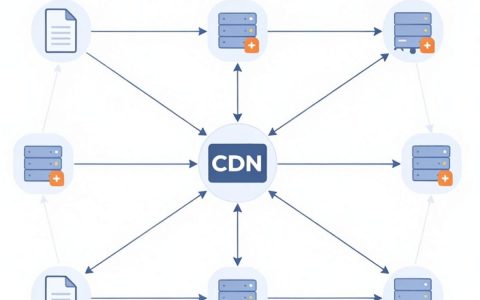
服务器数据自动备份到云盘是保障业务连续性的最低成本方案,通过配置定时任务将本地数据同步至云端对象存储,可彻底杜绝因硬件故障或人为误操作导致的数据丢失风险。
在数字化转型的深水区,数据被视为企业的核心资产,许多中小企业的IT负责人仍停留在“硬盘坏了再换”的传统思维中,本地存储的物理脆弱性极高,雷击、火灾、硬盘坏道甚至勒索病毒,都能在瞬间让数年的积累化为乌有,将服务器自动备份到云盘,并非简单的文件拷贝,而是一套包含数据加密、版本控制、异地容灾的系统工程,业内专家指出,构建完善的备份体系是企业IT架构中最容易被忽视,却最具性价比的防御手段。
为什么必须选择云端自动备份而非本地硬盘
本地备份(Local Backup)与云备份(Cloud Backup)的本质区别在于风险隔离,本地备份如同“把鸡蛋放在同一个篮子里”,一旦服务器机房发生物理灾害,备份数据同样受损,云盘备份则利用了分布式存储架构,数据在传输和存储过程中会被拆分并冗余存储在不同物理位置的服务器上。
成本对比与资源释放
对于初创团队或中小企业而言,自建NAS(网络附属存储)或购买大容量企业级硬盘需要一次性投入数千甚至上万元,且后续还需承担电费、散热和维护人力成本,相比之下,云对象存储(如阿里云OSS、腾讯云COS、华为云OBS等)采用按量付费模式。
| 对比维度 | 本地硬盘/NAS方案 | 云盘自动备份方案 |
|---|---|---|
| 初期投入 | 高(硬件采购、机架租赁) | 极低(仅需带宽和存储费) |
| 维护成本 | 高(需专人监控硬件健康) | 低(云端自动冗余,无需运维) |
| 数据安全性 |
低(易受物理灾害影响) | 高(多地容灾,版本控制) |
| 扩展灵活性 | 差(扩容需停机或采购新设备) | 好(按需扩容,秒级生效) |

据统计,采用云备份方案的企业,其IT基础设施运维成本平均降低了40%,更重要的是,它释放了本地服务器资源,让CPU和内存专注于业务逻辑处理,而非数据搬运。
自动化带来的效率革命
手动备份是数据丢失的高发区,员工离职、忘记执行脚本、备份文件覆盖等问题屡见不鲜,自动备份的核心价值在于“无人值守”,通过配置定时任务,数据可以在业务低峰期(如凌晨2点)自动执行,无需人工干预,这种确定性消除了人为疏忽带来的不确定性。
如何搭建高可用的自动备份体系
搭建自动备份系统并非难事,关键在于选择正确的工具和配置策略,以下以Linux服务器为例,提供一套经过验证的实操路径。
第一步:选择存储后端与配置权限
目前主流的云服务提供商均提供标准的S3兼容接口或专用的SDK,以阿里云OSS为例,你需要创建一个Bucket(存储桶),并获取AccessKey ID和AccessKey Secret。
- 安全原则:切勿将AccessKey硬编码在脚本中,建议使用环境变量或专门的密钥管理服务(KMS)来存储凭证。
- 权限最小化:为备份账号分配只写权限,禁止删除和读取其他无关数据,防止误删或恶意篡改。
第二步:编写自动化同步脚本
推荐使用rclone或aws-cli等成熟工具进行数据同步。rclone支持超过40种云存储后端,配置简单且支持断点续传。
-
安装工具:
apt-get install rclone
-
配置远程存储:
运行rclone config,选择对应的云存储类型,输入AccessKey等信息。 -
编写同步脚本

