Hash存储的核心优势在于通过唯一标识符实现数据的快速定位与完整性校验,它是现代分布式系统和区块链技术的底层基石。
为什么Hash存储成为数据管理的刚需?
在数字化浪潮中,我们每天产生的数据量呈指数级增长,传统的数据库依靠主键ID来查找记录,这种方式在数据量达到千万级甚至亿级时,检索效率会显著下降,Hash存储通过一种特殊的算法,将任意长度的输入数据映射为固定长度的字符串,这个字符串就是“哈希值”或“指纹”。
业内专家指出,这种映射机制具有不可逆性和唯一性,这意味着,只要原始数据发生哪怕一个比特的变化,生成的哈希值也会截然不同,这种特性使得Hash存储在数据去重、快速检索和完整性验证方面具有天然优势。
Hash存储与传统数据库对比
为了更直观地理解Hash存储的价值,我们可以将其与关系型数据库进行对比:
- 检索速度:传统数据库依赖B+树等索引结构,查找复杂度通常为O(log n);而Hash存储通过哈希表直接定位,理想情况下时间复杂度为O(1),检索速度极快。
- 数据完整性:传统数据库难以直接验证数据在传输或存储过程中是否被篡改;Hash值则像数据的“数字指纹任何微小的改动都会导致指纹失效。
- 去重效率:在海量数据中,比较两个大文件的哈希值比直接比较文件内容要高效得多,极大地节省了带宽和存储资源。
应用场景中的Hash存储实践
Hash存储并非高高在上的理论,它已经渗透到我们生活的方方面面:
- 区块链底层:比特币和以太坊等区块链系统利用Hash算法确保区块链接的不可篡改性,每个区块都包含前一个区块的哈希值,形成链条。
- CDN加速分发网络使用Hash值作为文件的唯一标识,确保全球节点缓存的是最新且未被篡改的内容。
- 密码学安全:虽然不建议直接存储明文密码,但系统通常存储密码的哈希值,即使数据库泄露,攻击者也无法直接还原出原始密码。

Hash存储的技术原理与实现机制
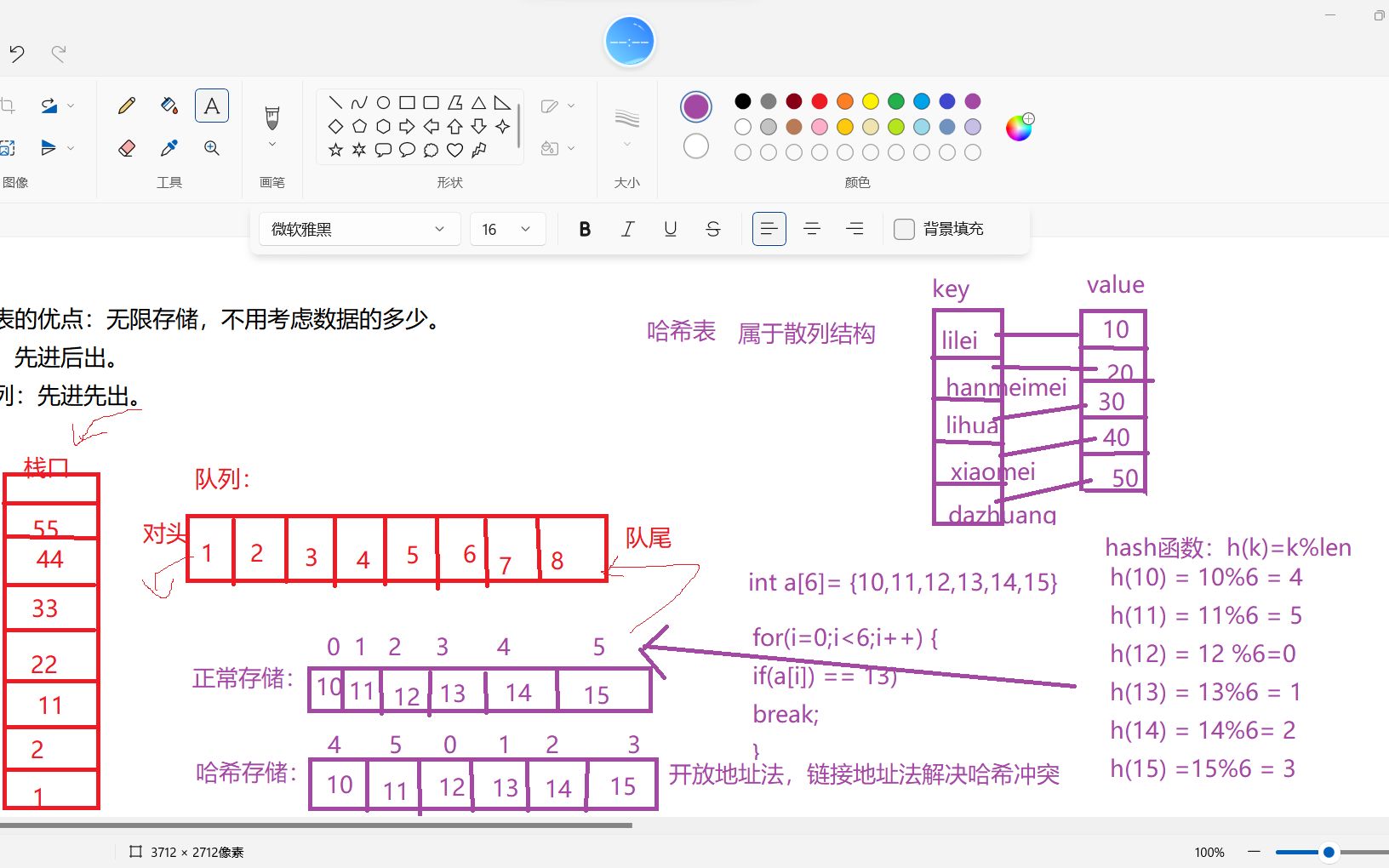
理解Hash存储,关键在于掌握哈希函数和哈希表的工作原理,哈希函数是一个数学函数,它将输入数据转换为固定长度的输出,常见的哈希算法包括MD5、Sha-1、Sha-256等。
哈希冲突的处理策略
由于输入空间远大于输出空间,不同的输入数据可能会产生相同的哈希值,这就是“哈希冲突”,解决冲突是Hash存储设计的核心难点:
- 链地址法:每个哈希桶维护一个链表,当发生冲突时,将新元素添加到链表尾部,这种方法实现简单,但在极端情况下可能导致链表过长,影响性能。
- 开放寻址法:当发生冲突时,按照一定的探测序列寻找下一个可用的哈希桶,这种方法缓存友好,但删除操作较为复杂。
- 双重哈希:使用两个哈希函数,第一个函数确定初始位置,第二个函数确定步长,这种方法能有效减少冲突聚集。
常见哈希算法选型指南
选择合适的哈希算法至关重要,不同算法在安全性、速度和输出长度上各有侧重:
| 算法名称 | 输出长度 | 安全性 | 速度 | 典型应用场景 |
|---|---|---|---|---|
| MD5 | 128位 | 低(已不安全) | 极快 | 文件校验、非安全场景标识 |
| Sha-1 | 160位 | 低(已不推荐) | 快 | 旧版Git版本控制 |
| Sha-256 | 256位 | 高 | 中等 | 区块链、数字签名、安全存储 |
|
SHA-3 | 可变 | 极高 | 中等 | 高安全需求场景 |

