大模型部署负载均衡的核心在于构建“网关层+推理集群+动态路由”的三层架构,通过智能流量分发解决显存瓶颈与并发延迟矛盾,确保服务高可用。
在大模型落地生产的实际场景中,单卡或单服务器早已无法满足业务需求,随着参数量级向千亿甚至万亿迈进,推理成本与响应速度成为企业最头疼的两个痛点,传统的Nginx或LVS负载均衡器虽然成熟,但面对大模型特有的长上下文、高并发请求以及GPU资源碎片化问题,往往显得力不从心,业内专家指出,单纯依靠硬件堆砌无法根本解决性能问题,必须引入针对AI负载特性优化的调度策略。
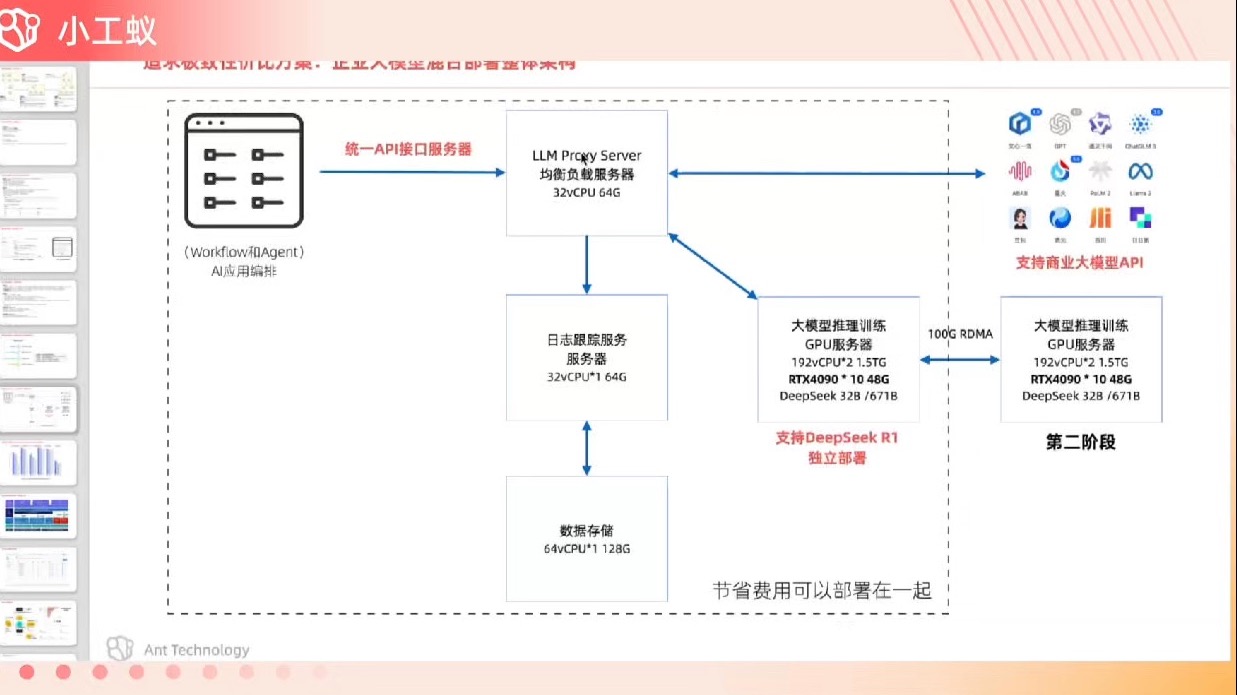
大模型负载均衡架构设计核心要素
要搭建一套稳健的大模型服务集群,首先需要理清数据流向,大模型的推理过程分为“预填充(Prefill)”和“解码(Decode)”两个阶段,这两个阶段对计算资源的需求截然不同,预填充阶段是矩阵乘法密集型,适合高吞吐;解码阶段是自回归生成,受限于内存带宽,适合低延迟。
网关层:流量入口的智能分流
网关层是用户请求进入集群的第一道关卡,它不仅要处理HTTPS协议转换、鉴权认证,更要承担初步的流量清洗和路由决策。
- 请求预处理:在请求到达推理引擎前,网关需检查Token长度、用户权限及速率限制,对于超长上下文请求,网关可提前触发分块处理或拒绝策略,避免阻塞核心推理节点。
- 多模型路由:现代企业往往部署多个不同规模的大模型(如7B、70B、175B),网关需根据业务场景自动识别请求类型,将简单问答路由至小模型,将复杂逻辑推理路由至大模型,实现成本与效果的平衡。
- 熔断与降级:当后端集群负载过高时,网关需快速响应,返回缓存结果或友好提示,防止雪崩效应。
推理集群:GPU资源的精细化调度
这是负载均衡的核心战场,传统的轮询算法在大模型场景下完全失效,因为不同请求的计算复杂度差异巨大。
- 张量并行(TP)与流水线并行(PP)

