2026年AI大模型书籍的选择核心在于“场景匹配”与“技术深度”的平衡,初学者应侧重原理与提示工程,开发者需深入架构与微调实战,企业决策者则关注合规与落地成本。
如今翻开任何一本关于AI大模型的书籍,你都会发现内容迭代的速度远超传统编程领域,从2026年的“Hello World”式入门,到2026年的“行业专属模型部署”,读者的需求已经发生了根本性转变,很多人还在纠结买哪本,其实答案取决于你当下的身份和痛点,是刚接触AI想快速上手,还是已经具备基础想要构建私有知识库?不同阶段,对应的“最佳书籍”截然不同。

入门必读:构建认知框架与提示工程实战
对于非技术背景的产品经理、运营人员或初级开发者,直接啃底层代码无异于天书,这一类读者最需要的是建立对大模型“黑盒”机制的直观理解,并掌握与AI高效对话的技巧。
从原理到应用的平滑过渡
市面上很多书一上来就讲Transformer架构,这对初学者极不友好,优质的入门书籍通常会用类比的方式解释注意力机制和概率预测,将大模型比作一个读过互联网所有书籍的超级实习生,它不是“知道”答案,而是通过上下文预测下一个最可能的字,这种认知模型的建立,比记住几个API调用更重要。
业内专家指出,掌握提示工程(Prompt Engineering)是入门的第一道门槛,好的书籍不会只罗列咒语式的Prompt,而是会拆解其背后的逻辑:角色设定、上下文约束、思维链(Chain of Thought)引导。
实操建议:如何筛选入门书
- 看案例时效性:确保书中案例基于2026年后的主流模型(如Llama 3、Qwen 2.5等),而非过时的GPT-3.5旧版逻辑。
- 看互动性:优选附带在线 Playground 或 Jupyter Notebook 练习环境的书籍,边学边练。
- 看语言风格:避免学术腔,选择那些能用大白话解释复杂概念的作者。

进阶深造:模型微调、RAG架构与本地部署
当你不再满足于让AI写文案,而是希望它成为你的垂直领域专家时,就需要深入技术底层,这一阶段的核心关键词是:微调(Fine-tuning)和检索增强生成(RAG)。
微调与RAG:两条不同的技术路线
很多开发者容易混淆微调与RAG,书籍必须清晰界定两者的适用边界,微调适合注入特定风格、专业知识或改变模型行为模式,但成本较高且存在灾难性遗忘风险;RAG则通过外挂知识库解决事实性错误和时效性问题,更适合动态数据场景。
本地部署与边缘计算趋势
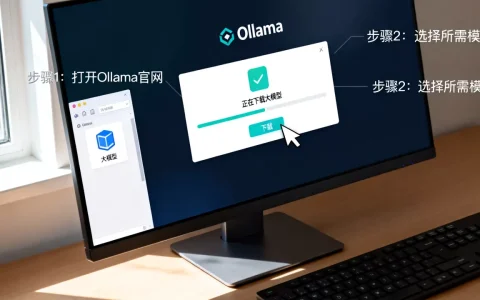
随着硬件性能提升,2026年的趋势是“小模型大能力”,关于本地部署的书籍需要涵盖 Ollama、vLLM 等主流推理框架的使用,特别是针对国内用户,如何在国内服务器上顺利下载并运行开源模型(如 Qwen、Baichuan 系列),是极具价值的实操内容。
- 环境配置:详细列出 CUDA 版本、驱动要求及显存最低配置。
- 量化技术:讲解 INT4、INT8 量化对精度的影响及具体操作步骤。
- 容器化部署:使用 Docker 封装模型服务,实现一键启动。
企业落地:成本控制、合规安全与行业案例
对于CTO、技术总监或企业决策者,技术细节并非首要关注点,他们更关心ROI(投资回报率)、数据安全和法律合规,这类书籍往往较少,但价值极高。
私有化部署的成本核算
企业选择自建模型还是调用API,取决于数据敏感度和调用频率,书籍应提供详细的成本对比模型,包括硬件折旧、电力消耗、运维人力以及API调用费用。
据工信部相关数据显示,近年来企业在AI基础设施上的投入占比逐年上升,但效能比却参差不齐,科学的架构设计至关重要。
合规与安全红线
2026年的监管环境更加成熟,书籍必须涵盖《生成式人工智能服务管理暂行办法》等法规的解读,以及如何在技术层面实现内容过滤、水印添加和用户隐私保护。

- 数据脱敏:在数据进入模型前,如何通过正则或NLP技术识别并隐藏PII(个人身份信息)。
- 幻觉抑制:通过多路召回和交叉验证机制,降低模型胡编乱造的概率。
- 审计日志:建立完整的Prompt和Response记录体系,以便追溯责任。
2026年AI书籍选购指南:避坑与推荐逻辑
面对琳琅满目的书目,如何快速做出选择?以下对比表格可助你理清思路。
| 读者类型 | 核心痛点 | 推荐关注点 | 避坑指南 |
|---|---|---|---|
| 小白/转行者 | 听不懂术语,怕学不会 | 概念图解、生活化案例、提示词模板 | 避开纯代码堆砌、无环境配置的教程 |
| 初级开发者 | 想跑通Demo,但不懂原理 | 架构解析、API调用、简单微调 | 避开版本过旧、依赖库已废弃的内容 |
| 高级架构师 | 解决高并发、低延迟问题 | 分布式训练、模型压缩、推理优化 | 避开理论脱离实际、缺乏压测数据的内容 |
| 企业决策者 | 担心合规与成本 | 行业案例、ROI分析、合规指南 | 避开纯技术视角、忽视业务场景的内容 |

地域与语言差异的影响
值得注意的是,英文原版书籍在技术前沿性上通常领先半年到一年,但可能存在“水土不服”,如依赖国外云服务或忽略国内网络环境,中文书籍则在本地化部署、中文语料处理及合规解读上更具优势,建议结合两者,英文书看前沿理念,中文书看落地实操。
对于预算有限的读者,许多开源社区的文档和论文翻译也是极佳的学习资源,但系统性不如书籍,若追求系统学习,购买正版书籍并附带代码仓库访问权限,是性价比最高的选择。
常见问题解答(Q&A)
AI大模型书籍推荐中,初学者应该先学Python还是先学Prompt?
建议并行学习,Python是操作AI的工具,Prompt是与AI沟通的语言,如果目标是快速产出内容,优先掌握Prompt技巧,因为无需编程即可调用API;如果目标是开发应用,则需同步学习Python基础及Requests库调用API的方法,两者结合,才能在2026年的技术环境中具备竞争力。
市面上关于AI大模型的书籍,哪类价格更合理且值得购买?
技术类书籍价格通常在50-100元之间,属于正常区间,对于包含独家数据集、私有模型权重或长期在线课程服务的书籍,价格可能高达数百元,建议优先选择附带GitHub代码仓库和定期更新服务的书籍,避免购买仅包含静态文本的廉价出版物,因为AI技术迭代极快,静态内容极易过时。
2026年学习AI大模型,还需要深入研读Transformer论文吗?
对于大多数应用层开发者,无需逐字研读原始论文,理解其核心思想(如自注意力机制、位置编码)即可,除非你致力于模型架构创新或底层算法优化,否则应更多关注基于Transformer之上的工程实践,如LangChain、LlamaIndex等框架的使用,以及RAG和Agent的实际构建案例。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/375466.html