HTML5读取数据的核心在于利用File API、Fetch API及Web Storage机制,前端直接操作本地文件或通过异步请求获取后端数据,无需依赖传统插件即可实现高效、安全的数据交互。
在2026年的Web开发语境下,前端工程师早已不再满足于简单的页面展示,而是追求极致的数据交互体验,过去那种依赖Flash或ActiveX插件读取本地文件的时代彻底终结,取而代之的是基于HTML5标准的一系列原生API,这些技术不仅提升了性能,更在安全性上建立了新的壁垒,对于开发者而言,理解如何优雅地读取数据,是构建现代Web应用的基础。
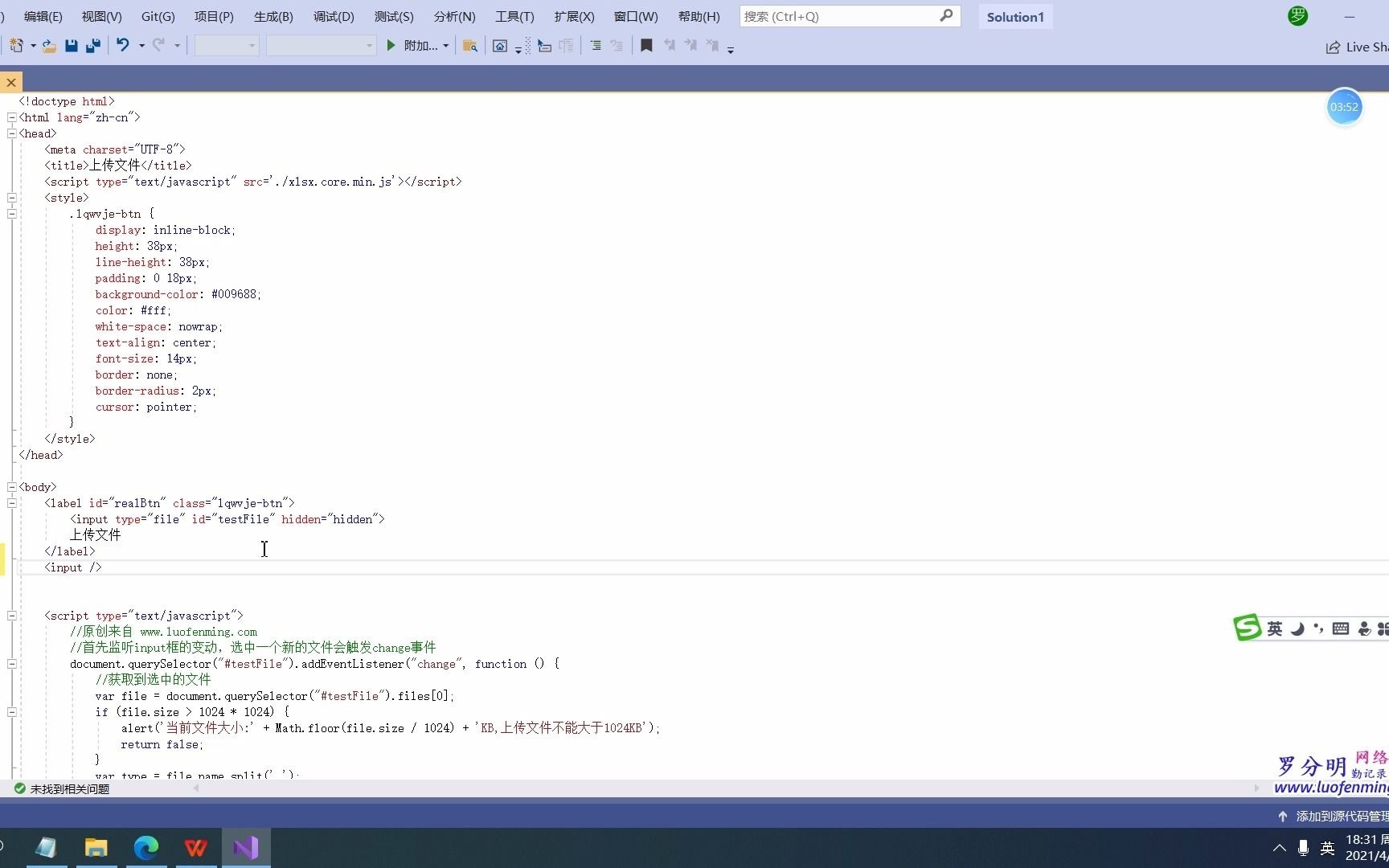
本地文件读取的实战路径与File API应用
本地文件读取是前端开发中最常见的场景之一,无论是用户上传头像、导入Excel报表,还是读取配置文件,都离不开File API,这一套API允许Web应用程序安全地访问用户选择的文件,但前提是必须经过用户的明确授权。
input type=file的核心操作逻辑
使用元素是读取本地文件最基础也最可靠的方式,浏览器会自动弹出一个文件选择对话框,用户选中文件后,JavaScript可以通过监听change事件来获取FileList对象。
具体操作步骤如下:
- 创建文件输入控件,设置accept属性以限制文件类型,例如图片格式。
- 监听input元素的change事件。
- 在事件回调中,通过event.target.files获取文件列表。
- 使用FileReader对象读取文件内容。
这里有一个关键的技术细节:FileReader是异步的,这意味着你不能期望在调用readAsText后立即获得结果,必须通过绑定onload事件来接收数据。
多文件读取与性能优化
当处理大体积文件或多个文件时,内存管理变得至关重要,业内专家指出,一次性加载超过50MB的文件可能导致浏览器主线程阻塞,引发页面卡顿,对于大文件,建议采用分块读取(Slice)的方式,或者使用Web Worker将读取操作移至后台线程。
对于需要预览图片的场景,URL.createObjectURL()方法比FileReader更为高效,它生成一个指向内存中文件的临时URL,避免了将文件内容转换为Base64字符串所带来的巨大内存开销。

网络数据获取:Fetch API与现代异步编程
除了本地文件,从服务器获取数据是Web应用的核心功能,XMLHttpRequest曾是主流,但Fetch API的出现彻底改变了这一局面,它基于Promise,语法更简洁,且与Service Worker等现代Web技术兼容性更好。
GET与POST请求的最佳实践
在进行数据请求时,区分GET和POST的使用场景至关重要,GET请求用于获取资源,参数通常附加在URL后;POST请求用于提交数据,载荷位于请求体中。
