LM Studio 与 Cursor 配合的核心在于通过本地 API 接口将 LM Studio 运行的开源模型接入 Cursor 的代码编辑器,从而实现完全离线、隐私安全且可定制的智能编程辅助。
这种组合方式打破了传统云端 AI 编程工具的依赖限制,让开发者能够利用本地强大的 GPU 资源,运行 Llama 3、Mistral 等高性能开源模型,既保护了代码知识产权,又避免了高昂的 API 调用费用,对于注重数据隐私或身处网络受限环境的开发者而言,这是一套极具性价比的解决方案。
LM Studio 和 Cursor 配合的技术原理
要理解两者的配合,首先要明白它们各自的角色,LM Studio 是一个本地模型运行器,负责加载、推理并托管大语言模型;而 Cursor 是一个基于 VS Code 修改的智能 IDE,它通过 API 接口与后端模型通信。
API 接口的桥梁作用
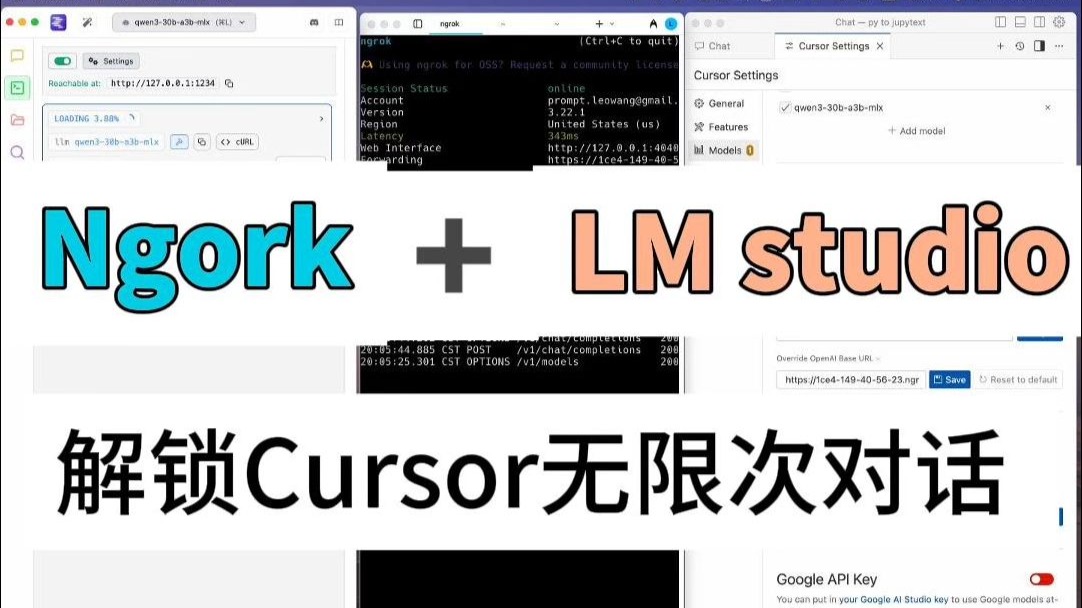
LM Studio 启动后,默认会在本地启动一个 OpenAI 兼容的 API 服务器,这意味着,任何支持 OpenAI API 格式的客户端,都可以向 LM Studio 发送请求并接收响应,Cursor 正是利用了这一特性,允许用户自定义 API 端点。
当你在 Cursor 中按下 Ctrl+L 打开聊天窗口时,Cursor 不会直接连接 OpenAI 或 Anthropic 的服务器,而是将你的提示词打包成 JSON 格式,发送给 LM Studio 监听的本地地址(通常是 http://localhost:1234/v1/chat/completions),LM Studio 接收请求,调用本地加载的模型进行推理,再将生成的代码或解释返回给 Cursor 显示。
延迟与性能的关键因素
这种本地部署方式的体验高度依赖于你的硬件配置,业内专家指出,GPU 的显存大小直接决定了能运行多大的模型,而显存带宽则影响生成速度。
- 显存充足:如果你拥有 16GB 以上显存的 NVIDIA 显卡,可以流畅运行 7B 到 13B 参数的量化模型,响应速度通常在毫秒级。
- 显存有限:若显存较小,可能需要使用 CPU 推理或降低模型量化精度,这会导致生成速度明显变慢,甚至出现卡顿。
- 内存带宽:对于 Apple Silicon 芯片的 Mac 用户,统一内存架构使得大模型加载更加高效,但高负载下仍可能引发风扇狂转。

