App压力测试入门需先明确业务场景,Hadoop压力测试工具主要通过Apache官方渠道或GitHub开源社区获取,推荐直接使用Hadoop自带的PerfTune或HDFS IO Benchmark脚本进行基础压测。
在进行应用性能评估时,许多开发者容易混淆Web应用压测与大数据平台压测的逻辑,App压力测试关注的是高并发下的响应时间与吞吐量,而Hadoop作为分布式计算框架,其压力测试核心在于验证集群在海量数据读写下的稳定性与资源调度效率,这两者虽然都叫“压测”,但底层逻辑截然不同,理解这一区别,是选择正确工具和制定测试方案的第一步。
App压力测试的核心逻辑与工具选型
App压力测试并非简单的“把服务器跑崩”,而是为了模拟真实用户行为,发现系统在极限状态下的瓶颈,业内专家指出,成功的压测必须基于真实的业务模型,而非凭空捏造流量。
明确测试目标与场景
在动手之前,需要回答三个问题:我们要测什么?模拟多少人?持续多久?
- 负载测试:确定系统的最大处理能力,找到性能拐点。
- 压力测试:系统进入超负荷状态,观察其恢复能力或崩溃边界。
- 稳定性测试:长时间运行,检测内存泄漏或资源累积问题。
主流工具对比
选择工具时,需考虑协议支持、脚本编写难度及结果可视化能力。
| 工具名称 | 适用协议 | 特点 | 适用场景 |
|---|---|---|---|
| JMeter | HTTP, JDBC, TCP | 图形化界面,插件丰富,社区活跃 | Web App, API接口测试 |
| LoadRunner | 多种协议 | 功能强大,商业软件,报告详尽 | 企业级复杂系统压测 |
|
Gatling | HTTP, WebSocket | 基于Scala,高并发性能好,代码即脚本 | 高性能API压测 |
| Wrk | HTTP | 命令行工具,极简,极高并发 | 快速验证Nginx或网关性能 |

对于大多数App后端接口测试,JMeter因其低门槛和丰富的中文文档,仍是首选,但需注意,JMeter在单机模拟万级并发时资源消耗巨大,必要时需采用分布式压测架构。
Hadoop压力测试工具如何获取?
Hadoop生态庞大,没有单一的“Hadoop压测软件”,而是由一系列内置脚本和开源项目组成,获取这些工具并不复杂,关键在于理解它们的作用。
官方内置基准测试工具
Apache Hadoop发行版中自带了用于测试HDFS和MapReduce性能的工具,这是最权威且无需额外安装的来源。
- HDFS IO Benchmark:用于测试HDFS的读写性能。
- 获取路径:通常位于
$HADOOP_HOME/share/hadoop/mapreduce/目录下。 - 核心命令:
hadoop jar hadoop-mapreduce-client-jobclient-.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB - 作用:生成指定数量和大小的文件,测试写入速度;随后读取这些文件,测试读取速度。