使用Fetch进行GET请求获取JSON数据时,标准流程包括:
- 调用fetch()方法传入URL。
- 检查response.ok属性,确保请求成功。
- 调用response.json()解析响应体。
- 处理解析后的数据对象。
值得注意的是,Fetch默认不会发送Cookie,除非显式配置credentials属性,在涉及用户会话管理时,务必设置credentials: ‘include’或’same-origin’,否则可能导致后端无法识别用户身份,从而返回401未授权错误。
错误处理与网络异常应对
网络环境的不确定性要求代码具备强大的容错能力,Fetch API的一个常见误区是:网络错误(如DNS解析失败、服务器宕机)不会抛出异常,而是返回一个rejected的Promise,必须在.catch()块中统一处理网络异常,而不是仅仅依赖HTTP状态码。
据统计,多数情况下,前端应用的性能瓶颈并非来自代码逻辑,而是来自未优化的网络请求,通过合并请求、使用缓存策略以及设置合理的超时时间,可以显著提升用户体验。
浏览器本地存储:Web Storage与IndexedDB
当数据不需要实时同步到服务器,或者需要离线访问时,浏览器本地存储成为理想选择,HTML5提供了两种主要的本地存储机制:Web Storage和IndexedDB。
LocalStorage与SessionStorage的区别

Web Storage包括localStorage和sessionStorage,它们都基于键值对存储,最大容量通常为5MB。
- localStorage:数据持久化存储,除非手动删除,否则关闭浏览器后数据依然存在,适合存储用户偏好设置、登录状态等。
- sessionStorage:数据仅在当前会话有效,关闭标签页或浏览器后数据清除,适合存储临时表单数据或单次操作流程的状态。
两者在API上完全一致,均使用setItem()、getItem()和removeItem()方法,但需要注意的是,它们只能存储字符串类型,如果存储对象或数组,必须先通过JSON.stringify()序列化,读取时再通过JSON.parse()反序列化。
复杂数据结构的选择:IndexedDB
当需要存储大量结构化数据,或者需要索引查询时,Web Storage显得力不从心,IndexedDB是更好的选择,它是一个事务型的NoSQL数据库,支持存储二进制数据(如Blob、ArrayBuffer),容量限制通常只受用户磁盘空间限制。
使用IndexedDB读取数据涉及以下步骤:
- 打开数据库连接。
- 创建或打开对象存储(Object Store)。
- 创建事务并指定读写模式。
- 使用游标(Cursor)或索引获取数据。
虽然IndexedDB的API较为繁琐,但现代框架如idb或localForage封装了底层细节,使得开发者可以像操作localStorage一样简单地使用它。
