Ollama与NextChat配合的核心在于利用NextChat作为前端交互界面,通过API接口连接本地运行的Ollama服务,从而实现无需付费订阅、完全隐私安全的本地大模型对话体验。
这种组合并非简单的软件叠加,而是构建了一个私有的AI工作流,对于追求数据隐私、希望零成本体验前沿大模型或需要定制化模型微调的用户来说,这是目前性价比最高的解决方案,我们将拆解这一技术栈的落地细节,从环境搭建到进阶配置,确保你能顺利跑通这套系统。
Ollama与NextChat配合的技术逻辑
要理解两者的配合,首先要明确它们的分工,Ollama是一个在本地运行大型语言模型的开源工具,它负责“思考”,即处理模型推理和资源调度,NextChat(通常指Dify或类似的前端聚合工具,此处特指开源项目NextChat)则是一个强大的前端界面,它负责“表达”,即提供美观的UI、多模型切换、上下文管理以及插件集成。
业内专家指出,这种前后端分离的架构优势在于解耦,你可以随时更换后端的模型提供商,而无需改变前端的操作习惯,当NextChat通过API请求发送给Ollama时,Ollama接收指令,调用本地GPU或CPU进行计算,并将结果返回给NextChat展示,整个过程在局域网或单机内完成,数据不出本地,彻底杜绝了隐私泄露风险。
本地环境搭建与基础配置
搭建这套系统的第一步是确保基础环境就绪,你需要一台性能尚可的电脑,最好配备NVIDIA显卡,因为本地运行模型对显存有一定要求。
安装Ollama服务
Ollama的安装极其简单,支持Windows、macOS和Linux,访问官方网站下载对应系统的安装包,按照提示完成安装,安装完成后,打开终端或命令行工具,输入以下命令即可验证安装是否成功:

ollama --version
如果返回版本号,说明服务已就绪,你需要拉取一个模型,以流行的Llama 3为例,只需执行:
ollama run llama3
首次运行会自动下载模型文件,下载完成后,你将进入交互界面,可以直接输入问题进行测试,这一步验证了Ollama作为后端服务的可用性。
部署NextChat前端
NextChat的部署方式多样,推荐使用Docker部署,因为这种方式最稳定且易于管理,确保你的服务器或本地机器已安装Docker和Docker Compose。
创建一个名为docker-compose.yml的文件,内容如下:
version: '3.8'
services:
nextchat:
image: chenzhaoyu94/chatgpt-next-web
container_name: nextchat
ports:
- 3000:3000
environment:
- OPENAI_API_KEY=sk-your-key
- BASE_URL=https://api.openai.com
注意,这里的配置是默认指向OpenAI的,我们需要修改环境变量,使其指向本地的Ollama服务,修改environment部分:
- OPENAI_API_KEY=sk-never-gonna-give-you-up
- BASE_URL=http://localhost:11434/v1
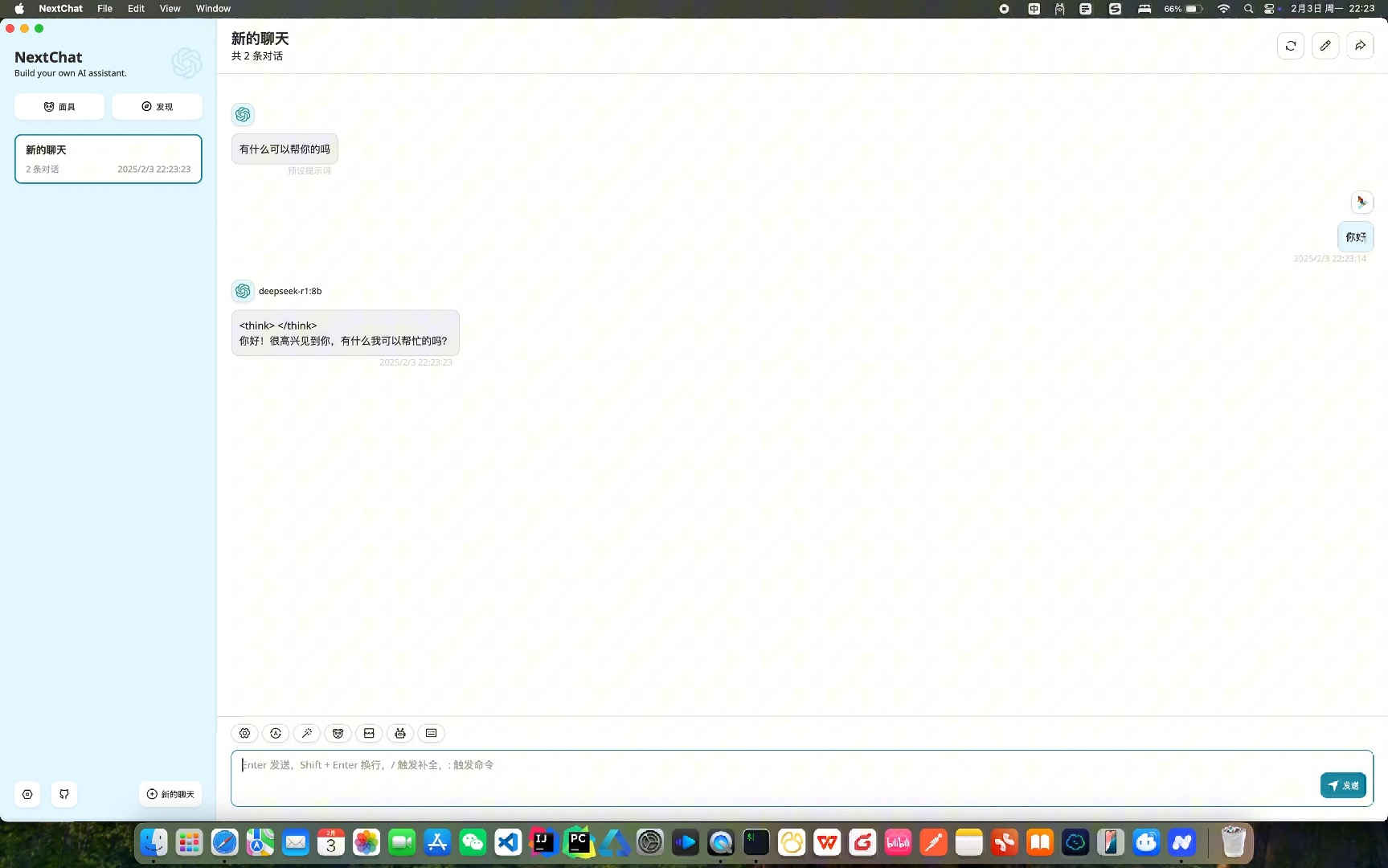
这里的关键在于BASE_URL,Ollama默认监听11434端口,并且兼容OpenAI的API格式,路径为/v1,启动容器后,访问http://localhost:3000,即可看到NextChat的界面。

