在Access中查找不重复记录,最直接且高效的方法是利用“查询向导”中的“唯一值查询”功能,或者编写包含DISTINCT关键字的SQL语句,这能瞬间从海量数据中提炼出独立条目,彻底告别手动筛选的繁琐。
很多用户在使用Microsoft Access处理客户名单、订单记录或库存数据时,常遇到数据冗余的问题,重复的数据不仅占用存储空间,更会导致统计报表失真,业内专家指出,数据清洗是数据库管理中最基础也最关键的环节,而Access作为轻量级关系型数据库,其内置工具足以解决绝大多数去重需求,我们将通过实操路径,拆解几种主流方法,帮助你快速定位并提取不重复数据。
利用查询向导快速提取唯一值
对于不熟悉SQL语法的初学者,Access提供的图形化界面是最友好的选择,这种方法无需编写代码,通过鼠标点击即可完成数据过滤,适合处理结构清晰、字段较少的表格。
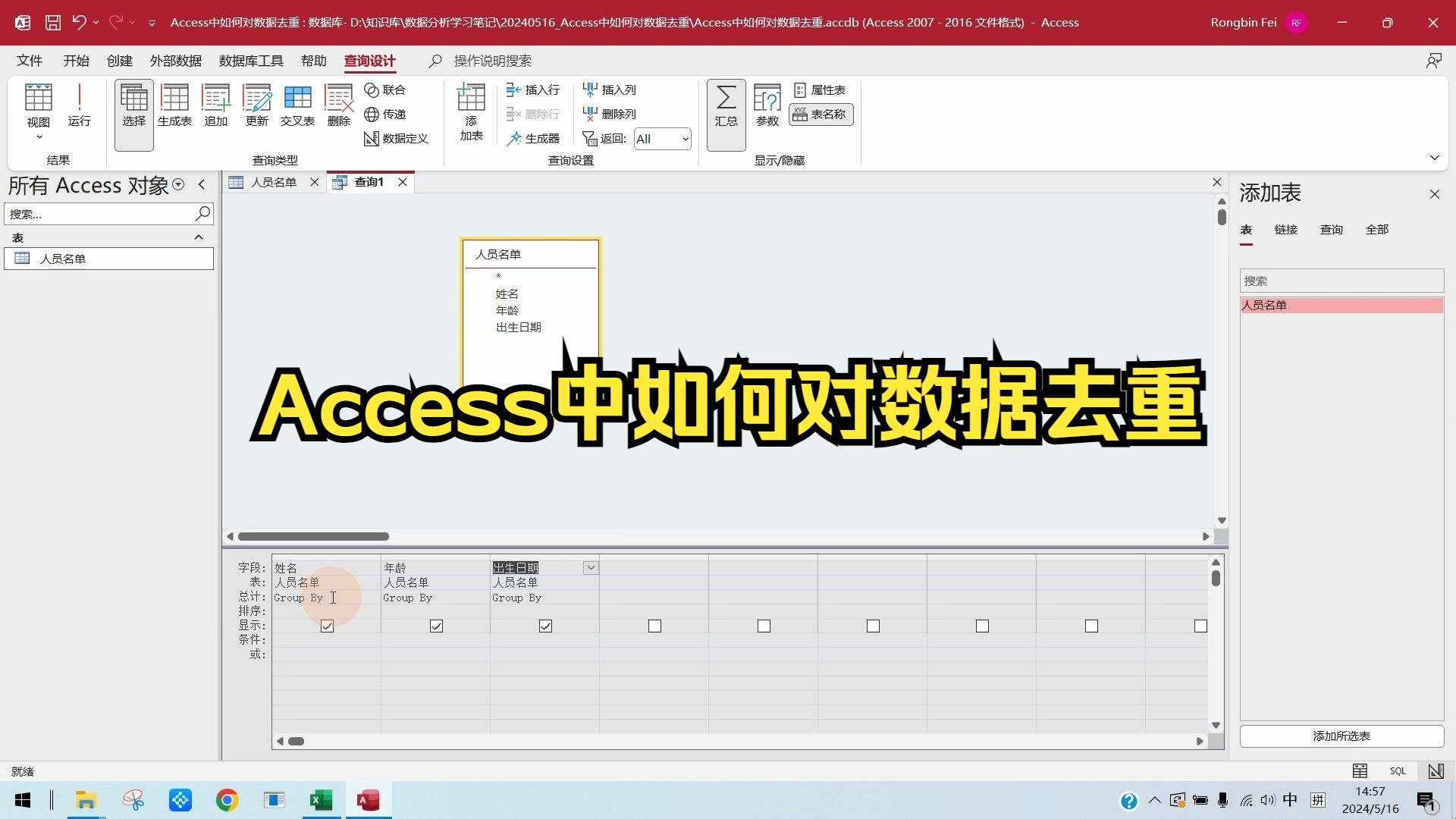
创建唯一值查询的具体步骤
操作路径非常直观,只需跟随以下步骤即可生成结果集:
- 打开你的Access数据库,点击顶部菜单栏的“创建”选项卡。
- 在“查询”组中,点击“查询向导”按钮。
- 在弹出的对话框中,选择“简单查询向导”,点击确定。
- 在“可用字段”列表中,勾选你需要检查重复性的字段,如果你只想找出唯一的“客户姓名”,就只选中该字段;如果需要组合判断(如姓名+电话),则同时选中这两个字段。
- 点击“下一步”,系统会询问是否要查看结果,点击“完成”。
- 关键步骤