:对于超大模型,单卡无法容纳权重,需跨多卡并行,负载均衡器需感知这种拓扑结构,将相关请求路由至同一组GPU节点,减少节点间通信开销。
- KV Cache管理:大模型推理的最大瓶颈在于显存中的KV Cache,高效的负载均衡方案需实时监控各节点的显存碎片率,动态调整新请求的分配策略,优先填充显存利用率较低或碎片较少的节点。
- 动态批处理(Dynamic Batching):网关或推理引擎需将多个短请求合并为一个批次进行推理,最大化GPU利用率,负载均衡器需协调批次大小,平衡吞吐量与延迟。

主流负载均衡方案对比与选型指南
目前市场上存在多种大模型负载均衡方案,从开源框架到商业云服务,各有优劣,选择哪种方案,取决于企业的技术储备、预算及对延迟的敏感度。
开源框架自研方案
对于拥有强大研发能力的团队,基于vLLM、TGI(Text Generation Inference)或SGLang等开源推理引擎自建负载均衡是常见选择。
- 优势:完全可控,无授权费用,可深度定制内核级优化。
- 劣势:维护成本高,需组建专门的AI Infra团队,故障排查难度大。
- 适用场景:头部互联网大厂、对数据隐私极度敏感且具备深厚技术积累的金融机构。
云厂商托管服务方案
阿里云、腾讯云、百度智能云等主流云厂商均提供大模型推理加速服务,内置了成熟的负载均衡机制。
- 优势:开箱即用,弹性伸缩能力强,无需关心底层硬件维护。
- 劣势:数据需上传至云端,存在合规风险;长期运行成本可能高于自建。
- 适用场景:中小企业、初创公司、非核心业务场景。
混合部署方案
结合上述两者,核心模型自建,边缘场景使用云端API,通过统一网关进行流量调度。
- 优势:兼顾成本、安全与弹性。
- 劣势:架构复杂,网络延迟需优化。
- 适用场景:中大型企业,业务场景多样化。

关键指标对比
| 方案类型 | 延迟表现 | 成本可控性 | 运维复杂度 | 数据安全 |
|---|---|---|---|---|
| 开源自建 | 优(可优化至毫秒级) | 高(一次性投入) | 极高 | 极高 |
| 云托管 | 中(受网络波动影响) | 中(按量付费) | 低 | 中(依赖云厂商合规) |
| 混合部署 | 良 | 高 | 高 | 高 |
实施步骤与实操建议
无论选择哪种方案,落地过程中的细节决定成败,以下是经过验证的实操步骤,帮助团队规避常见陷阱。
第一步:基准测试与容量规划
在部署前,必须进行充分的压力测试,使用工具如LLMPerf或自定义脚本,模拟真实用户行为,测量不同并发下的TPOT(Time Per Output Token)和TTFT(Time To First Token)。
- 确定QPS上限:根据业务峰值,计算所需GPU数量,建议预留20%-30%的冗余资源以应对突发流量。
- 显存预估:精确计算每个请求占用的显存,包括模型权重、KV Cache及激活值。
第二步:配置动态路由策略
避免使用简单的Round-Robin(轮询),建议采用基于权重的最小连接数算法,或基于预测延迟的算法。
- 监控指标接入:集成Prometheus和Grafana,实时监控GPU利用率、显存占用、请求队列长度等关键指标。
- 自动扩缩容(HPA):配置Kubernetes HPA,当GPU利用率超过阈值(如80%)时,自动增加Pod副本;低于阈值时,自动缩减。

第三步:缓存层优化
对于重复性高的问答场景,引入Redis或Memcached作为缓存层。
- 语义缓存:不仅匹配完全相同的文本,还需利用Embedding模型计算语义相似度,匹配相似意图的请求,大幅降低重复推理成本。
- TTL策略:设置合理的过期时间,确保缓存数据的时效性。
常见问题与解决方案
大模型负载均衡中如何有效降低首字延迟?
首字延迟(TTFT)是用户体验的关键,降低TTFT的核心在于减少预填充阶段的等待时间,启用连续批处理(Continuous Batching),允许新请求插入正在处理的批次中,避免空闲等待,优化网络IO,使用RDMA技术加速节点间通信,在网关层实施请求压缩和预取策略,提前加载常用模板和系统提示词。
显存碎片化严重导致服务不可用怎么办?
显存碎片化是大模型长期运行后的常见问题,解决方案包括:定期重启推理服务以释放碎片;使用支持内存池管理的推理引擎(如vLLM的PagedAttention机制);实施显存监控告警,当碎片率超过阈值时,自动触发服务迁移或重启,合理设置最大上下文长度,避免单个请求占用过多显存。
多租户场景下如何保证资源隔离与公平性?
在多租户环境中,需防止“吵闹的邻居”问题,通过Kubernetes的LimitRange和ResourceQuota限制每个租户的GPU和显存使用上限,在负载均衡层,实施基于租户的权重分配,确保高优先级租户获得足够的资源,引入队列优先级机制,紧急请求优先处理,普通请求排队等待。
大模型部署负载均衡并非一劳永逸的配置,而是一个持续优化的过程,随着模型架构的演进和硬件的更新,调度策略也需不断迭代,唯有深入理解模型推理特性,结合精细化监控与自动化运维,才能在激烈的竞争中提供稳定、高效、低成本的大模型服务。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/397639.html