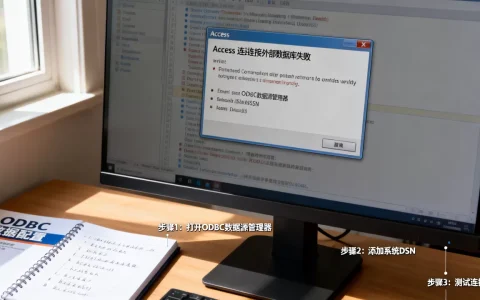
在云测试平台中,通过“CreateTMSSCaseAndCopyScript”接口实现测试用例与脚本的一键复制,是提升自动化测试效率、降低重复劳动成本的核心解决方案,尤其适用于大规模回归测试场景。
随着软件迭代周期的不断缩短,测试团队面临着巨大的用例维护压力,传统的逐条复制、手动关联脚本的方式不仅耗时,还极易引入人为错误,引入标准化的接口调用机制,如CreateTMSSCaseAndCopyScript,能够从根本上解决这一痛点,它不仅仅是一个简单的复制功能,而是将测试资产的管理从“手工操作”升级为“自动化编排”,确保用例与脚本之间的一致性、完整性和可追溯性。

为什么选择接口级用例复制而非手动操作?
在早期的测试管理实践中,测试人员往往依赖图形界面进行手动复制,这种方式在少量用例时尚可接受,但当用例数量达到数百甚至数千条时,效率瓶颈便暴露无遗,业内专家指出,手动操作在处理批量任务时,错误率通常随着数据量的增加呈指数级上升,相比之下,通过API接口进行批量处理,能够保证操作的原子性和事务性,要么全部成功,要么全部回滚,极大地提升了数据的可靠性。
效率对比:分钟级任务与小时级任务的差距
让我们通过一个具体的场景来对比两种方式的差异,假设你需要将一套包含500个核心业务场景的测试用例,从“Sprint A”环境复制到“Sprint B”环境,并关联对应的Python自动化脚本。
- 手动操作模式:测试人员需要逐个打开用例详情,点击复制,然后逐个进入脚本管理界面,重新绑定脚本ID,即使使用快捷键,完成这一过程也需要至少2-3小时,且期间需要频繁切换窗口,注意力极易分散。
- 接口调用模式:编写一个简单的脚本,调用CreateTMSSCaseAndCopyScript接口,传入源用例ID列表和目标环境参数,整个过程通常在30秒内即可完成,且无需人工干预。
这种效率的提升并非仅仅体现在时间节省上,更体现在对测试资源的优化配置上,测试人员可以将节省下来的时间投入到更复杂的探索性测试或测试用例的设计优化中,而非陷入机械性的复制粘贴工作中。

一致性保障:避免“孤儿脚本”的产生
在手动复制过程中,最常见的错误是“只复制了用例,忘记复制脚本”,或者“复制了用例,但脚本关联错误”,这会导致测试执行时出现“孤儿脚本”或“空壳用例”,严重影响测试结果的准确性,通过接口调用,系统会在底层自动校验用例与脚本的关联关系,确保每一处复制操作都伴随着正确的脚本映射,这种强一致性保障,是手动操作难以企及的。
CreateTMSSCaseAndCopyScript 接口核心逻辑解析
要充分利用这一功能,理解其背后的技术逻辑至关重要,该接口的核心在于“映射”与“转换”,它不仅仅是数据的简单拷贝,更涉及ID的重写、环境变量的替换以及依赖关系的重建。
输入参数与数据校验
调用该接口时,通常需要传入以下关键参数:
- source_project_id:源项目ID,用于定位原始用例和脚本。
- target_project_id:目标项目ID,指定复制后的用例存放位置。
- case_ids:需要复制的用例ID列表,支持批量操作。
- script_mapping:可选参数,用于指定脚本的映射规则,如果未提供,系统默认尝试根据名称或标签自动匹配。
在数据校验阶段,系统会检查源用例是否存在、目标项目是否有权限写入、以及脚本是否满足运行环境要求,任何一项校验失败,都会导致整个批次复制失败,并返回详细的错误信息,便于调试。
执行流程与事务管理
接口的执行流程通常分为三个步骤:
- 预检查:验证权限、资源可用性及数据完整性。
- 数据转换:将源数据转换为目标环境所需格式,重写ID,替换环境变量。
- 持久化存储:将转换后的数据写入目标数据库,并更新索引。

