Apriori算法在MapReduce框架下的核心优势在于通过分布式迭代计算解决了传统单机模式下频繁项集挖掘面临的内存溢出与性能瓶颈,实现了海量交易数据的高效关联规则挖掘。
在大数据时代,处理TB甚至PB级的交易日志是常态,传统的Apriori算法虽然逻辑清晰,但在单机运行时会因为不断扫描数据库和生成候选集而变得极其缓慢,甚至直接导致内存崩溃,将Apriori与MapReduce结合,利用分布式计算集群的并行处理能力,成为了行业共识认为解决大规模数据挖掘问题的标准路径,这种结合不仅提升了计算速度,还保证了系统的可扩展性。

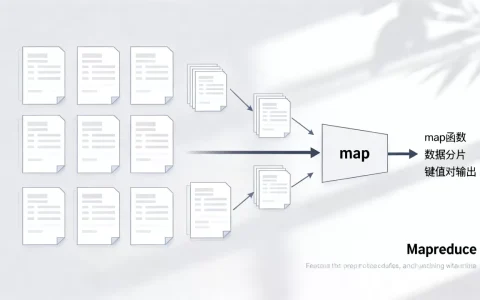
MapReduce实现Apriori的核心机制解析
Apriori算法依赖于“向下封闭性质”,即如果一个项集是频繁的,那么它的所有子集也必须是频繁的,MapReduce通过Map和Reduce两个阶段的巧妙配合,完美契合了这一迭代过程。
Map阶段:数据预处理与局部计数
在Map阶段,系统负责读取原始交易数据,每个Map任务处理一部分数据切片,识别出该切片中的所有频繁1-项集,这一步至关重要,因为它将全局问题分解为局部问题。
- 输入解析:Map任务读取每一行交易记录,提取其中的商品ID。
- 局部统计:在内存中维护一个哈希表,统计当前切片中每个商品出现的次数。
- 输出键值对:输出格式为<商品ID, 出现次数>。
Reduce阶段:全局聚合与剪枝
Reduce阶段负责合并所有Map任务的输出,进行全局计数,并根据设定的最小支持度阈值进行剪枝,生成新的频繁项集列表。
- 数据合并:Reduce任务接收来自所有Map任务的相同商品ID的计数,进行求和。
- 支持度过滤

:计算全局支持度,剔除低于阈值的项集。
- 生成候选集:根据Apriori原理,利用上一轮的频繁项集生成下一轮的候选项集。

迭代控制流程
整个过程是一个循环,上一轮Reduce输出的频繁项集,会作为下一轮Map阶段的输入,用于生成候选k-项集,直到某一轮没有新的频繁项集生成,算法终止,这种迭代机制确保了计算的精确性和完整性。
分布式Apriori的性能优化策略
虽然MapReduce提供了基础框架,但未经优化的实现往往效率低下,业内专家指出,针对MapReduce特性的优化是提升性能的关键。
减少I/O开销
MapReduce的磁盘I/O是性能瓶颈的主要来源,优化策略包括:
- 压缩中间数据:在Map输出和Reduce输入之间启用数据压缩,减少网络传输和磁盘读写量。
- 合并小文件:在Map阶段之前,合并大量小文件,避免产生过多的Map任务,降低调度开销。
- 内存缓存:对于频繁项集的列表,尽量在内存中维护,避免每次都从磁盘读取。
优化候选集生成
传统的Apriori算法在生成候选k-项集时,会产生大量的无效候选集,优化方法包括:
- 哈希树剪枝:使用哈希树结构存储频繁项集,快速判断候选集是否为频繁子集。
- 位图技术:利用位图表示交易记录,加速交集运算,提高支持度计算的效率。
实际应用场景与选型建议
了解技术原理后,更重要的是知道何时使用以及如何使用,不同场景下,对MapReduce实现Apriori的需求截然不同。
电商推荐系统中的关联分析
在电商平台,用户购买行为数据量巨大,通过挖掘“啤酒与尿布”这类经典关联规则,可以优化商品摆放和推荐策略。

- 数据规模:日均千万级订单,历史数据达PB级。
- 实时性要求:离线分析为主,T+1更新推荐模型。
- 实施路径:使用HDFS存储原始日志,通过MapReduce运行Apriori,结果存入HBase供在线系统查询。
医疗数据中的疾病共现分析
在医疗领域,分析患者病历中的疾病共现关系,有助于发现潜在的诊断线索。
- 数据特点:数据稀疏,项集维度高。
- 挑战:需要处理缺失值和噪声数据。
- 优化重点:加强数据预处理,提高算法对噪声的鲁棒性。
与其他算法的对比
| 特性 | MapReduce Apriori | Spark MLlib FP-Growth | Hadoop Hive SQL |
|---|---|---|---|
| 计算模式 | 迭代式MapReduce | 内存迭代计算 | 声明式查询 |
| 适用数据量 | 超大规模,TB/PB级 | 中等规模,GB/TB级 | 中小规模,GB级 |
| 开发复杂度 | 较高,需自定义Mapper/Reducer | 中等,使用API | 低,编写SQL即可 |
| 执行速度 |
较慢,依赖磁盘I/O | 快,依赖内存 | 中等,取决于优化器 |

对于大数据量且对实时性要求不高的场景,MapReduce Apriori依然是稳健的选择,但对于追求更高吞吐量的场景,Spark生态下的算法可能更具优势。
常见问题解答:MapReduce Apriori实战指南
MapReduce Apriori算法在大规模数据下的性能瓶颈主要体现在哪里?
性能瓶颈主要集中在磁盘I/O和网络传输上,由于Apriori是迭代算法,每一轮都需要将中间结果写入HDFS,并在下一轮读取,这种频繁的磁盘读写严重拖慢了速度,候选项集的数量可能呈指数级增长,导致Reduce任务的数据倾斜,某些节点处理数据量远超其他节点,造成整体等待时间延长。
如何配置MapReduce Apriori的参数以获得最佳效果?
关键参数包括最小支持度阈值、Map和Reduce的任务数量以及内存分配,最小支持度阈值应根据业务需求设定,过高会丢失有用规则,过低会导致计算量爆炸,任务数量应与集群节点数和数据块大小匹配,避免资源浪费,内存分配方面,需确保Reduce任务有足够的堆内存来处理合并后的数据,防止OOM(内存溢出)。
MapReduce Apriori与Spark Apriori的主要区别是什么?
主要区别在于计算引擎和数据处理方式,MapReduce基于磁盘的迭代计算,适合超大规模数据,但速度较慢;Spark基于内存的迭代计算,速度更快,适合对实时性要求较高的场景,Spark提供了更高级的API,开发效率更高,而MapReduce需要编写大量的样板代码,对于中小规模数据,Spark通常更优;对于超大规模数据且集群资源有限时,MapReduce的稳定性更具优势。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/378870.html










评论列表(1条)
卧槽这不就是我上回在阿里做电商推荐踩的坑嘛!MapReduce版Apriori当年真救我狗命——单机跑十亿订单直接OOM