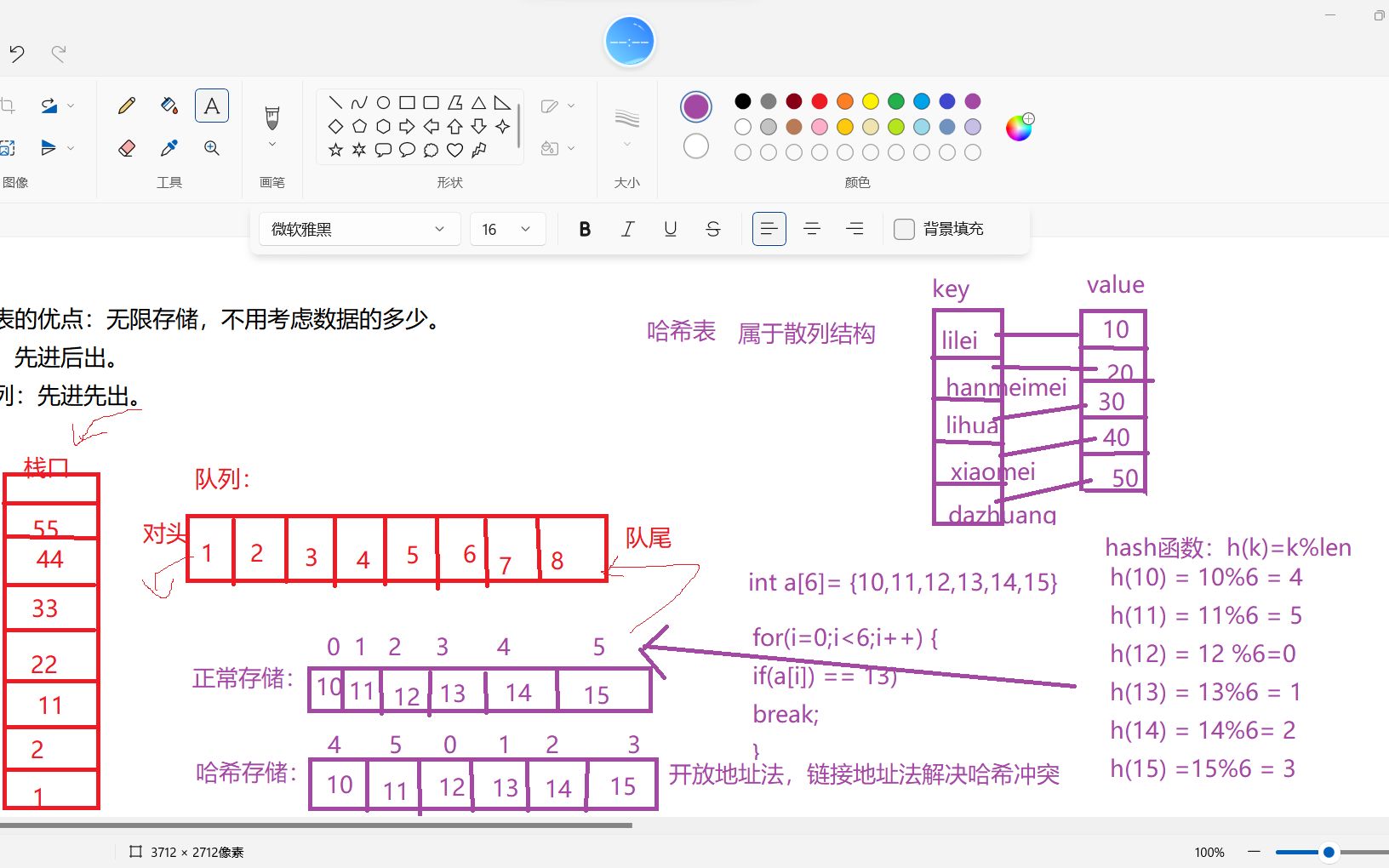
业内专家指出,一个优秀的哈希函数必须具备两个核心特征:确定性(相同的输入永远产生相同的输出)和均匀分布性(不同的输入尽可能均匀地分布在输出空间中),如果哈希函数设计糟糕,导致大量数据映射到同一个位置,整个系统的性能将急剧下降,这种现象被称为“哈希冲突”。
冲突解决策略对比
当两个不同的Key计算出相同的哈希值时,冲突不可避免,如何处理这些“撞车”事件,直接决定了存储结构的优劣,目前主流的方案主要有两种:
- 链地址法(Chaining):这是最直观的方法,数组的每个位置不再只存一个值,而是指向一个链表,当发生冲突时,新元素被添加到链表的头部或尾部,这种方法实现简单,且对动态插入支持良好,但缺点是链表过长时会退化为线性查找,且内存碎片较多。
- 开放寻址法(Open Addressing):这种方法不引入额外的链表结构,而是在数组内部寻找下一个可用的空位,常见的探测序列包括线性探测(检查下一个位置)、二次探测和双重哈希,它的优势在于数据紧凑,缓存友好,适合内存受限的场景,但删除操作复杂,且随着负载因子增加,性能波动较大。

