提升vLLM吞吐量的核心在于平衡显存利用率、并发请求数与计算内核效率,通过调整PagedAttention配置、优化批处理策略及部署量化模型,可实现数倍的性能跃升。
在大规模语言模型落地场景中,开发者往往面临一个尴尬的境地:模型推理延迟尚可,但吞吐量(Throughput)成为瓶颈,这意味着单位时间内处理的请求数量有限,导致服务器资源闲置或响应排队过长,vLLM之所以成为主流选择,是因为其引入了PagedAttention技术,有效解决了显存碎片化问题,默认配置并非性能天花板,要挖掘其最大潜力,需要从显存管理、批处理机制、模型量化以及硬件调度四个维度进行精细化调优。
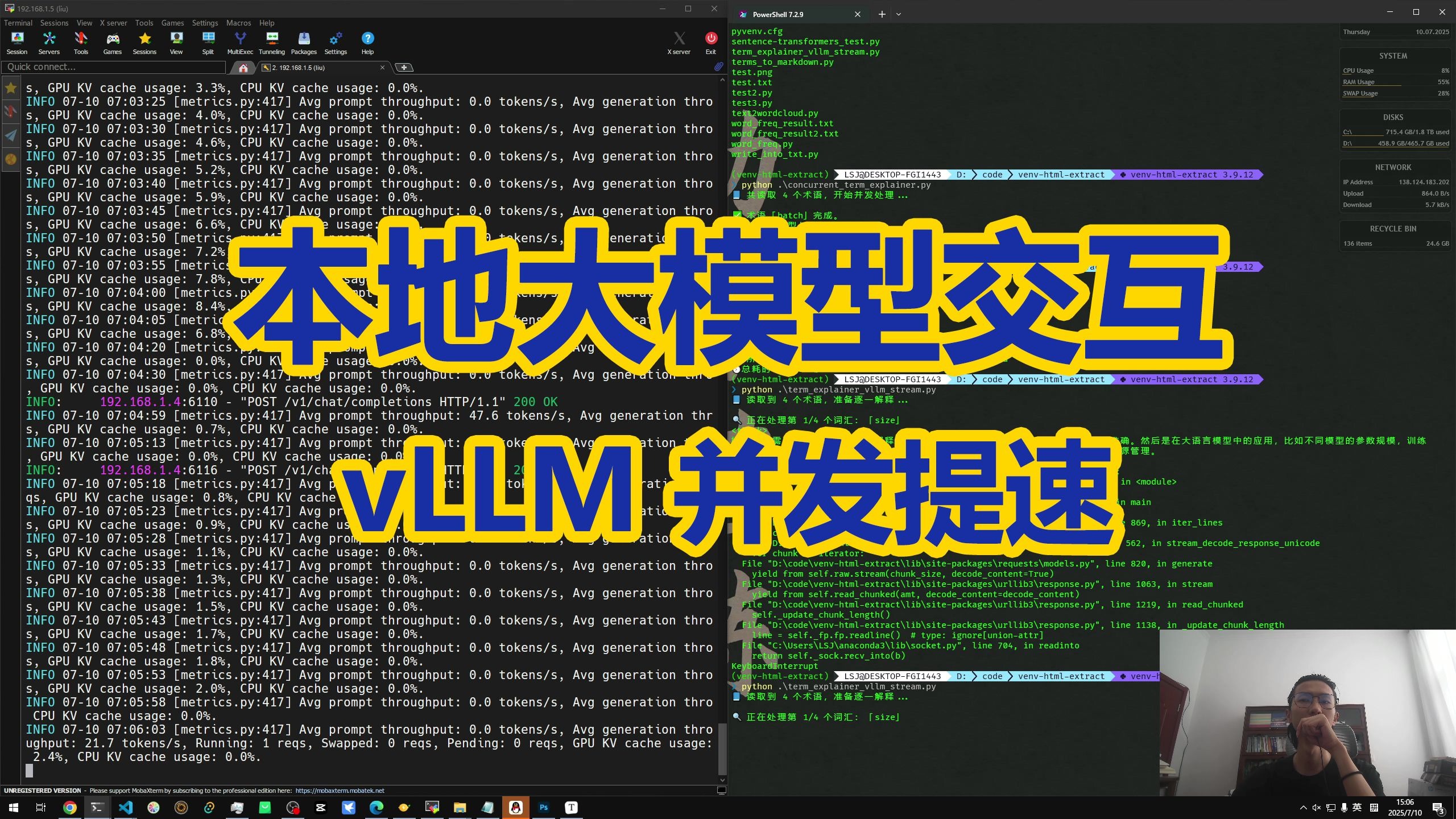
vLLM吞吐量优化实战指南
显存管理与PagedAttention深度调优
PagedAttention是vLLM的灵魂,它将KV Cache像操作系统内存页一样进行分页管理,默认情况下,vLLM会预留一定的显存用于动态扩展,但这可能导致实际可用显存不足,限制了最大并发批次大小(Batch Size)。
调整块大小与预分配策略
块大小(Block Size)直接影响显存分配粒度,较小的块大小可以减少浪费,但会增加管理开销;较大的块大小则相反,业内专家指出,对于大多数Transformer架构模型,将块大小设置为16或32是较为通用的选择,若遇到显存溢出错误,首先检查是否因长文本导致KV Cache激增,可通过设置--max-num-batched-tokens参数来限制单次批处理的最大token数,从而防止显存爆炸。
启用连续批处理(Continuous Batching)是关键,vLLM默认开启此功能,它允许在请求完成时立即插入新请求,而不是等待整个批次结束,这显著提高了GPU利用率,在实际操作中,建议监控GPU利用率曲线,若发现波动剧烈,可适当增加

