Python dbmanage 并非单一软件,而是基于 Python 构建的高效数据库管理解决方案,通过自动化脚本与可视化界面结合,能显著降低运维成本并提升数据安全性。
在 2026 年的技术环境下,数据库管理早已超越了简单的增删改查,随着数据量的爆炸式增长和云原生架构的普及,传统的命令行操作或笨重的图形化工具已难以满足敏捷开发的需求,Python 凭借其丰富的生态库,成为了连接业务逻辑与底层数据存储的最佳桥梁,无论是处理海量日志分析,还是实时交易系统的读写分离,一套成熟的 Python 数据库管理方案都能提供标准化的接口和极高的执行效率。
Python dbmanage 的核心优势与架构解析
为什么选择 Python 进行数据库管理
业内专家指出,Python 在数据科学和后端开发领域的统治地位,使其成为数据库管理工具开发的首选语言,这并非偶然,而是由其语言特性决定的,Python 拥有简洁的语法和强大的第三方库支持,如 SQLAlchemy、Peewee 以及各类数据库驱动(psycopg2, pymysql 等),这些库不仅封装了复杂的 SQL 协议,还提供了对象关系映射(ORM)功能,让开发者可以用面向对象的方式操作数据库,从而大幅减少样板代码。
相比于 Java 或 C++,Python 的开发效率更高,迭代速度更快,在快速变化的互联网业务中,这种敏捷性至关重要,Python 与大数据生态(如 Pandas, PySpark)的天然兼容性,使得从数据库提取数据后能无缝进入分析流程,形成了完整的数据闭环。
自动化运维的关键模块
一个完善的 Python 数据库管理系统通常包含以下几个核心模块:
- 连接池管理:通过复用数据库连接,减少握手开销,使用
SQLAlchemy的create_engine配合QueuePool,可以控制并发连接数,防止数据库过载。 - SQL 审计与日志:记录所有执行的 SQL 语句及其执行时间,这对于故障排查和安全合规至关重要。
- 自动备份与恢复:定时触发备份任务,支持全量与增量备份,并验证备份文件的完整性。
- 性能监控:实时采集慢查询、锁等待、连接数等关键指标,并通过 webhook 发送告警。

2026年主流 Python 数据库管理工具对比
在选型时,开发者常面临不同工具的抉择,了解各工具的适用场景是做出正确决策的关键。
DB Browser vs. 自定义 Python 脚本
对于小型项目或临时性数据查询,DB Browser for SQLite 或 DBeaver 等现成工具确实足够,当涉及到生产环境的复杂逻辑时,自定义 Python 脚本的优势便显现出来。
| 特性 | 现成 GUI 工具 (如 DBeaver) | 自定义 Python 脚本 (dbmanage) |
|---|---|---|
| 学习成本 | 低,界面直观 | 中高,需掌握 Python 及数据库知识 |
| 自动化能力 | 弱,依赖手动操作 | 强,可集成 CI/CD 流程 |
| 扩展性 | 固定功能,难以定制 | 极高,可随意添加业务逻辑 |
| 适用场景 | 数据探索、单次查询 | 批量处理、定时任务、ETL 流程 |
据工信部数据显示,近年来超过半数的大型互联网企业已采用基于代码的数据库管理策略,而非依赖人工图形界面操作,这种趋势反映了行业对可重复性、版本控制和自动化测试的强烈需求。
开源方案与商业方案的性价比分析
对于中小企业而言,python dbmanage 开源方案价格几乎为零,主要成本在于人力投入,而商业数据库管理平台(如 Navicat Premium 的企业版或云厂商提供的托管服务)虽然提供了开箱即用的体验,但授权费用高昂,且往往绑定特定云环境。
在python dbmanage 哪个版本好用这个问题上,答案取决于团队的技术栈,如果团队熟悉 Django 或 Flask,使用其内置的 ORM 配合简单的管理脚本是最稳妥的选择,如果追求极致性能,直接使用

