Linux内核死机通常由硬件故障、驱动程序冲突或内核代码缺陷引发,排查核心在于分析Oops日志、Kdump转储文件及硬件健康状态。
当服务器或嵌入式设备突然黑屏、终端无响应或重启时,这种状态在业内被称为Kernel Panic或Oops,这不仅仅是系统的“感冒”,而是内核失去了对硬件或内存的控制权,对于运维工程师和开发者而言,面对这种瞬间的崩溃,恐慌无济于事,冷静地提取现场证据才是解决问题的关键。
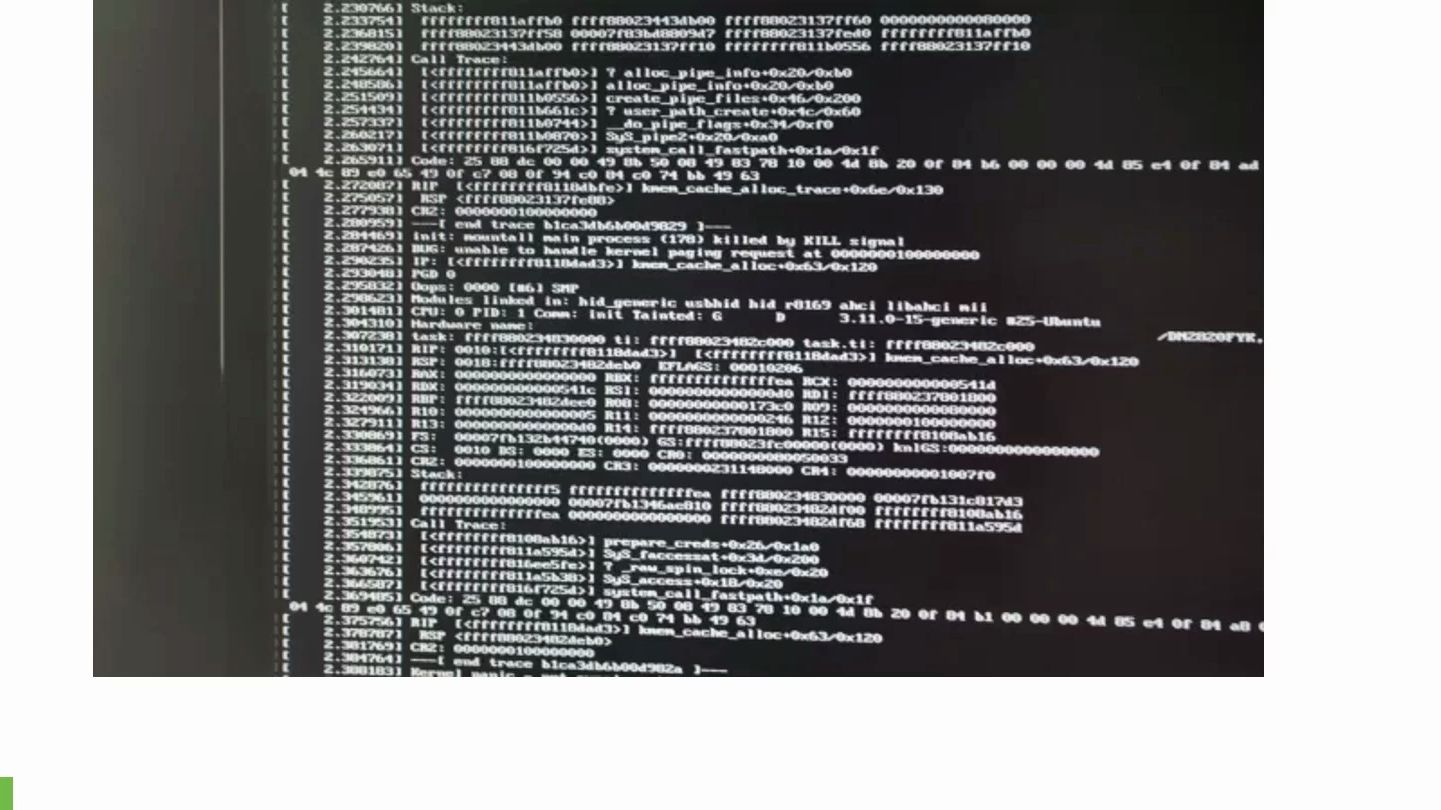
Linux内核死机常见原因深度解析
内核作为操作系统的核心,负责管理进程、内存、设备和文件系统,一旦它出错,整个系统就会陷入瘫痪,理解死机的根源,是预防再次发生的前提。
硬件故障引发的底层崩溃
硬件问题是导致Linux内核死机的第一大诱因,尤其是在高负载的生产环境中。
内存错误与数据损坏
内存(RAM)是内核最敏感的区域,如果内存条出现物理损坏或位翻转,内核在读写关键数据结构时会获取到错误数据,导致指针指向非法地址。
ECC内存的重要性:服务器通常配备ECC内存来纠正单比特错误,但无法防止多比特错误。
症状表现:随机性的段错误(Segmentation Fault)或无法预测的内核恐慌。
排查手段:使用`memtest86+`进行长时间的压力测试,检查系统日志中是否有`MCE`(Machine Check Exception)记录。
存储设备I/O异常
当内核试图访问磁盘上的关键文件系统元数据或驱动程序时,如果磁盘出现坏道或控制器响应超时,内核可能会挂起等待,最终触发超时死机。
常见场景:RAID卡电池失效导致写缓存关闭,磁盘性能骤降,进而引发I/O等待死锁。
验证方法:检查`dmesg`输出,寻找`I/O error`或`EXT4-fs error`等关键词。
驱动程序与内核模块冲突
第三方驱动程序是Linux内核稳定性的最大变量,许多硬件厂商提供的驱动并非完全开源,且缺乏严格的内核API兼容性测试。
- 版本不匹配:升级内核版本后,旧版驱动可能调用已废弃的内核接口,导致空指针解引用。
- 资源竞争:多个驱动同时请求中断或锁资源,引发死锁(Deadlock)。
- 专有驱动风险:NVIDIA显卡驱动或某些网卡驱动在特定负载下容易引发内核态崩溃。

内核代码缺陷与并发问题
即使是主线内核,也可能存在未被发现的Bug,特别是在多核处理器环境下,竞态条件(Race Condition)极难复现。
- 竞态条件:两个进程同时修改同一共享变量,导致数据不一致。
- 内存泄漏:长期运行后,内核内存耗尽,触发OOM Killer或系统挂起。
Linux内核死机排查与日志分析方法