--max-num-seqs,允许更多的序列同时存在。
显存利用率监控与调整
许多开发者忽视了一个细节:vLLM的显存预留机制,默认情况下,它会预留10%-20%的显存用于防止OOM(内存溢出),在追求极致吞吐量的场景下,这一预留比例显得奢侈,通过设置--gpu-memory-utilization参数,可以将其降低至0.9甚至更低(需确保系统稳定),据行业共识认为,将显存利用率推高至90%以上,能直接释放更多空间用于KV Cache,从而容纳更多并发请求。
批处理策略与并发控制
批处理是提升吞吐量的另一大杠杆,vLLM支持多种批处理策略,包括静态批处理和动态批处理。
动态批处理的最佳实践
动态批处理允许vLLM根据请求到达时间和完成状态动态调整批次,为了最大化吞吐量,需要平衡延迟和吞吐,较小的批次大小带来低延迟,但GPU计算效率低;较大的批次大小提高GPU利用率,但增加首字延迟(TTFT)。
建议采用以下配置路径:
- 设置
--max-num-batched-tokens为一个适中的值,如4096或8192,避免单次批处理过大导致超时。 - 调整
--max-num-seqs,根据显存容量设定最大并发序列数。 - 启用
--enable-chunked-prefill,这对于长上下文模型尤为重要,它能将预填充阶段分块处理,减少内存峰值。
并发请求的平滑处理
在高并发场景下,请求到达的不均匀性可能导致GPU负载波动,vLLM的流式输出(Streaming Output)功能可以帮助平滑这一过程,通过启用流式输出,客户端可以逐步接收结果,而服务端则能更灵活地调度资源,使用异步API客户端(如

aiohttp或httpx)而非同步客户端,能显著减少网络等待时间,提升整体系统吞吐量。
模型量化与精度选择
模型精度直接影响显存占用和计算速度,从FP16到INT8,再到INT4,精度的降低带来显存的节省和推理速度的提升,但可能牺牲一定的模型准确率。
量化技术的选型
vLLM支持多种量化格式,包括AWQ(Activation-aware Weight Quantization)、GPTQ和SqueezeLLM,AWQ在精度和速度之间取得了较好的平衡,适合大多数生产环境,若对延迟极其敏感且能接受轻微精度损失,INT4量化是更佳选择。
操作建议:
- 优先使用预量化的模型权重,如Hugging Face上的AWQ量化版本。
- 若需自行量化,使用
autoawq或optimum工具进行后训练量化。 - 在vLLM启动时,通过
--quantization参数指定量化格式,如--quantization awq。
精度与吞吐量的权衡
量化不仅节省显存,还能加速计算,现代GPU对INT8/INT4指令有专门优化,据统计,INT4量化模型在同等硬件下,吞吐量可比FP16模型提升2-3倍,需注意量化带来的精度下降,对于代码生成或数学推理等对精度要求极高的任务,建议保留FP16或BF16精度;对于文本摘要或对话生成,INT8或INT4通常足够。
硬件调度与系统级优化
软件优化离不开硬件支持,vLLM的性能发挥依赖于底层硬件的高效调度。
多卡并行策略
当模型过大无法单卡容纳时,需启用张量并行(Tensor Parallelism)或流水线并行(Pipeline Parallelism),vLLM通过--tensor-parallel-size参数轻松实现多卡并行。
建议:
- 确保多卡之间通过NVLink高速互联,避免PCIe带宽瓶颈。
- 调整
--pipeline-parallel-size,若模型层数较多,可考虑流水线并行。 - 监控多卡显存均衡性,确保各卡负载均匀,避免单卡成为瓶颈。

操作系统与驱动优化
Linux内核参数对网络IO和内存管理有显著影响,建议调整net.core.somaxconn和net.ipv4.tcp_max_syn_backlog,以支持更高并发连接,确保CUDA驱动和cuDNN库为最新版本,以获得最新的性能优化。
vLLM吞吐量优化常见问题解答
vLLM吞吐量优化中如何平衡延迟与吞吐?
平衡延迟与吞吐的核心在于调整批处理大小和并发数,增大max-num-batched-tokens和max-num-seqs可提高吞吐量,但会增加首字延迟,建议通过压测工具(如locust或wrk)模拟真实流量,绘制延迟-吞吐曲线,找到拐点,对于交互式应用,优先保证低延迟,设置较小的批次;对于离线批处理任务,优先保证高吞吐,设置较大的批次。
vLLM吞吐量优化中量化模型是否会影响精度?
量化确实会影响模型精度,但影响程度取决于量化方法和模型类型,AWQ和GPTQ等先进量化技术在保持精度的同时,能显著降低显存占用,对于大多数自然语言处理任务,INT8量化带来的精度损失在可接受范围内,若对精度极度敏感,建议使用FP16或BF16,或采用混合精度训练后的量化模型。
vLLM吞吐量优化中多卡并行配置有哪些注意事项?
多卡并行需注意通信开销和显存均衡,确保使用高速互联(如NVLink),并合理分配张量并行和流水线并行大小,监控各卡显存使用情况,避免单卡OOM,调整环境变量如NCCL_IB_DISABLE和NCCL_SHM_DISABLE,以优化多卡通信效率。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/400865.html