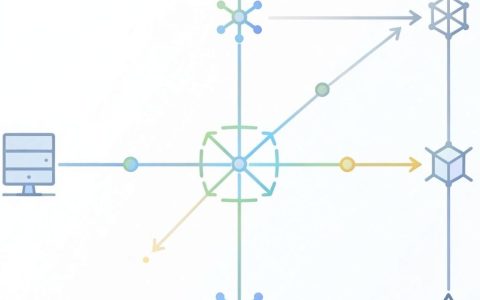
Access数据库表的内容在逻辑上呈现为二维矩阵结构,即由行(记录)和列(字段)交叉构成的离散数据集合,这是关系型数据库最基础且核心的数据组织形式。
很多人提到Access,第一反应是“老旧”或者“只能做小项目”,这种刻板印象其实忽略了其底层逻辑的严谨性,当你打开一个Access表,看到那些整齐排列的单元格时,你看到的不仅仅是一堆数据,而是一个标准的数学矩阵,每一行代表一个实体,每一列代表实体的一个属性,这种结构决定了Access在处理简单关系型数据时的效率与局限,理解这一点,是避免在开发小型管理系统时踩坑的关键。
Access表作为矩阵的结构解析
要真正驾驭Access,必须跳出“电子表格”的思维定势,转而用“矩阵”的视角去审视数据,虽然Access的界面和Excel很像,但两者的内核完全不同,Excel是自由画布,而Access是严格约束的矩阵。
行与列的严格定义
在Access的矩阵中,列(Column)被称为字段(Field),它定义了数据的类型和约束,姓名”字段必须是文本,“入职日期”必须是日期/时间,这种强类型约束是矩阵稳定性的基石,如果试图在日期字段中输入文字,Access会直接拒绝,这就像在数学矩阵中填入非法元素一样,会导致整个结构崩溃。
行(Row)则被称为记录(Record),每一行代表一个独立的数据对象,在矩阵视角下,每一行都是一个向量,包含了该对象在所有维度上的取值,员工表中的一行,就是该员工在姓名、年龄、部门、薪资等所有字段上的具体取值组合。
主键:矩阵的唯一标识符
在一个标准的矩阵中,行与行之间应该是可区分的,在Access中,主键(Primary Key)起到了这个作用,它确保每一行都是唯一的,就像矩阵中的索引一样,没有主键,Access的矩阵就会失去其关系型数据库的核心价值关联能力。

为什么矩阵思维能解决90%的数据混乱?
很多初学者在使用Access时,喜欢把多个表的信息合并到一个大表中,试图用Excel的方式处理数据,这种做法看似方便,实则违背了矩阵的规范化原则,导致了数据冗余和更新异常。
第一范式:消除重复组
业内专家指出,关系型数据库的第一范式(1NF)要求表中的每个字段都不可再分,在矩阵中,这意味着每个单元格只能包含一个原子值,如果你在一个单元格中存储“北京,上海,广州”三个城市,你就破坏了矩阵的结构,正确的做法是建立一个新的矩阵(表),将城市作为单独的行存储,并通过外键与原表关联。
数据冗余与更新异常
当矩阵结构被破坏时,数据冗余随之而来,假设你在员工表中直接存储了部门名称和部门经理,那么当部门经理变更时,你需要更新所有属于该部门的员工记录,这不仅效率低下,还极易出错,通过引入“部门表”作为独立的矩阵,并利用外键进行关联,你只需要更新一次部门表,所有关联的员工记录都能通过查询动态反映最新信息。
查询:矩阵的运算操作
Access的查询功能,本质上是对多个矩阵进行集合运算,选择查询是投影操作,筛选查询是选择操作,而关联查询则是矩阵的笛卡尔积与连接操作,理解这一点,你就能明白为什么复杂的查询会消耗大量资源,以及如何通过优化索引来提升查询速度。
Access矩阵在2026年的应用场景与价格考量
尽管云数据库和SaaS应用盛行,但Access矩阵结构在特定场景下依然具有不可替代的价值,特别是在数据敏感、网络不稳定或预算有限的场景中,Access的本地化矩阵存储优势明显。
本地化小型管理系统
对于初创团队或小型工作室,Access数据库本地部署方案是一个高性价比的选择,它不需要复杂的服务器配置,数据直接存储在本地硬盘上,访问速度极快,对于年数据量在百万级以下的场景,Access的矩阵处理能力完全足够。

数据原型快速验证
在开发大型系统之前,使用Access构建数据矩阵原型,可以快速验证数据结构的合理性,由于Access的界面友好,业务人员可以直接查看和修改数据,这种即时反馈机制是许多高级数据库所不具备的。
Access与其他数据库的对比
| 特性 | Access (矩阵结构) | MySQL (关系型) | Excel (电子表格) |
|---|---|---|---|
| 数据并发 | 低,适合单用户或少量并发 | 高,支持多用户并发访问 | 极低,易冲突 |
| 数据安全性 | 中等,依赖文件权限 | 高,支持细粒度权限控制 | 低,易被篡改 |
| 扩展性 | 有限,数据量大后性能下降 | 极强,支持分布式集群 | 无,受限于内存 |
| 学习成本 | 低,界面直观 | 中高,需掌握SQL | 低,人人会用 |
实操指南:如何构建规范的Access矩阵
要构建一个健壮的Access矩阵,需要遵循以下步骤,确保数据结构的规范性和可维护性。
第一步:需求分析与实体识别

在创建表之前,先列出所有需要存储的数据实体,对于一个图书管理系统,实体可能包括“图书”、“读者”、“借阅记录”,每个实体对应一个矩阵(表)。
第二步:定义字段与数据类型
为每个实体定义字段,注意选择合适的数据类型,如使用“自动编号”作为主键,使用“是/否”表示布尔值,使用“货币”表示金额,避免使用“文本”类型存储所有数据,这会导致查询效率低下。
第三步:建立关系与外键
通过“关系”窗口,将各个矩阵连接起来。“借阅记录”表中的“读者ID”应关联到“读者”表的主键,这种关联确保了数据的参照完整性,防止出现“孤儿记录”。
第四步:索引优化
对经常用于查询和排序的字段建立索引,索引相当于矩阵的目录,能显著加快数据检索速度,但要注意,索引过多会影响写入性能,需根据实际查询需求进行平衡。
常见问题解答
Access数据库表的内容是矩阵吗?
是的,Access数据库表在逻辑结构上完全符合二维矩阵的定义,它由行(记录)和列(字段)组成,每个交叉点存储一个原子值,这种结构使得Access能够高效地进行数据检索、排序和关联操作,是关系型数据库理论的典型实现。
Access矩阵结构适合大数据量吗?
不适合,Access基于Jet/ACE引擎,其矩阵处理能力在数据量超过几十万条记录时会显著下降,对于大数据量场景,建议迁移至SQL Server或MySQL等支持分布式架构的关系型数据库,以获得更好的性能和扩展性。
如何将Excel数据导入Access矩阵?
可以通过Access的“外部数据”选项卡,选择“Excel”作为数据源,按照向导逐步完成导入,导入过程中,需仔细检查数据类型映射,确保Excel中的文本、日期等格式正确转换为Access的字段类型,以避免数据丢失或格式错误。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/442161.html