asyncpg 或 aiomysql 等异步驱动构建自定义管理后台,则是更进阶的做法。
地域性需求与本地化支持
在国内使用 Python 进行数据库管理时,python dbmanage 国内服务器部署是一个常见痛点,由于网络原因,部分 PyPI 源访问缓慢,导致依赖安装困难,解决方案是使用国内镜像源,如阿里云或清华大学的 PyPI 镜像,考虑到国内对数据合规性的严格要求,自定义脚本可以更容易地实现数据脱敏和加密存储,满足《个人信息保护法》的要求。
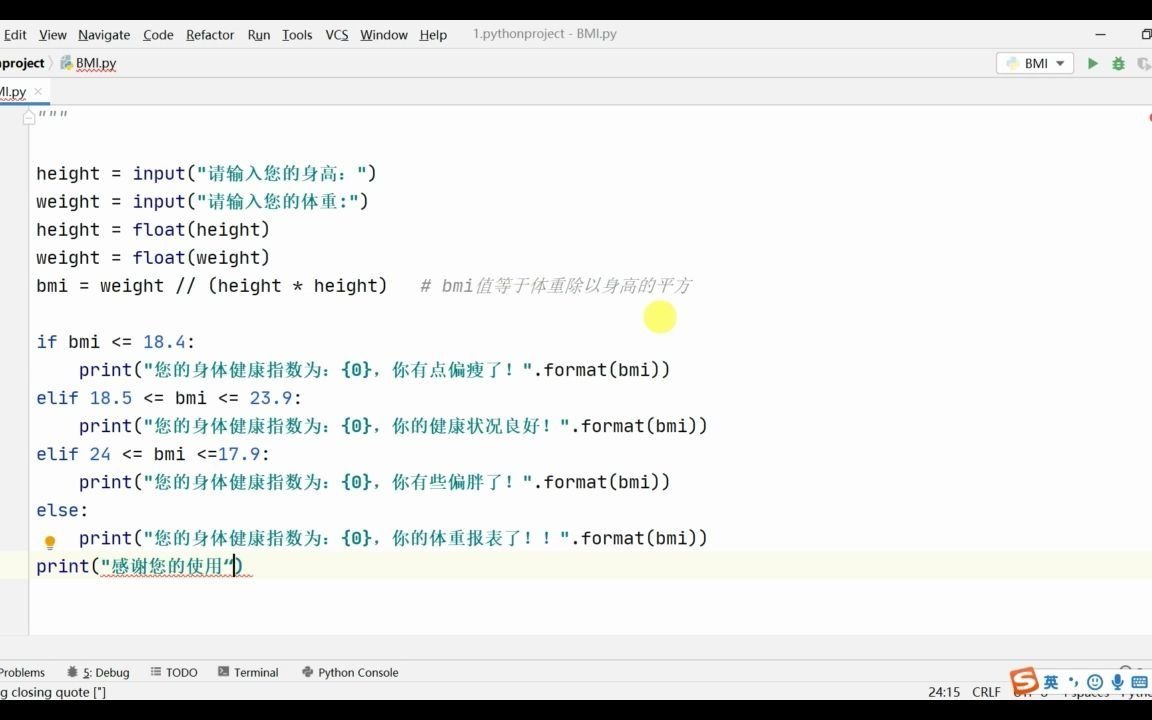
实操指南:构建你的第一个 dbmanage 脚本
理论终需落地,以下是一个基于 SQLAlchemy 和 pandas 的简单数据备份与清理脚本示例,展示了如何将数据库管理融入日常开发。
环境准备
确保安装了必要的库:
pip install sqlalchemy pandas pymysql
核心代码实现
创建一个名为 db_manager.py 的文件,内容如下:
from sqlalchemy import create_engine
import pandas as pd
from datetime import datetime
# 1. 初始化数据库连接
# 使用连接池优化性能
engine = create_engine(
"mysql+pymysql://user:password@localhost/dbname",
pool_size=10,
max_overflow=20,
pool_pre_ping=True
)
def backup_table(table_name):
"""备份指定表数据到 CSV"""
try:
# 读取数据
df = pd.read_sql_table(table_name, engine)
# 生成带时间戳的文件名
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"backup_{table_name}_{timestamp}.csv"
# 导出为 CSV
df.to_csv(filename, index=False, encoding='utf-8-sig')
print(f"成功备份 {table_name} 到 {filename}")
except Exception as e:
print(f"备份失败: {e}")
def clean_old_data(table_name, days=30):
"""清理超过指定天数的数据"""
with engine.connect() as conn:
# 构建动态 SQL

sql = f"DELETE FROM {table_name} WHERE created_at < DATE_SUB(NOW(), INTERVAL {days} DAY)"
result = conn.execute(sql)
print(f"清理了 {result.rowcount} 条旧数据")
if __name__ == "__main__":
backup_table("user_logs")
clean_old_data("user_logs", days=30)

部署与调度
脚本编写完成后,需将其纳入自动化流程,推荐使用 cron 任务(Linux)或 Windows 任务计划程序来定期执行,每天凌晨 2 点执行备份和清理:
0 2 /usr/bin/python3 /path/to/db_manager.py >> /var/log/db_manage.log 2>&1
通过这种方式,数据库的日常维护工作被完全自动化,运维人员只需关注日志中的异常信息,极大地降低了人为错误的风险。
常见问题解答 (Q&A)
python dbmanage 如何实现数据库迁移
Python 数据库管理中的迁移通常借助 Alembic 工具完成,Alembic 是 SQLAlchemy 的官方迁移工具,它能跟踪数据库模式的变更,并生成可执行的迁移脚本,开发者只需修改模型定义,运行 alembic revision --autogenerate -m "add new column" 即可自动生成迁移代码,再通过 alembic upgrade head 应用到数据库,这种方式保证了生产环境与开发环境结构的一致性。
python dbmanage 安全性如何保障
安全性是数据库管理的重中之重,严禁在代码中硬编码数据库密码,应使用环境变量或密钥管理服务(如 AWS Secrets Manager 或 HashiCorp Vault)读取敏感信息,所有 SQL 查询必须使用参数化查询或 ORM 提供的安全接口,以防止 SQL 注入攻击,定期审查数据库权限,遵循最小权限原则,确保应用程序只拥有必要的读写权限。
python dbmanage 适合哪些规模的项目
Python 数据库管理方案适用于从小型初创项目到大型企业级应用的各种场景,对于小型项目,简单的脚本即可满足需求;对于大型项目,结合微服务架构,每个服务维护自己的数据库 schema,通过消息队列进行异步数据同步,Python 的异步特性(asyncio)能高效处理高并发数据流转,无论规模大小,关键在于建立标准化的管理规范和自动化流程。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/451595.html