Hash存储结构在实际开发中的应用场景
理解原理后,我们需要将其落地到具体的业务场景中,Hash结构并非万能钥匙,但在特定领域,它是无可替代的性能加速器。
缓存系统的数据底座
在Web开发中,Redis等内存数据库广泛采用类似Hash的结构来存储对象,存储用户信息时,可以将用户ID作为Key,将用户的姓名、年龄、邮箱等字段作为Field-Value对存储,这种结构不仅节省内存,还支持对单个字段的原子操作,如直接增加某个字段的值,而无需读取整个对象。
去重与快速查找
在处理日志数据或用户行为追踪时,去重是一个高频需求,利用HashSet(基于HashMap实现)可以在O(1)时间内判断一个元素是否已存在,相比使用List进行遍历比对,Hash结构在处理百万级数据时,速度差异可达数个数量级。
具体操作路径示例
假设你需要从海量IP中找出重复访问者,伪代码逻辑如下:
- 初始化一个空的HashSet。
- 遍历IP列表。
- 调用
set.add(ip),若返回false,说明该IP已存在,即为重复访问。 - 记录重复IP并继续处理。
这种模式在风控系统、反作弊算法中极为常见。
性能优化与负载因子管理
Hash结构并非配置好就一劳永逸,其性能高度依赖于内部状态的管理,负载因子(Load Factor)是衡量哈希表拥挤程度的关键指标。

负载因子的平衡艺术
负载因子定义为:已存储元素数量 / 哈希表总容量,当负载因子超过阈值(Java HashMap默认为0.75)时,哈希表会触发扩容机制,重新分配更大的数组并重新计算所有元素的哈希位置。
扩容是一个昂贵的操作,时间复杂度为O(N),预估数据量并初始化合适的容量,是提升性能的关键技巧,如果初始容量过小,频繁的扩容会导致CPU飙升;如果过大,则浪费内存空间。
避免哈希碰撞的进阶技巧
在分布式系统中,简单的哈希可能导致数据倾斜,使用hash(key) % N的方式分配数据到N个节点时,当节点数N变化时,大部分数据需要重新迁移。
行业共识认为,引入一致性哈希(Consistent Hashing)可以显著降低迁移成本,一致性哈希将哈希空间组织成一个环,节点和数据都映射到环上,当节点增加或删除时,只有受影响的那部分数据需要迁移,其余数据保持不变,这在CDN缓存和分布式数据库分片中被广泛采用。
常见误区与选型建议
许多开发者在选型时容易陷入误区,盲目追求高性能而忽视适用场景。
Hash vs 数据库索引
有人问,既然Hash查找这么快,为什么还要用MySQL的B+树索引?原因在于持久化和范围查询,Hash结构擅长精确匹配,但不支持范围查询(如age > 20),且数据存储在内存中,断电即失,B+树虽然查找速度稍慢(O(logN)),但支持范围扫描,且数据持久化在磁盘上,适合复杂查询和长期存储。
内存溢出的风险
Hash结构在内存中存储对象引用,对于大对象或海量小对象,内存开销不容忽视,特别是在Java等语言中,每个Entry对象都有额外的头部信息,在处理GB级数据时,需仔细评估内存占用,必要时采用分片存储或压缩算法。

安全性考量
标准的哈希算法如MD5、SHA-1已不再安全,易受碰撞攻击,在涉及安全校验的场景,应使用SHA-256或更高级的算法,为了防止哈希洪水攻击(Hash Flooding),现代框架通常会引入随机盐值(Salt)或混淆哈希函数,增加攻击者预测哈希值的难度。
Hash存储结构常见问题解答
Hash存储结构在大数据量下性能如何保障?
保障性能的核心在于控制负载因子和选择合适的扩容策略,当数据量达到千万级时,建议采用分片(Sharding)技术,将数据分散到多个独立的Hash实例中,使用无锁数据结构或分段锁(Segmented Lock)来减少并发竞争,对于超大规模数据,可考虑使用LSM-Tree等专门针对写优化的结构,它在处理高并发写入时表现优于传统B-Tree。
Hash存储结构与B+树索引的区别是什么?
两者在查找效率、数据有序性和持久化能力上有本质区别,Hash结构提供O(1)的平均查找速度,但不支持范围查询,数据无序,且通常基于内存,适合缓存和精确匹配场景,B+树提供O(logN)的查找速度,支持范围查询和排序,数据持久化在磁盘,适合关系型数据库的主键索引,若需同时支持精确查询和范围查询,可结合使用,如在数据库索引中保留B+树,在应用层使用Hash缓存热点数据。
如何解决Hash冲突带来的性能下降问题?
解决冲突需从哈希函数和数据结构两方面入手,优化哈希函数,确保输入数据的均匀分布,避免特定模式导致大量碰撞,选择高效的冲突解决策略,如链地址法配合红黑树(Java 8+ HashMap在链表过长时转为红黑树,将查找复杂度从O(N)降至O(logN)),动态调整哈希表大小,当负载因子超过阈值时及时扩容,保持哈希表的稀疏性,从而降低碰撞概率。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/454554.html









![[Jasmine行为驱动测试怎么做?Angular默认测试工具解析]](https://idctop.com/wp-content/uploads/ly-ai-image/2026/05/f60216674a0a0afc284ad0be78bc4c11-480x300.webp)
