在Hive中删除数据库的标准命令是DROP DATABASE,若需强制删除包含表的数据库,必须添加CASCADE参数,否则默认采用RESTRICT模式仅允许删除空库。
Hive作为大数据生态中的核心数据仓库工具,其数据管理操作直接关系到集群资源的稳定性,许多初学者在操作时,往往因为不熟悉删除机制而导致命令执行失败,甚至误删数据,理解DROP DATABASE命令的底层逻辑和参数差异,是每一位数据工程师必须掌握的基本功。
Hive删除数据库的核心命令解析
在Hive命令行或客户端工具中,删除数据库并非简单的“一键清空”,而是一个带有保护机制的过程,默认情况下,Hive为了防止数据意外丢失,会阻止用户删除非空数据库。
基础语法结构
执行删除操作时,基本语法如下:
DROP DATABASE [IF EXISTS] database_name [RESTRICT | CASCADE];
这里包含几个关键要素:
- IF EXISTS:这是一个可选但强烈推荐的子句,加上它可以在数据库不存在时避免报错,使脚本更具健壮性。
- database_name:指定要删除的目标数据库名称。
- RESTRICT:这是默认行为,如果数据库中包含任何表(包括视图),命令将拒绝执行并抛出异常。
- CASCADE:强制删除模式,它会先删除数据库中的所有表和视图,然后再删除数据库本身。
RESTRICT与CASCADE的区别对比
业内专家指出,理解这两种模式的区别是避免生产事故的关键。
| 模式 | 行为描述 | 适用场景 | 风险等级 |
|---|---|---|---|
| RESTRICT | 仅当数据库为空时才删除 | 日常清理废弃的空库 | 低 |
| CASCADE | 先删表,再删库 | 彻底重构数据架构 | 高 |

如果使用了CASCADE,Hive会递归地删除该数据库下的所有元数据记录以及HDFS上的物理数据文件,一旦执行,数据将无法通过Hive层面恢复,在执行此操作前,务必确认备份策略已就绪。
常见报错场景与解决方案
在实际运维中,直接执行DROP DATABASE经常遇到阻碍,以下是几种典型场景及其解决路径。
数据库非空导致拒绝删除
这是最常见的错误,当你尝试删除一个包含表的数据库时,Hive会返回类似Exception: Database xxx is not empty的提示。
解决方案:
- 手动删除所有表:
USE database_name; DROP TABLE IF EXISTS table1; DROP TABLE IF EXISTS table2; -- 重复直到所有表删除 DROP DATABASE database_name;
- 或者直接使用级联删除(需谨慎):
DROP DATABASE database_name CASCADE;
权限不足
如果当前用户没有该数据库的DROP权限,命令将失败,Hive基于Ranger或ACL进行权限控制,确保只有管理员或所有者能执行破坏性操作。
解决方案:
联系集群管理员授予相应权限,或使用具有ADMIN权限的账户执行。
HDFS文件残留
有时,虽然Hive元数据中的数据库和表已被删除,但HDFS上仍残留数据文件,这通常发生在

CASCADE删除过程中HDFS操作超时或中断时。
解决方案:
手动检查HDFS路径,通常位于/user/hive/warehouse/database_name,确认无误后使用hdfs dfs -rm -r命令清理残留文件。
删除操作的最佳实践
为了保障数据安全,建议遵循以下操作流程。
执行前的数据备份
在执行DROP DATABASE ... CASCADE之前,务必对重要数据进行备份,可以使用EXPORT命令将数据导出到HDFS指定目录:
EXPORT TABLE table_name TO '/backup/path/table_name';
这样可以保留数据的元数据和实际内容,便于后续恢复。
使用IF EXISTS增强脚本兼容性
在编写自动化脚本时,始终加上IF EXISTS。
DROP DATABASE IF EXISTS temp_db CASCADE;
这样可以避免在数据库已不存在时脚本中断,提高批处理任务的稳定性。
区分测试环境与生产环境
在测试环境中,可以频繁使用CASCADE进行快速迭代,但在生产环境中,建议采用手动分步删除的方式,先确认无依赖关系,再执行删除,这种保守策略能有效防止因脚本错误导致的大规模数据丢失。
Hive删除数据库与其他数据仓库的对比
不同的大数据工具在删除操作上的逻辑存在差异,了解这些差异有助于跨平台迁移或混合架构管理。
Hive vs. Spark SQL
Spark SQL兼容Hive语法,因此DROP DATABASE命令在两者中行为一致,但Spark更侧重于内存计算,其临时视图的删除机制与Hive持久化表不同,在Spark中删除持久化表同样需要处理CASCADE问题。
Hive vs. MySQL
MySQL的

