多头注意力(MHA)通过多组独立的查询、键、值矩阵捕捉不同维度的语义特征,计算量大但精度高;而多查询注意力(MQA)共享所有头的键和值矩阵,大幅减少显存占用和推理延迟,牺牲少量精度换取极高的吞吐量,是2026年高并发场景下的主流选择。
MHA与MQA的核心架构差异解析
要理解这两者的区别,我们得先看看大模型在“思考”时到底在做什么,注意力机制就像是在阅读一篇文章时,你需要同时关注上下文的各种关联。
传统多头注意力的运作逻辑
在传统的MHA架构中,模型拥有多个独立的“注意力头”,每个头都有一套自己的查询(Query)、键(Key)和值(Value)权重矩阵。
- 独立计算:每个头独立计算注意力权重,这意味着模型可以从不同的子空间中提取信息,有的头可能关注语法结构,有的头关注实体关系。
- 全量存储:在生成文本时,KV Cache(键值缓存)需要为每个头、每个时间步保存完整的Key和Value向量。
- 计算瓶颈:随着模型层数加深和序列变长,KV Cache的大小呈线性增长,对于长文本处理,这会导致显存峰值极高,甚至出现OOM(显存溢出)。
业内专家指出,MHA的设计初衷是为了最大化模型的表达能力,但在实际部署中,这种“全副武装”往往造成了资源的浪费。
多查询注意力的简化策略
MQA的出现,本质上是为了解决MHA在推理阶段的显存瓶颈问题,它做了一件非常大胆的事:共享。
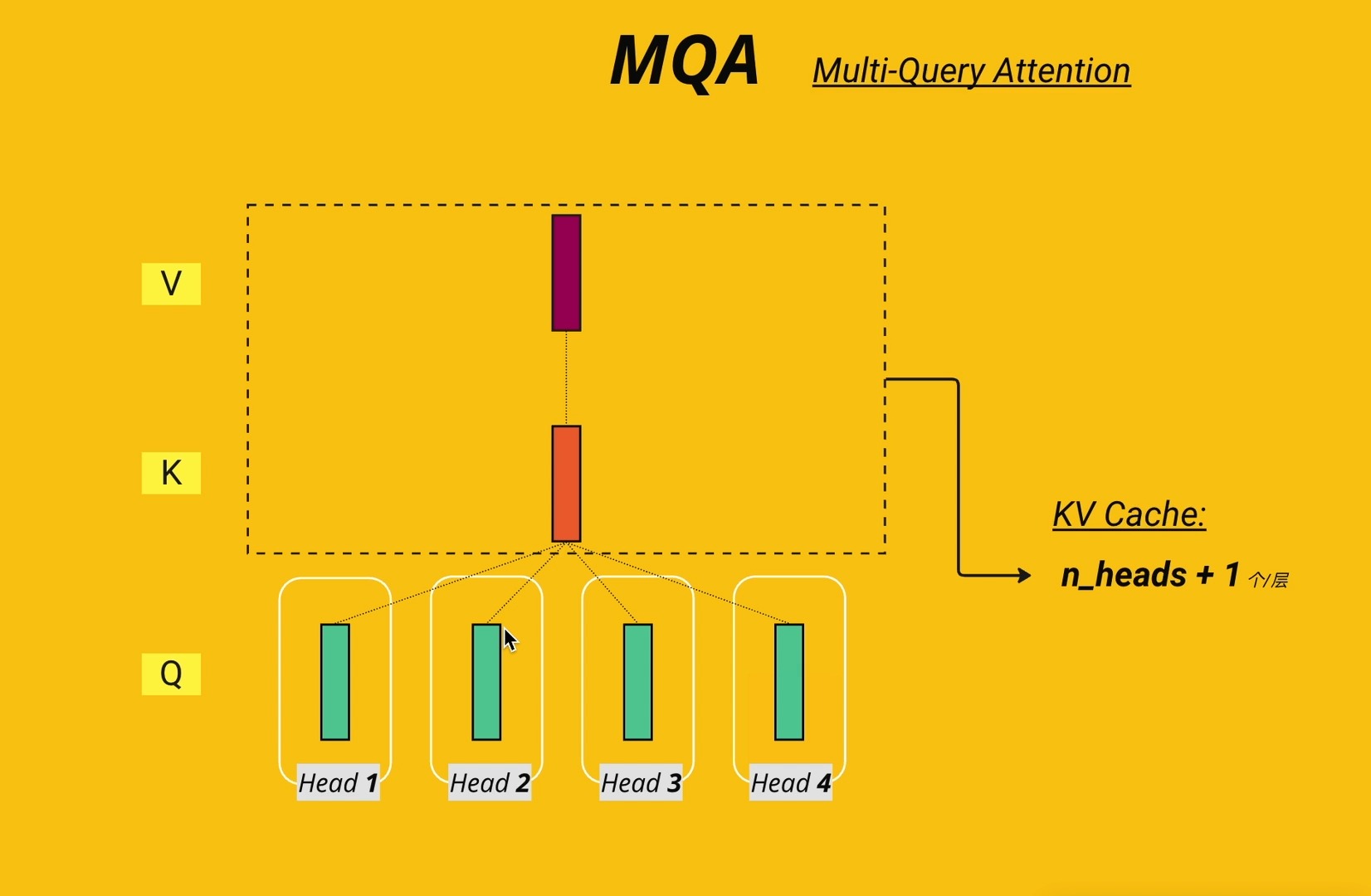
- 单组KV矩阵:MQA只保留一组Key和Value矩阵,所有注意力头共享这同一组KV。
- 多组Q矩阵:每个头依然拥有自己独立的Query矩阵,用于从共享的KV中提取不同的关注点。
- 显存优化:由于KV矩阵数量从N个(N为头数)减少到1个,KV Cache的体积直接缩减为原来的1/N。

