大模型图像描述生成技术通过多模态架构将视觉信息转化为自然语言,显著提升了AI对复杂场景的理解精度与交互效率,已成为智能搜索、无障碍辅助及内容创作的核心基础设施。
技术原理与核心机制解析
视觉编码与语言解码的协同
大模型并非简单地“看图说话”,而是通过复杂的神经网络架构实现跨模态对齐,业内专家指出,这一过程主要依赖两个关键组件:视觉编码器(Vision Encoder)和语言模型(Language Model),视觉编码器负责将图像像素转化为高维向量特征,捕捉边缘、纹理、物体形状等底层信息;语言模型则负责将这些特征映射到语义空间,生成连贯的文本描述。
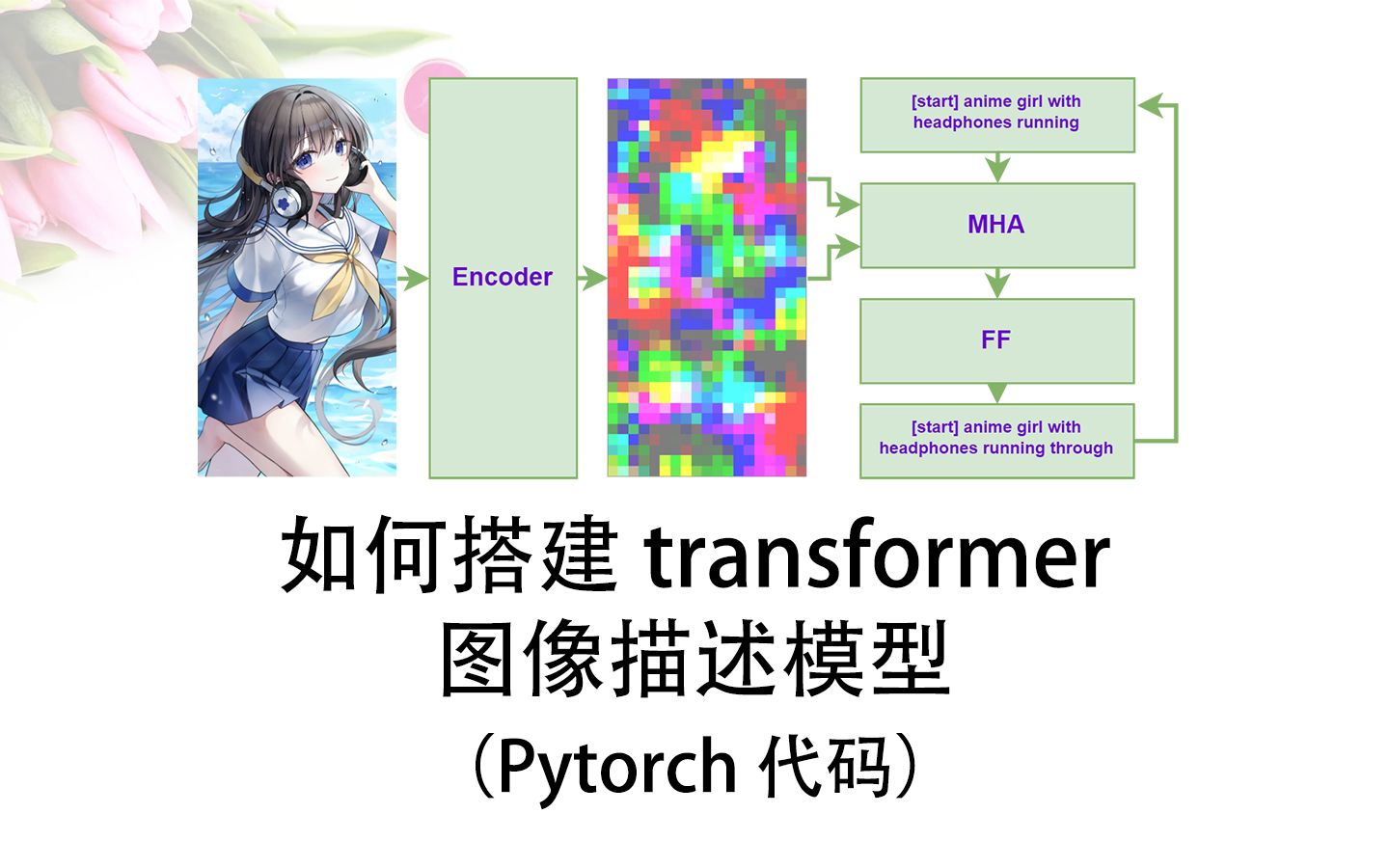
这种架构的核心在于“注意力机制”(Attention Mechanism),它允许模型在生成每个词汇时,动态关注图像中的不同区域,当描述“一只在草地上奔跑的金毛犬”时,模型会分别关注“草地”的绿色区域、“金毛犬”的黄色毛发区域以及“奔跑”动作所暗示的动态模糊区域,这种细粒度的对齐能力,使得描述不再局限于物体识别,而是能够捕捉场景中的互动关系和细微情感。
从分类到生成的范式转变
传统的计算机视觉任务多侧重于图像分类或目标检测,回答的是“图中有什么”,而大模型的图像描述生成则进一步回答“图中发生了什么”以及“这意味着什么”,这种转变带来了质的飞跃:
- 细粒度描述:不仅能识别出“人”和“车”,还能描述人的衣着颜色、车的品牌型号以及两者之间的相对位置。
- 上下文推理:结合场景常识,推断出图像背后的潜在信息,看到“打伞”和“积水”,模型可以推断出“正在下雨”。
- 风格化表达