据工信部数据,目前主流的安全应用已普遍转向Sha-256或更高强度的算法,MD5仅用于非安全目的的快速校验。
Hash存储在实际开发中的落地方案
对于开发者而言,如何高效地利用Hash存储是提升系统性能的关键,以下是几个常见的落地场景和操作建议。
分布式缓存中的Hash策略
在Redis等分布式缓存系统中,Hash结构常用于存储对象信息,存储用户信息时,可以使用HSET命令将用户的姓名、年龄、邮箱等字段存储在一个Hash键中。
HSET user:1001 name "张三" age 30 email "zhang@example.com"
这种结构不仅节省内存,还支持对单个字段的原子操作,如HINCRBY用于增加积分或余额。
文件去重与存储优化
在云存储场景中,文件去重是降低成本的重要手段,系统可以在上传文件时计算其哈希值,如果该哈希值已存在于数据库中,则直接引用已有文件,而不必重新存储。
操作步骤如下:
- 客户端计算文件的Sha-256哈希值。
- 将哈希值发送至服务器进行查询。
- 若服务器返回“存在”状态,则建立引用链接。
- 若服务器返回“不存在”状态,则上传文件并存储哈希值与文件ID的映射关系。
这种机制在视频网站和网盘服务中极为常见,能显著减少重复数据的存储开销。
如何选择合适的Hash存储方案?
选择Hash存储方案时,需综合考虑数据量、并发量和一致性要求:
- 小规模数据:直接使用内存中的哈希表(如Java的HashMap)即可,性能极高。
- 大规模分布式数据:采用一致性哈希算法,确保节点增减时数据迁移量最小化。
- 高安全性要求:结合加盐(Salt)技术,防止彩虹表攻击,存储密码时,先生成随机盐值,再计算
Hash(Password + Salt)
。

Hash存储面临的挑战与未来趋势
尽管Hash存储优势明显,但也面临一些挑战,随着量子计算的发展,现有的哈希算法可能面临被破解的风险,哈希冲突在极端情况下仍可能影响系统性能。
量子计算对Hash算法的影响
量子计算机利用量子叠加和纠缠特性,理论上可以大幅加速搜索过程,Grover算法可以将暴力破解哈希值的复杂度从O(2^n)降低到O(2^(n/2)),这意味着,原本安全的256位哈希值,在量子计算机面前可能相当于128位的安全性。
行业共识认为,未来需要开发抗量子哈希算法,或增加哈希输出长度以应对这一威胁。
性能优化与扩展性
在实际应用中,优化Hash存储性能的关键在于减少冲突和负载均衡:
- 扩容机制:当哈希表负载因子超过阈值时,自动扩容并重新哈希所有数据。
- 预分配空间:在已知数据量的情况下,预分配足够的哈希桶,减少扩容次数。
- 局部性原理:优化数据结构,提高缓存命中率,减少内存访问延迟。
Hash存储常见问题解答
Hash存储适合用于大规模关系型数据查询吗?
Hash存储擅长精确匹配和快速查找,但不支持范围查询、排序或多表关联,对于需要复杂查询的场景,建议结合使用关系型数据库和Hash存储,利用Hash进行快速定位,再利用数据库进行复杂处理。
如何防止哈希碰撞导致的数据错误?
虽然哈希碰撞概率极低,但在高并发场景下仍需防范,可以通过增加哈希长度(如使用Sha-256而非Md5)、引入二次验证机制(如存储哈希值的同时存储少量原始数据特征)来降低风险。
Hash存储的价格和维护成本如何?
Hash存储本身是一种数据结构,其成本取决于底层基础设施,在公有云上,使用托管的Redis或DynamoDB等服务,成本主要包括存储容量和请求次数,自建Hash存储集群则需要投入服务器硬件、运维人力和电力成本,总体来看,Hash存储因效率高、资源利用率高,长期来看能降低单位数据的存储成本。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/458821.html