:在生成的查询设计视图中,右键点击空白处,选择“属性”,在“属性”窗口中,找到“唯一值”选项,将其设置为“是”。
完成上述设置后,切换回“数据表视图”,你将看到所有重复的行已被自动过滤,仅保留每条记录的第一次出现,这种方法的优势在于即时生效,无需保存复杂的SQL逻辑,适合临时性数据查看。
适用场景与局限性
这种方法特别适用于Access查找不重复记录的日常办公场景,如整理员工花名册、清理邮件列表等,它也有明显的局限性,它只能提取字段值,无法保留重复记录中的其他详细信息(如最后一次更新的时间戳),如果数据量达到数万行以上,查询速度可能会略有延迟,但通常仍在可接受范围内。
SQL语句进阶:DISTINCT与GROUP BY的博弈
当数据量庞大或需要更复杂的逻辑判断时,SQL语句是更强大的工具,在Access中,你可以切换到SQL视图,直接编写代码,这里主要涉及两个核心命令:DISTINCT和GROUP BY。
DISTINCT:纯粹的去重筛选
DISTINCT关键字用于确保返回的每一行数据都是唯一的,它的逻辑简单直接:只要结果集中存在完全相同的行,就只保留一条。
以下代码用于从“订单表”中提取不重复的“产品ID”:
SELECT DISTINCT ProductID FROM Orders;
这条语句的执行效率极高,因为数据库引擎只需扫描一次数据流并进行哈希匹配,它适用于只需要获取唯一标识符的场景,比如生成下拉菜单选项或检查数据完整性。

GROUP BY:去重并聚合统计
如果你不仅想要不重复的记录,还想对重复项进行统计(如计算每个客户的订单总数),GROUP BY是更好的选择,它不仅能去重,还能结合聚合函数(如COUNT, SUM)提供额外信息。
SELECT CustomerID, COUNT(OrderID) as TotalOrders FROM Orders GROUP BY CustomerID;
这种写法在Access查询去重并统计的场景中极为常见,它解决了“DISTINCT无法进行聚合计算”的痛点,需要注意的是,SELECT子句中的非聚合字段必须包含在GROUP BY子句中,否则Access会报错。
高级技巧:处理复杂重复与性能优化
在实际业务中,重复数据往往不是完全一致的。“张三”和“张三 ”(多一个空格)在计算机眼中是两个不同的值,但在业务上却是同一个人,这时,简单的去重方法就会失效。
数据清洗前置处理
在进行去重操作前,建议先对数据进行标准化处理,可以使用TRIM()函数去除首尾空格,使用UPPER()或LOWER()统一大小写。
SELECT DISTINCT TRIM(UPPER(CustomerName)) FROM Customers;
这一步骤能显著降低误判率,确保Access数据库查找不重复数据的准确性。
索引对查询速度的影响
当数据量超过10万行时,查询速度成为关键瓶颈,业内共识认为,为用于去重的字段建立索引是提升性能的最佳实践,在Access中,你可以在表设计视图中,选中目标字段,将“索引”属性设置为“是(有重复)”或“是(无重复)”。

建立索引后,Access会使用B树结构快速定位数据,查询时间可从秒级降至毫秒级,但需注意,索引会增加写入数据时的开销,因此仅在频繁查询的字段上建立索引。
常见问题与误区解析
在处理Access去重任务时,用户常陷入一些思维误区,以下Q&A模块将澄清这些关键点,帮助你避开陷阱。
Q&A:Access查找不重复数据常见问题
Q1: 为什么我的查询结果中仍然有看似重复的记录?
A: 这通常是因为字段中存在不可见字符或数据类型差异,一个字段是文本型,另一个是数字型,即使内容相同,Access也视为不同,解决方法是使用`CStr()`或`CLng()`函数强制转换数据类型,或使用`Len()`函数检查字符串长度是否一致。
Q2: DISTINCT和GROUP BY哪个性能更好?
A: 在仅需要唯一值且无需聚合统计时,`DISTINCT`通常略快,因为它不需要维护聚合状态的内存开销,但在需要统计信息时,`GROUP BY`是必须的,其性能差异可忽略不计。
Q3: 如何删除重复记录而只保留一条?
A: 查询只能“查看”不重复数据,不能直接“删除”,要删除重复项,需先创建一个包含唯一ID的查询,然后基于此查询编写`DELETE`语句,或使用“删除重复项”的宏命令,操作前务必备份数据,以防误删。
通过上述方法,你可以灵活应对Access中的各种去重需求,无论是简单的名单整理,还是复杂的数据清洗,掌握这些核心技巧都能大幅提升工作效率,数据质量是决策的基石,而高效去重则是保障数据质量的第一道防线。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/440419.html