:根据指令调整描述风格,如生成诗歌般的描述、专业的新闻标题或简洁的标签。
应用场景与行业落地实践
无障碍辅助与视觉增强
对于视障群体而言,图像描述生成技术是连接数字世界的重要桥梁,主流智能手机和操作系统已内置此类功能,当用户拍摄一张照片时,系统不仅读出图片中的文字,还能描述场景氛围,描述“阳光透过树叶洒在公园长椅上,一位老人正在喂鸽子”,这种带有情感色彩的描述,比单纯的物体列表更能帮助视障用户构建心理图像。
据工信部相关数据显示,近年来智能终端在无障碍功能上的投入显著增加,图像描述生成已成为标配功能之一,这一技术不仅提升了用户体验,更体现了科技的人文关怀。
创作与SEO优化
在数字营销领域,图像描述生成正在重塑内容生产流程,对于拥有海量图片的电商平台或新闻网站,手动编写图片的替代文本(Alt Text)既耗时又难以保证质量,大模型可以批量生成高质量、包含关键词的图片描述,这不仅有助于搜索引擎优化(SEO),还能提升网站的无障碍合规性。
具体操作路径如下:
- 数据预处理:将图片上传至支持API的图像描述服务。
- 提示词工程:输入特定的指令,如“请生成一段适合电商SEO的图片描述,包含产品材质和适用场景”。
- 人工审核:对生成的描述进行简要校对,确保无事实错误。
这种自动化流程将内容生产效率提升了数倍,同时保证了描述的一致性和专业性。
智能搜索与视觉问答
传统的图像搜索依赖标签匹配,而基于大模型的视觉问答(VQA)系统则能理解用户的自然语言提问,用户不再需要输入关键词,而是可以直接问:“这张照片里穿红色衣服的人在做什么?”模型会分析图像,识别出人物及其动作,并生成自然语言回答,这种交互方式更加直观,极大地降低了用户的使用门槛。

技术挑战与未来趋势
幻觉问题与事实一致性
尽管大模型在图像描述方面表现优异,但“幻觉”(Hallucination)问题依然突出,模型有时会生成图像中不存在的细节,或错误地关联物体属性,将“白色猫”描述为“白色狗”,或将“晴天”描述为“雨天”。
为了解决这一问题,行业共识认为,需要引入更强的事实校验机制,这包括:
- 多模态对齐训练:使用更高质量、更精确标注的数据集进行微调。
- 置信度评估:让模型输出描述的置信度分数,低置信度的描述需人工复核。
- 检索增强生成:结合外部知识库,验证描述中的事实准确性。
实时性与计算资源优化
图像描述生成涉及大量的矩阵运算,对计算资源要求较高,在移动端或边缘设备上实时运行大模型面临挑战,为此,模型压缩技术(如量化、剪枝)和蒸馏技术成为研究热点,通过将大模型的知识迁移到小模型中,可以在保持较高描述质量的同时,显著降低推理延迟和能耗。
据业内统计,多数情况下,经过优化的轻量级模型在主流智能手机上的推理速度已能满足实时交互需求,这为技术的广泛普及奠定了基础。
如何选择适合的图像描述生成方案
对于企业或个人开发者而言,选择合适的图像描述生成方案需考虑以下因素:
云端API vs 本地部署
- 云端API:适合大多数应用场景,无需维护基础设施,按需付费,模型更新及时,适合对实时性要求不高、追求描述质量的用户。
- 本地部署:适合对数据隐私要求极高、或需要极低延迟的场景,但需要投入硬件成本和技术维护成本。

通用模型 vs 垂直领域模型
- 通用模型:如BLIP-2、LLaVA等,适用于多种场景,描述风格多样,但可能在特定领域(如医学影像、工业缺陷检测)精度不足。
- 垂直领域模型:针对特定领域进行微调,描述更专业、准确,但通用性较差。
常见问题解答(FAQ)
大模型图像描述生成与传统的OCR技术有什么区别?
OCR(光学字符识别)技术主要用于提取图像中的文字信息,回答的是“图中有哪些文字”,而图像描述生成技术则侧重于理解图像的整体内容、场景和语义,回答的是“图中描绘了什么场景”,两者可以互补使用,例如先通过OCR提取文字,再结合图像描述生成技术提供完整的场景理解。
图像描述生成的准确率受哪些因素影响?
准确率主要受图像质量、模型架构、训练数据质量以及提示词设计的影响,模糊、遮挡严重的图像会降低识别精度;高质量的训练数据能提升模型的泛化能力;精心设计的提示词能引导模型生成更符合用户期望的描述。
大模型图像描述生成在医疗影像分析中的应用前景如何?
在医疗领域,图像描述生成技术可用于辅助医生解读X光、CT等影像,生成初步的诊断报告草稿,提高诊疗效率,由于医疗数据的敏感性和准确性要求极高,目前主要处于辅助阶段,最终诊断仍需由专业医生确认,据行业共识认为,随着技术的成熟和监管政策的完善,其在医疗辅助诊断中的应用将更加广泛和深入。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/404916.html