:
创建一个名为backup.sh的脚本,内容如下:#!/bin/bash # 定义备份源和目标 SOURCE_DIR="/var/www/html/data" REMOTE_DEST="my-oss-bucket/backup/$(date +%Y-%m-%d)" # 执行同步,仅上传新增或修改的文件 rclone sync "$SOURCE_DIR" "$REMOTE_DEST" --progress --log-file=/var/log/backup.log # 检查退出状态,若失败则发送告警 if [ $? -ne 0 ]; then echo "Backup failed on $(date)" | mail -s "Backup Alert" admin@company.com fi

第三步:配置定时任务(Crontab)
使用Linux自带的crontab服务实现定时执行。
- 每日全量备份:
0 2 /path/to/backup.sh(每天凌晨2点执行) - 每小时增量备份:
0 /path/to/incremental_backup.sh
建议设置保留策略,云存储虽然便宜,但长期积累大量无用历史版本也会产生费用,可在脚本中加入清理逻辑,删除超过30天或90天的旧备份文件,平衡成本与安全。
常见误区与避坑指南
在实施“服务器数据备份到云端”的过程中,许多用户容易陷入一些认知误区,导致备份失效或成本失控。
备份等于复制
简单的cp命令或rsync虽然能复制文件,但无法处理数据库的一致性,如果在MySQL运行过程中直接复制数据文件,恢复时极可能出现数据损坏。
- 正确做法:对于数据库,应先使用
mysqldump或xtrabackup进行逻辑或物理快照导出,再对导出的SQL文件或快照目录进行云同步,确保备份时刻数据的一致性。
忽视传输加密
数据在公网传输过程中可能被窃听,虽然HTTPS/TLS协议提供了传输层加密,但为了双重保险,建议在客户端对数据进行加密后再上传。
- 实操建议:使用
gpg或openssl对备份文件进行加密,上传密文,即使云盘账号泄露,攻击者也无法解密查看敏感数据。
缺乏恢复演练
备份的最终目的是恢复,如果没有经过验证的恢复流程,备份文件只是一堆无用的数据碎片。

- 行业共识认为:至少每季度进行一次恢复演练,在一个隔离的环境中,尝试从云盘下载备份并还原业务,记录所需时间和遇到的障碍,只有经过验证的备份,才是可靠的备份。
Q&A:关于自动备份的关键疑问
服务器自动备份到云盘需要多少费用
费用主要由存储容量、请求次数和下行流量组成,对于大多数中小企业,每月数据增量在几GB到几十GB之间,使用低频访问存储(IA)或归档存储类型,月成本通常控制在几十元人民币以内,存储100GB数据,若选择标准存储,年费用可能低于100元;若选择归档存储,成本更低,但取回数据时需支付额外的请求费和流量费,具体价格需参照各云厂商当期的定价表,通常远低于自建硬件的折旧与维护成本。
自动备份到云盘是否安全
云服务商在物理安全和网络安全层面拥有远超普通企业的能力,主流云厂商均通过ISO 27001、等保三级等权威认证,数据在云端采用多副本冗余存储,即使单个数据中心损毁,数据依然可用,通过开启“版本控制”功能,可以防止文件被误删或覆盖,保留历史版本供回溯,只要妥善保管好AccessKey等凭证,并启用MFA(多因素认证),云备份的安全性远高于本地硬盘。
如何确保备份数据不被勒索病毒加密
勒索病毒通常会加密本地文件并尝试删除备份,为应对这一威胁,建议采用“3-2-1”备份原则的变体:至少保留3份数据副本,使用2种不同介质(本地+云端),其中1份异地存储,在云端,利用云盘的“不可变存储”或“WORM(写入一次,读取多次)”特性,确保备份文件在设定时间内无法被修改或删除,备份账号应与应用账号隔离,避免病毒通过应用权限直接访问备份路径。
做好数据备份,不是为了解决问题,而是为了在问题发生时拥有重来的机会,将服务器自动备份到云盘,是用极小的成本换取业务连续性的最佳实践。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/458433.html