- 获取路径:通常位于
- TeraSort:用于测试MapReduce框架的排序性能。
- 获取路径:同样位于
$HADOOP_HOME/share/hadoop/mapreduce/。 - 核心命令:
hadoop jar hadoop-mapreduce-client-jobclient-.jar terasort /input /output - 作用:通过生成随机数据、排序、验证三个步骤,全面评估集群的计算和Shuffle能力。
- 获取路径:同样位于
第三方开源压测框架
如果需要更精细化的控制或模拟特定业务负载,可以考虑以下开源项目。
- Hadoop PerfTune:这是一个专门用于调优和压测Hadoop集群的工具,它可以通过脚本自动化执行TeraSort和IO测试,并生成详细的性能报告。
- 获取方式:访问Apache Hadoop官方文档页面或GitHub上的Hadoop贡献者仓库。

- YCSB (Yahoo! Cloud Serving Benchmark):虽然YCSB主要面向NoSQL数据库,但通过配置HBase或Cassandra后端,它可以间接反映Hadoop生态中存储层的性能。
- 获取方式:从GitHub官方仓库克隆代码,编译后使用。

获取渠道的安全性与版本匹配
在寻找“Hadoop压力测试工具”时,务必注意版本兼容性,Hadoop 2.x、3.x乃至CDH、HDP等不同发行版,其内置脚本的路径和参数可能存在差异。
- 推荐渠道:Apache Hadoop官网(apache.org)、GitHub官方组织仓库。
- 避坑指南:避免从第三方不明网站下载所谓的“破解版”或“增强版”压测工具,这些往往夹带恶意代码或包含过时库,可能导致集群数据污染。
实操步骤:如何执行一次标准的Hadoop压测
理论归理论,落地执行才是关键,以下以HDFS IO Benchmark为例,展示标准操作流程。
环境准备
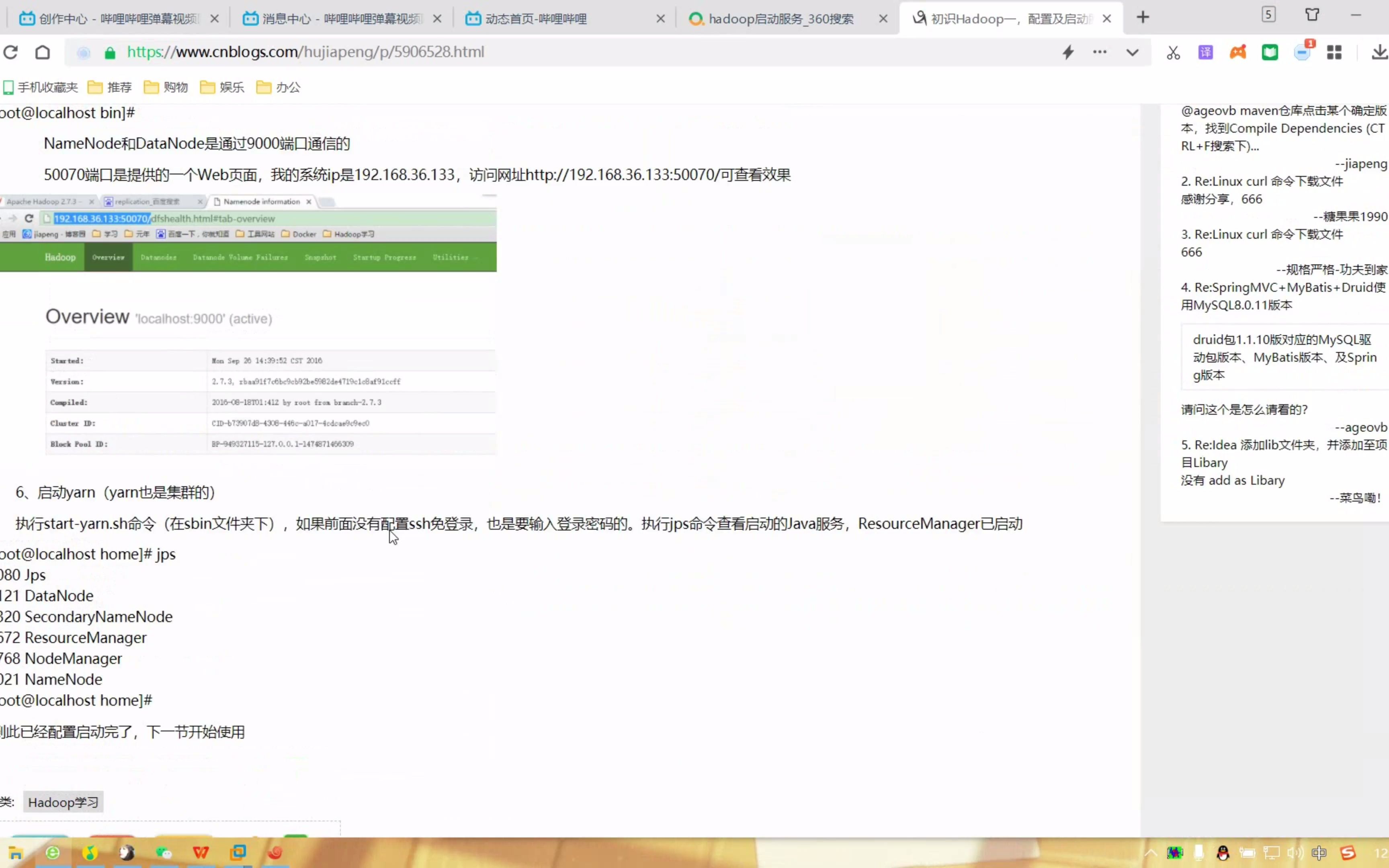
- 确保Hadoop集群处于健康状态,NameNode和DataNode均正常运行。
- 清理测试目录,避免历史数据干扰测试结果。
- 调整JVM参数,确保测试进程有足够的内存空间。
执行写入测试
使用以下命令启动写入测试,生成10个文件,每个文件128MB:hadoop jar $HADOOP_HOME/hadoop-mapreduce-client-jobclient-.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
观察控制台输出,关注Bytes Written和Average IO rate两个指标。
执行读取测试