这种设计让模型在推理时,内存带宽的压力大幅降低,据统计,在同等参数量下,MQA的推理速度通常比MHA快30%至50%,显存占用降低约80%。
性能对比与场景适配指南
选择MHA还是MQA,不是看谁更“高级”,而是看你的业务场景更需要什么,是追求极致的回答质量,还是追求极致的响应速度?
精度与速度的权衡
早期研究表明,MQA在牺牲极小精度的情况下,换来了巨大的速度提升。
- 精度损失:在复杂逻辑推理或极度专业的垂直领域,MQA可能比MHA稍逊一筹,因为共享KV限制了模型捕捉细微语义差异的能力。
- 速度优势:在对话生成、摘要提取等对实时性要求高的场景,MQA的优势明显,由于内存访问延迟(Memory Access Latency)是LLM推理的主要瓶颈,减少KV读取次数直接提升了吞吐量。
不同硬件环境的适配建议
对于开发者而言,硬件配置是决定选型的关键因素。
- 高端GPU集群(如A100/H100):显存充足,带宽极大,如果业务对答案的准确性要求极高,且并发量不大,MHA依然是稳妥之选。
- 边缘设备或低成本部署:在显存受限的设备(如消费级显卡、边缘服务器)上,MQA几乎是唯一选择,它能让原本跑不动的大模型“瘦身后”流畅运行。
- 高并发API服务:对于面向C端用户的聊天机器人,用户等待时间超过2秒流失率会显著上升,MQA的高吞吐量能更好地支撑高并发请求,降低单请求成本。

2026年主流模型的技术演进趋势
到了2026年,纯粹的MHA或MQA已不再是唯一的选项,混合架构成为行业共识。
分组查询注意力(GQA)的崛起
介于MHA和MQA之间,GQA(Grouped-Query Attention)成为了新的宠儿。
- 折中方案:GQA将多个头分组,每组共享一组KV矩阵,将128个头分为8组,每组16个头共享一组KV。
- 性能平衡:GQA在显存占用和推理速度上介于MHA和MQA之间,同时保持了接近MHA的模型精度。
- 实际应用:许多主流开源模型(如Llama系列后续版本、Qwen系列)在2026-2026年的迭代中,默认采用了GQA或类似变体,以平衡效果与效率。
量化与稀疏化的协同效应
除了注意力机制的改进,模型压缩技术也在进步。
- KV Cache量化:即使使用MHA,通过INT8或FP4量化KV Cache,也能显著降低显存占用。
- 稀疏注意力:仅计算部分关键位置的注意力,进一步减少计算量。
- 组合拳:MQA/GQA配合量化技术,使得在普通服务器上部署千亿级参数模型成为可能。
实操建议:如何选择合适的注意力机制
如果你正在选型或优化模型,以下路径可供参考。
第一步:明确业务SLA
- 如果首字延迟(TTFT)必须低于1秒,且并发QPS超过100,优先考虑MQA或GQA。
- 如果回答质量权重高于速度,且允许TTFT在2-3秒,MHA或GQA均可。

第二步:评估硬件资源
- 显存大于64GB且带宽充足:MHA/GQA。
- 显存小于24GB或带宽受限:MQA/GQA。
第三步:进行A/B测试
- 使用相同的提示词模板,在真实业务数据上对比MHA和MQA/GQA的输出质量。
- 关注指标:BLEU/ROUGE分数(自动化评估)和人工评分(逻辑一致性、事实准确性)。
- 多数情况下,GQA在精度损失小于1%的前提下,能提供50%以上的速度提升,是性价比最高的选择。
常见问题解答
MQA和MHA在训练阶段有区别吗?
在训练阶段,MQA和MHA的计算图略有不同,但差异不大,MQA由于共享KV,反向传播时的梯度计算路径更短,训练速度通常略快于MHA,由于共享参数可能导致梯度更新的不稳定,MQA通常需要更精细的学习率调整策略,业内共识认为,训练时的性能差异远小于推理时的差异,因此选型主要依据推理需求。
GQA是否完全取代了MQA?
GQA并未完全取代MQA,而是成为了更通用的解决方案,MQA作为GQA的一个极端特例(即所有头共享一组KV),在显存极度受限的场景下仍有价值,但在大多数商业场景中,GQA通过调整组数,能在精度和效率间找到更好的平衡点,因此被更广泛地采用。
如何判断我的模型是否适合使用MQA?
可以通过监控推理时的显存带宽利用率来判断,如果显存带宽长期处于饱和状态,且GPU计算单元空闲率较高,说明瓶颈在内存访问而非计算,将模型切换为MQA或GQA架构,能显著缓解带宽压力,提升整体吞吐量。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/412319.html