DROP DATABASE默认行为类似于Hive的CASCADE,即直接删除库及其所有表,除非显式指定选项,Hive的默认RESTRICT机制更为安全,体现了数据仓库对数据完整性的高要求。
Hive vs. HBase
HBase的表删除是即时生效的,且没有类似Hive的元数据保护机制,Hive作为元数据管理层,其删除操作涉及元数据表和HDFS文件的双重清理,复杂度更高。
Q&A:关于Hive删除数据库的常见疑问
Hive删除数据库命令执行后数据还能恢复吗?
如果使用了CASCADE参数,Hive会同时删除元数据和HDFS物理文件,默认情况下无法直接恢复,若未删除HDFS文件,仅删除元数据,可以通过重新导入或手动注册表的方式恢复部分数据,但这需要极高的技术成本和运气,事前备份是唯一可靠的恢复手段。
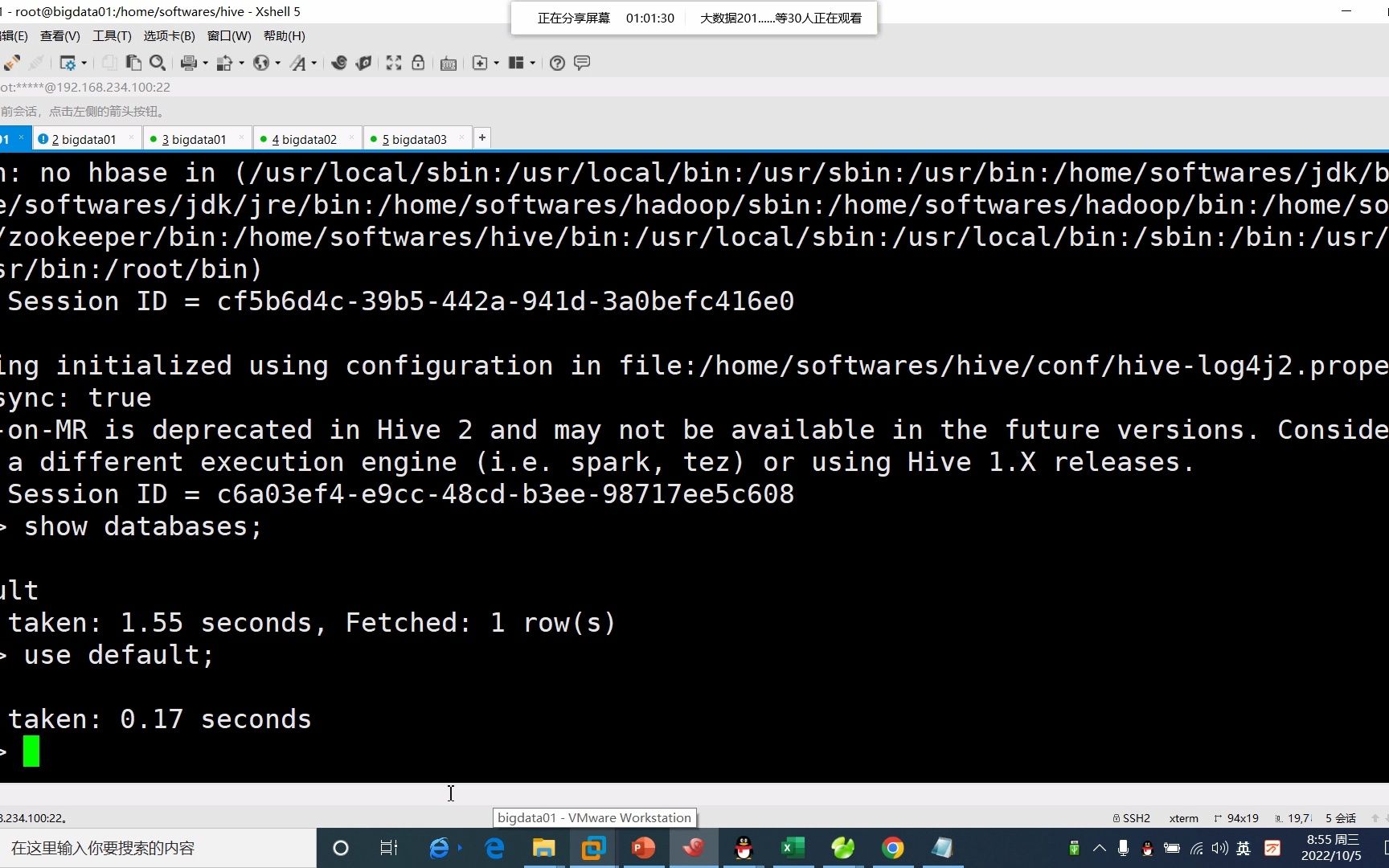
如何查看Hive中所有数据库及其状态?
在执行删除前,建议先列出所有数据库以确认目标,使用SHOW DATABASES;命令可以列出当前用户可见的所有数据库,若需查看详细信息,可结合DESCRIBE DATABASE extended database_name;命令,查看数据库的描述、位置及创建时间,辅助判断是否可安全删除。
Hive中删除数据库会影响其他用户吗?
如果其他用户正在查询该数据库中的表,删除操作可能会失败或导致查询中断,Hive支持并发控制,但DROP DATABASE是DDL操作,会锁定元数据,建议在业务低峰期执行,并确保没有活跃会话依赖该数据库,若存在依赖,需先终止相关会话或等待查询完成。
掌握DROP DATABASE命令的正确用法,不仅能提升数据管理效率,更能规避数据丢失风险,在实际操作中,始终遵循“先备份、再确认、后执行”的原则,确保大数据平台的安全稳定运行。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/441168.html