LM Studio 和 Cursor 配合的具体操作步骤
实现这一配合过程并不复杂,只需按照以下路径配置即可,整个过程无需编写代码,完全通过图形界面完成。
第一步:配置 LM Studio
确保你已经下载并安装了最新版本的 LM Studio,从 Hugging Face 或 LM Studio 内置模型库中下载你喜欢的模型文件(推荐 .gguf 格式)。
启动本地服务器
- 在 LM Studio 左侧导航栏点击“Local Server”图标。
- 在右侧选择已下载的模型,调整“Context Length”(上下文长度),一般建议设置为 8192 或 16384,以容纳更多代码上下文。
- 点击“Start Server”按钮。
- 记下服务器地址,默认为
http://localhost:1234,确保防火墙未阻止该端口的本地连接。
第二步:配置 Cursor 连接
打开 Cursor 编辑器,进入设置界面进行 API 配置。
修改 API 设置
- 点击左上角头像,选择“Settings”(设置)。
- 在左侧菜单中找到“Features”下的“Cursor Settings”或直接寻找“API”相关选项。
- 在“API Provider”下拉菜单中,选择“Custom”或“OpenAI Compatible”。
- 在“API Base URL”字段中,填入
http://localhost:1234/v1。 - 在“API Key”字段中,由于 LM Studio 默认不强制要求密钥,你可以随意输入一串字符,如
lm-studio-key,或者留空(取决于 Cursor 版本的具体要求,通常填入任意非空字符串即可绕过验证)。 - 保存设置。
验证连接
回到编辑器,按下 Ctrl+L 打开聊天面板,输入一句简单的测试指令,如“你好”,LM Studio 中的模型开始生成文本,且 Cursor 界面实时显示,说明配置成功。

LM Studio 和 Cursor 配合的优势与局限
这种组合并非完美无缺,了解其优劣有助于你做出更合适的技术选型。
核心优势分析
- 数据隐私绝对安全:所有代码和数据均在本地处理,不会上传至任何第三方服务器,这对于处理敏感商业代码、金融数据或医疗信息的团队至关重要。
- 无额度限制:不像 Claude 或 GPT-4 有严格的每分钟请求限制,本地模型只要硬件允许,可以无限次调用,适合高频次的代码重构和批量生成任务。
- 成本可控:一次性购买硬件或免费使用开源模型,无需支付按 Token 计费的 API 费用,对于重度开发者,长期来看能节省大量开支。
潜在局限与挑战
- 硬件门槛高:需要配备较强的 GPU 和充足的内存,低端设备无法运行主流大模型,体验远不如云端 API。
- 模型能力上限:受限于显存,本地运行的模型参数规模通常小于云端提供的最新旗舰模型(如 GPT-4o 或 Claude 3.5 Sonnet),在复杂逻辑推理和长代码理解上,可能略逊一筹。
- 维护成本:需要自行管理模型更新、量化版本选择以及服务器稳定性,缺乏云端服务的自动运维支持。
LM Studio 和 Cursor 配合的最佳实践
为了让这套组合发挥最大效能,建议遵循以下实操建议。
模型选择策略
并非所有模型都适合编程,业内共识认为,针对代码优化的模型能显著提升生成质量。
推荐模型类型
- 代码专用模型:如 CodeLlama、StarCoder2 或 DeepSeek-Coder,这些模型在海量代码数据上训练过,对语法理解和补全更准确。
- 通用大模型:如 Llama 3 或 Mistral Large,适合处理非代码类的自然语言任务,如文档生成、需求分析。
- 量化版本:优先选择 Q4_K_M 或 Q5_K_M 量化版本,它们在保持较高精度的同时,大幅降低了显存占用,平衡了性能与资源。

上下文管理技巧
本地模型的上下文窗口有限,合理管理上下文是提升效果的关键。
优化提示词
- 精简输入:不要一次性粘贴整个文件,而是选中相关代码片段再发送指令。
- 明确角色:在提示词中明确指定模型角色,如“你是一个资深 Python 工程师”,有助于激活模型的专业领域知识。
- 分步执行:对于复杂任务,拆分为多个小步骤,逐步引导模型生成,避免一次性输出过长导致截断或逻辑混乱。
常见疑问解答
LM Studio 和 Cursor 配合时出现连接错误怎么办?
首先检查 LM Studio 的服务器是否处于“Running”状态,确认 Cursor 中的 API Base URL 是否准确无误,特别注意末尾是否有斜杠,如果仍无法连接,尝试重启 LM Studio 和 Cursor,并检查电脑防火墙是否拦截了 localhost 的 1234 端口,多数情况下,端口冲突或服务未启动是主要原因。
本地模型生成的代码质量不如云端 API 怎么办?
这是由模型参数规模和训练数据决定的客观事实,如果当前本地模型效果不佳,建议尝试更换更大参数量的模型(如从 7B 升级到 13B 或 34B,前提是硬件支持),或切换到专门针对代码训练的模型如 CodeLlama,优化提示词工程,提供更详细的代码上下文和约束条件,也能显著改善输出质量。
LM Studio 和 Cursor 配合是否支持多模型切换?
支持,你可以在 LM Studio 中加载多个模型,并在服务器运行时通过 API 参数指定使用哪个模型,在 Cursor 中,虽然通常只连接一个 API 端点,但你可以通过修改 LM Studio 的模型加载配置,动态切换当前服务的模型,从而实现不同任务使用不同模型的效果。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/398851.html