当死机发生时,如何快速定位问题?关键在于收集“黑匣子”数据。
启用Kdump机制捕获崩溃现场
Kdump是Linux系统捕获内核崩溃信息的标准工具,它利用第一个启动的内核(crash kernel)在第二个内核崩溃时保留内存状态。
配置步骤详解
1. 安装kexec-tools:确保系统已安装`kexec-tools`包。
2. 修改GRUB配置:在`/etc/default/grub`中添加`crashkernel=auto`参数,预留足够内存(通常建议256MB以上,视物理内存而定)。
3. 重启生效:执行`grub2-mkconfig -o /boot/grub2/grub.cfg`(CentOS/RHEL)或`update-grub`(Ubuntu/Debian)并重启。
4. 验证配置:重启后检查`/proc/cmdline`是否包含`crashkernel`参数。
分析vmcore文件
内核崩溃后,核心转储文件通常位于`/var/crash/<日期>/vmcore`。
使用crash工具:安装`crash`包,运行`crash /usr/lib/debug/lib/modules/$(uname -r)/vmlinux /var/crash/…/vmcore`。
常用命令:
`bt`:查看调用栈,定位崩溃函数。
`log`:查看崩溃前的内核日志。
`ps`:查看崩溃时运行的进程。
实时日志监控与dmesg分析
对于未触发完整Kdump的软死机或警告,dmesg是首要检查对象。
- 持续监控:使用
tail -f /var/log/messages或journalctl -f
实时观察日志。
- 过滤关键信息:使用
dmesg -T | grep -i error快速筛选错误信息。 - 时间戳对齐:结合系统时间戳,将内核错误与应用程序日志进行时间对齐,寻找关联事件。

Linux内核死机预防与优化策略
预防胜于治疗,通过合理的系统调优和硬件维护,可以显著降低死机概率。
硬件层面的稳定性保障
- 定期硬件巡检:监控CPU温度、风扇转速和电压稳定性,过热是导致CPU降频甚至死机的常见原因。
- 内存完整性测试:在生产环境部署前,务必运行至少24小时的内存压力测试。
- 固件更新:保持BIOS、UEFI、RAID卡固件和网卡固件为最新版本,修复已知兼容性Bug。
内核参数调优与资源限制
合理的内核参数设置可以避免资源耗尽导致的死机。
关键参数建议
vm.swappiness:根据内存大小调整,服务器通常建议设置为10-20,减少swap使用,避免I/O瓶颈。
net.core.somaxconn:增加连接队列长度,防止高并发下的TCP连接丢弃。
