博客MySQL数据库设计的核心在于通过规范化表结构减少数据冗余,并利用索引优化查询性能,同时结合读写分离架构应对高并发场景,这是构建稳定博客系统的基石。
设计一个博客数据库,不仅仅是画几张图,而是为未来的内容增长预留空间,很多新手开发者在初期往往只建一张大表,把所有字段堆在一起,这种做法在数据量小时尚可运行,一旦文章数量突破万级,查询速度就会断崖式下跌,业内专家指出,合理的范式设计能显著降低存储成本并提升维护效率,我们需要从核心实体出发,理清文章、用户、分类和标签之间的关系,构建一个既符合第三范式又兼顾查询效率的模型。
博客mysql数据库设计基础与实体关系梳理
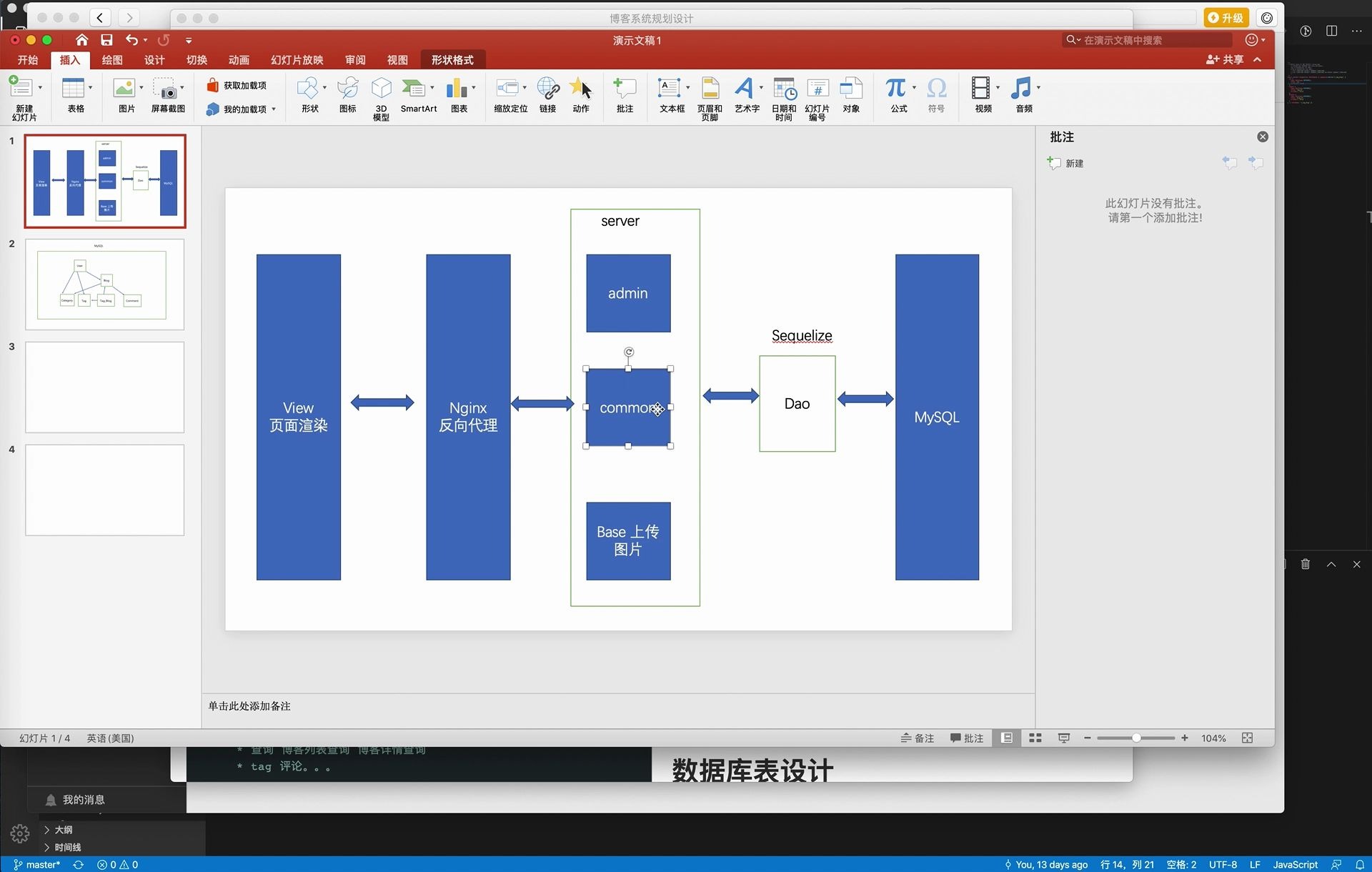
在动手创建表之前,必须先明确博客系统的核心业务逻辑,一个标准的博客系统通常包含文章、用户、分类、标签和评论这五大核心模块,理清它们之间的关联是数据库设计的起点。
核心表结构设计策略
文章表是博客的心脏,它需要承载最丰富的信息,除了基本的标题、内容、发布时间外,还需要考虑SEO友好的字段,如slug(用于生成URL)和状态(草稿、发布、隐藏)。
用户表与权限控制
用户表不仅要存储账号密码,更要预留扩展字段,密码建议使用bcrypt等算法加密存储,严禁明文保存,角色字段(管理员、编辑、访客)应独立出来,以便后续扩展权限体系。
分类与标签的关联逻辑