进阶配置与性能优化
基础连接打通后,你可能会发现响应速度不够快,或者某些高级功能无法使用,这时需要进行进阶配置。
解决跨域与网络问题
在Windows或Mac本地开发环境中,NextChat容器内的localhost指向的是容器本身,而非你的主机。BASE_URL不能写localhost。
对于Windows用户,可以使用host.docker.internal作为主机名:
- BASE_URL=http://host.docker.internal:11434/v1
对于Linux用户,如果NextChat部署在服务器上,而Ollama也在同一台服务器上,则可以使用0.0.1,如果Ollama在另一台机器,需填写该机器的局域网IP地址。
模型参数调优
Ollama支持通过Modelfile自定义模型参数,如上下文窗口大小、温度(Temperature)等,创建Modelfile文件:
FROM llama3 PARAMETER temperature 0.7 PARAMETER num_ctx 4096
然后构建并运行:
ollama create my-llama3 -f Modelfile ollama run my-llama3
在NextChat中,你可以通过API密钥配置来区分不同的模型实例,你可以为llama3和my-llama3设置不同的API密钥前缀,从而在NextChat中切换不同配置的模型。
常见问题排查与解决方案
在实际使用中,用户常遇到连接失败或响应异常的问题,以下是几种常见场景的解决方案。
连接被拒绝
如果NextChat提示“连接失败”或“网络错误”,首先检查Ollama服务是否正在运行,在终端输入:

curl http://localhost:11434/api/tags
如果返回模型列表,说明服务正常,如果返回错误,尝试重启Ollama服务,检查防火墙设置,确保端口11434未被拦截。
响应速度慢
本地运行模型的速度受硬件限制,如果显存不足,模型可能会溢出到系统内存,导致速度急剧下降,可以通过监控任务管理器或Activity Monitor观察内存和显存使用情况。
行业共识认为,对于7B参数的模型,至少需要8GB显存才能流畅运行,如果硬件有限,可以选择量化版本(如Q4_K_M),它们在保持较高精度的同时,显著降低了资源占用。
多模型切换
NextChat支持多模型配置,在Ollama中拉取多个模型,如qwen2、mistral等,在NextChat的设置中,你可以添加多个API端点,分别指向不同的模型名称。
- 端点1:
http://localhost:11434/v1/chat/completions,模型名llama3 - 端点2:
http://localhost:11434/v1/chat/completions,模型名qwen2
这样,你就可以在NextChat界面中自由切换不同的本地模型,享受多样化的AI体验。
Ollama与NextChat的配合,本质上是本地算力与智能界面的完美结合,通过简单的API配置,用户即可获得一个免费、隐私、高效的AI助手,无论是开发者还是普通用户,掌握这一技术栈,都能在未来AI应用中占据主动,关键在于保持环境更新,合理配置硬件资源,并根据需求灵活调整模型参数。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/399413.html