数据读取的安全边界与隐私合规
随着GDPR、CCPA等隐私法规的严格执行,前端数据读取必须遵循最小必要原则,浏览器沙箱机制确保了Web应用无法随意访问用户文件系统,这是Web安全的基础。
同源策略与跨域资源共享
同源策略限制了文档或脚本如何与来自另一个源的资源进行交互,当从不同域名、协议或端口读取数据时,浏览器会拦截请求,除非服务器通过CORS(跨域资源共享)头明确允许。
在开发环境中,常见的解决方案是使用代理服务器转发请求,或者在后端配置Access-Control-Allow-Origin头,对于生产环境,务必仔细审查CORS配置,避免设置通配符,以免泄露敏感数据。

敏感数据的本地存储风险
尽管Web Storage方便易用,但它并不适合存储敏感信息,如密码、支付令牌等,因为本地存储的数据可以被同一域名下的任何脚本访问,包括恶意脚本(XSS攻击),对于敏感数据,应使用HttpOnly Cookie或更安全的加密存储方案。
业内共识认为,前端安全的核心在于防御而非信任,所有来自用户输入或外部接口的数据,都必须经过严格的验证和 sanitization(净化),防止注入攻击。
HTML5读取数据常见问题解答
HTML5读取本地大文件时如何避免页面卡顿?
采用分块读取策略,利用File对象的slice方法将大文件分割成小块,逐块读取并处理,使用requestAnimationFrame或Web Worker将计算密集型任务移至后台,确保主线程流畅响应用户交互。
Fetch API与XMLHttpRequest的主要区别是什么?
Fetch基于Promise,支持async/await语法,代码更简洁且易于维护;XMLHttpRequest基于回调,代码嵌套深,难以处理复杂逻辑,Fetch默认不携带Cookie,需手动配置;而XHR默认携带,Fetch在错误处理上更规范,网络错误会返回rejected Promise,而XHR通常通过onerror事件处理。
如何判断浏览器是否支持特定的数据读取API?
使用特性检测(Feature Detection)而非浏览器嗅探,检查window.FileReader是否存在来判断是否支持本地文件读取;检查window.fetch是否存在来判断是否支持Fetch API,对于较新的API,可以使用Modernizr库或简单的if条件判断,确保在旧浏览器中提供降级方案。
掌握HTML5数据读取技术,不仅是掌握几个API那么简单,更是理解Web安全、性能优化和用户隐私保护的综合体现,从本地文件到网络请求,再到本地存储,每一个环节都关乎应用的稳定性和用户体验,随着Web标准的不断演进,前端数据交互将更加高效、安全且智能化。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/361625.html