分类通常是层级结构,而标签则是扁平化的,这里存在一个常见的误区:是否将标签直接作为字段存入文章表?答案是否定的,标签具有多对多关系,必须通过中间表来实现。
博客mysql数据库设计索引优化与性能提升
数据库设计完成后,性能优化是决定系统生死的关键,索引是提升查询速度的利器,但滥用索引同样会带来写入性能的下降。
索引选择的最佳实践
在博客场景中,高频查询通常集中在按时间排序、按分类筛选和全文搜索,针对这些场景,索引策略需要精细化设计。
- 复合索引的使用:对于“按分类查看最新文章”这类查询,建议在分类ID和发布时间上建立复合索引,在MySQL中创建索引时,顺序至关重要,通常将区分度高的字段放在前面。
- 全文索引的应用:MySQL自带的全文索引适合小规模数据的简单搜索,当数据量达到百万级时,建议引入Elasticsearch等专业搜索引擎,数据库仅作为数据源。
- 避免过度索引:每个索引都会占用磁盘空间并减慢INSERT、UPDATE和DELETE的速度,通常认为,单表索引数量不超过5个为宜,具体需根据实际查询语句分析。
查询语句的规范化要求
很多性能问题并非来自表结构,而是来自糟糕的SQL语句,避免使用SELECT ,只查询需要的字段,对于分页查询,当页码很深时,传统的LIMIT offset, size会导致数据库扫描大量无用数据,此时应采用“延迟关联”或“基于游标”的分页方式,大幅提升深层分页的效率。

博客mysql数据库设计扩展性与高可用架构
随着博客流量的增长,单机MySQL往往成为瓶颈,架构的扩展性显得尤为重要。
读写分离的实施路径
博客系统具有典型的“读多写少”特征,通过配置主从复制,可以将写操作集中在主库,读操作分散到多个从库,这种架构能显著提升系统的并发处理能力。
主从同步机制
MySQL的主从同步基于二进制日志(binlog),主库将数据变更写入binlog,从库通过I/O线程拉取日志,并由SQL线程重放,需要注意的是,同步存在延迟,对于强一致性要求高的场景(如用户登录验证),必须强制查询主库。
分库分表的考量
当单表数据超过千万级时,索引效率会下降,备份和恢复时间也会变长,此时需要考虑分库分表,常见的策略包括按用户ID哈希分片或按时间范围垂直拆分,将历史归档文章迁移至冷存储库,主库仅保留近期活跃数据。
博客mysql数据库设计安全备份与灾难恢复
数据是博客的核心资产,安全备份是不可忽视的一环。
备份策略的制定
建议采用全量备份与增量备份相结合的策略,全量备份每周执行一次,增量备份每天执行,对于关键数据,还可以开启实时二进制日志备份,以实现时间点恢复(PITR)。
数据恢复演练
备份不等于安全,定期恢复演练才能验证备份文件的有效性,建议在测试环境中定期尝试从备份中恢复数据,确保在紧急情况下能够快速恢复业务。

常见问题解答
博客mysql数据库设计时如何选择字符集?
推荐统一使用UTF8MB4字符集,虽然UTF8也能存储中文,但UTF8MB4支持完整的Unicode字符集,包括emoji表情和多语言字符,兼容性更好,且现代MySQL版本对UTF8MB4的性能优化已非常成熟,几乎无性能损耗。
博客mysql数据库设计如何防止SQL注入?
最根本的解决方法是使用预处理语句(Prepared Statements),在代码层面,不要直接拼接用户输入到SQL字符串中,预处理语句会将SQL结构与数据分离,由数据库驱动负责转义和处理,从而从根本上杜绝注入风险。
博客mysql数据库设计初期是否需要分库分表?
初期不建议分库分表,分库分表会极大增加系统复杂度,引入分布式事务、数据迁移等难题,绝大多数博客系统通过合理的索引优化和读写分离,即可支撑千万级数据量的日常运营,只有当业务规模确实超出单机极限时,再考虑分库分表,遵循“按需演进”的原则。
数据库设计是一个动态演进的过程,初期追求简洁和规范性,中期关注索引和查询效率,后期侧重架构扩展和高可用,没有最好的设计,只有最适合当前阶段的设计,通过扎实的基础建模和持续的优化迭代,才能构建出既稳定又高效的博客数据底座。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/460589.html