kernel.panic:设置自动重启时间,如`kernel.panic = 10`,使系统在崩溃后10秒自动重启,缩短停机时间。
使用cgroups进行资源隔离
通过cgroups限制单个进程或容器的CPU、内存使用上限,防止某个异常进程耗尽系统资源,引发内核级OOM。
Linux内核死机与Windows蓝屏对比分析
理解Linux内核死机与Windows蓝屏(BSOD)的差异,有助于更好地选择排查工具和方法。
| 对比维度 | Linux Kernel Panic/Oops | Windows Blue Screen (BSOD) |
|---|---|---|
| 错误信息 | 文本格式,包含寄存器状态、调用栈 | 图形界面,包含错误代码(如0x0000007B) |
| 转储文件 | vmcore,需专用工具crash分析 | MEMORY.DMP,可用WinDbg分析 |
| 常见原因 | 驱动Bug、硬件故障、内核漏洞 | 驱动不兼容、系统文件损坏、硬件故障 |
| 排查难度 | 较高,需命令行操作和专业工具 | 中等,有图形化诊断工具支持 |
| 社区支持 | 邮件列表、IRC、GitHub Issues | 微软官方支持、论坛、知识库 |

业内专家指出,Linux的透明性使其在长期运行稳定性上具有优势,但前提是运维人员具备足够的底层调试能力。
Linux内核死机常见问题解答
如何查看Linux内核死机的具体原因?
首先检查`/var/log/messages`或`journalctl -k`中的内核日志,寻找“Oops”、“Panic”或“BUG”字样,如果配置了Kdump,使用`crash`工具分析`/var/crash`下的`vmcore`文件,通过`bt`命令查看调用栈,定位导致崩溃的函数和模块。
Linux内核死机后数据会丢失吗?
如果死机发生在文件系统写入过程中,且未启用Journaling(日志记录)文件系统或Journal损坏,确实可能导致数据不一致或丢失,Ext4、XFS等现代文件系统具备日志功能,能在崩溃后自动恢复一致性,但正在写入的未提交数据可能丢失,定期备份和启用UPS(不间断电源)至关重要。
如何避免Linux内核死机?
避免内核死机需要从硬件、驱动和系统配置三方面入手,使用ECC内存并定期测试,保持BIOS和驱动固件最新,避免使用未经充分测试的第三方内核模块,合理设置内核参数如`vm.swappiness`和`kernel.panic`,并启用Kdump以便在崩溃时捕获现场信息进行分析。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/457685.html