为了确保数据一致性,整个过程被包裹在一个事务中,如果在第三步发生异常,系统会自动回滚前两步的操作,确保目标环境不会出现半成品的数据,这种事务管理机制,是保障大规模数据操作安全性的基石。
实战场景:如何落地实施用例脚本批量复制?
理论再好,最终都要落地到实际操作中,以下是一个典型的Python调用示例,展示如何通过代码实现用例与脚本的批量复制。
代码实现示例
import requests
import json
def copy_cases_and_scripts(source_pid, target_pid, case_ids):
url = "https://api.your-cloud-test-platform.com/v1/case/copy"
headers = {
"Authorization": "Bearer YOUR_ACCESS_TOKEN",
"Content-Type": "application/json"
}
payload = {
"source_project_id": source_pid,
"target_project_id": target_pid,
"case_ids": case_ids,
"copy_script": True, # 关键参数:是否同时复制脚本
"auto_map_script": True # 关键参数:是否自动映射脚本
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
result = response.json()
print(f"复制成功,新用例ID列表: {result.get('new_case_ids')}")
else:
print(f"复制失败: {response.text}")
# 调用示例
copy_cases_and_scripts("proj_123", "proj_456", ["case_001", "case_002", "case_003"])
在这个示例中,copy_script和auto_map_script是两个至关重要的参数,前者确保脚本数据被一同复制,后者则利用智能算法,根据用例名称、步骤描述等特征,自动寻找最匹配的脚本进行关联,大大降低了人工配置的成本。
常见问题与排查指南
在实际操作中,可能会遇到一些常见问题,以下是排查思路:
- 脚本关联失败:检查源用例与脚本的命名规范是否一致,或尝试手动指定script_mapping参数。
- 权限不足:确认当前账号对目标项目是否具有“写入”和“编辑”权限。
- 数据量过大导致超时:建议将大批量用例拆分为多个小批次,每批次不超过100条,以提高成功率。

行业趋势与未来展望
随着AI技术在测试领域的深入应用,用例复制的功能也在不断进化,未来的趋势将不仅仅是简单的“复制”,而是“智能重构”。
智能语义匹配与自适应复制
行业共识认为,基于自然语言处理(NLP)的智能匹配将成为标配,系统不仅能根据ID或名称匹配脚本,还能理解用例步骤的语义,自动推荐最合适的脚本片段进行组合,这意味着,即使源脚本需要微调,AI也能辅助生成适配新场景的脚本代码,进一步降低维护成本。
跨平台无缝迁移
跨平台的无缝迁移也是重要方向,通过标准化的接口定义,如CreateTMSSCaseAndCopyScript,测试团队可以轻松地将用例资产从本地测试管理工具迁移到云端平台,或在不同云厂商之间进行迁移,打破数据孤岛,实现资产的自由流动。
Q&A:CreateTMSSCaseAndCopyScript 常见问题解答
CreateTMSSCaseAndCopyScript 接口是否支持增量复制?
是的,该接口支持增量复制,通过传入特定的时间戳或版本号参数,系统可以仅复制自上次同步以来新增或修改的用例及脚本,避免重复数据传输,提高同步效率。
复制后的脚本是否会自动更新变量?
默认情况下,系统会保留原始脚本中的变量定义,如果目标环境与源环境存在差异,建议在调用接口后,通过后续的变量管理接口进行批量替换,以确保脚本在目标环境中能正确执行。
该接口的调用频率限制是多少?
根据平台不同,调用频率限制有所差异,多数主流云测试平台对免费用户限制为每分钟100次,对企业用户则提供更高的配额,建议在高并发场景下,采用批量提交的方式,减少接口调用次数,以提高整体吞吐量。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/441930.html