写入完成后,立即执行读取测试:hadoop jar $HADOOP_HOME/hadoop-mapreduce-client-jobclient-.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
读取测试能反映集群在数据分发和磁盘I/O方面的综合性能。
结果清理
测试结束后,务必清理生成的测试数据,释放磁盘空间:hadoop jar $HADOOP_HOME/hadoop-mapreduce-client-jobclient-.jar TestDFSIO -clean
常见误区与优化建议

在实施过程中,许多团队容易陷入一些误区,导致测试结果失真。
忽视小文件问题
Hadoop擅长处理大文件,对小文件支持较差,如果压测场景涉及大量小文件,单纯使用TeraSort无法反映真实问题,建议结合Hive或Spark进行小文件合并测试。
忽略网络带宽
Hadoop是网络密集型应用,如果机架内交换机带宽不足,即使磁盘I/O再快,整体性能也会受限,在压测前,需确认网络拓扑和带宽配置。
优化建议
- 合理配置副本数:测试环境中可适当减少副本数(如1副本)以聚焦于读写性能,生产环境则需保持默认(3副本)。
- 监控资源使用:结合Prometheus+Grafana监控CPU、内存、磁盘I/O和网络流量,定位瓶颈所在。
- 多次取平均值:单次测试可能存在波动,建议运行3-5次,取平均值作为最终参考。
Q&A:关于Hadoop压力测试的常见疑问
Hadoop压力测试工具如何获取?
Hadoop压力测试工具主要来源于Apache Hadoop官方发行版自带的TestDFSIO和TeraSort jar包,位于share/hadoop/mapreduce目录下;也可从GitHub获取PerfTune等第三方开源脚本,无需额外购买,直接下载对应版本的Hadoop安装包即可使用。
App压力测试与Hadoop压测有什么区别?
App压力测试主要针对Web应用或API接口,关注HTTP请求的响应时间、并发用户数和错误率,常用JMeter等工具;Hadoop压测则针对分布式存储和计算框架,关注HDFS读写吞吐量、MapReduce任务执行效率及集群资源调度能力,常用内置基准测试脚本,两者测试对象、协议和指标体系完全不同。
如何判断Hadoop集群性能是否达标?
没有统一的绝对标准,需结合集群硬件配置和业务需求综合判断,通常参考指标包括:HDFS写入速度(MB/s)、读取速度(MB/s)、TeraSort完成时间(分钟),业内共识认为,若写入速度低于磁盘理论带宽的30%,或TeraSort时间随数据量线性增长而非对数增长,则可能存在配置或硬件瓶颈,需进一步优化。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/328341.html