分布式缓存中,一致性哈希算法通过引入虚拟节点和哈希环机制,有效解决了传统哈希算法在节点增减时导致的缓存大规模失效问题,是构建高可用、高扩展性缓存架构的核心技术基石。
在构建大规模分布式系统时,缓存层往往是最先遇到瓶颈的地方,当业务量激增,单台缓存服务器无法承载时,我们需要横向扩展,增加新的服务器节点,这时候,如何保证数据在新增节点后依然能均匀分布,且尽可能少地发生数据迁移,就成了一个关键的技术难题,传统取模算法虽然简单,但一旦节点数量发生变化,所有数据的映射关系都会重置,导致绝大部分缓存失效,引发“缓存雪崩”或巨大的数据库压力,为了解决这个痛点,业内专家指出,一致性哈希算法因其优秀的容错性和扩展性,成为了分布式缓存领域的标准解决方案。
为什么传统哈希算法在动态节点场景下失效
要理解一致性哈希的优势,首先得看清传统方案的短板,在早期的缓存设计中,我们通常使用 hash(key) % N 这样的公式来确定数据存储在哪个节点,N 是节点总数,这种方式的逻辑非常直观,但在动态环境中却显得极其脆弱。
节点扩容带来的数据震荡
想象一下,如果你的集群有10个节点,现在因为业务增长,需要增加到11个节点,根据取模算法,N 从10变成了11,这意味着几乎所有数据的哈希结果取模后的余数都会发生改变,原本存储在节点1的数据,可能需要迁移到节点3、节点5甚至节点9,这种全量的数据重新分布,不仅消耗大量的网络带宽和计算资源,更致命的是,在数据迁移期间,大量请求会因为找不到对应的缓存而直接穿透到后端数据库,导致数据库瞬间过载。
数据倾斜问题
除了迁移问题,传统哈希算法还容易受到数据分布不均的影响,如果某些热点Key的哈希值恰好集中在某个区间,而节点数量较少,就会导致某些节点负载极高,而其他节点闲置,这种“木桶效应”在流量高峰时期尤为明显,直接限制了系统的整体吞吐量。

一致性哈希算法的核心原理与实现逻辑
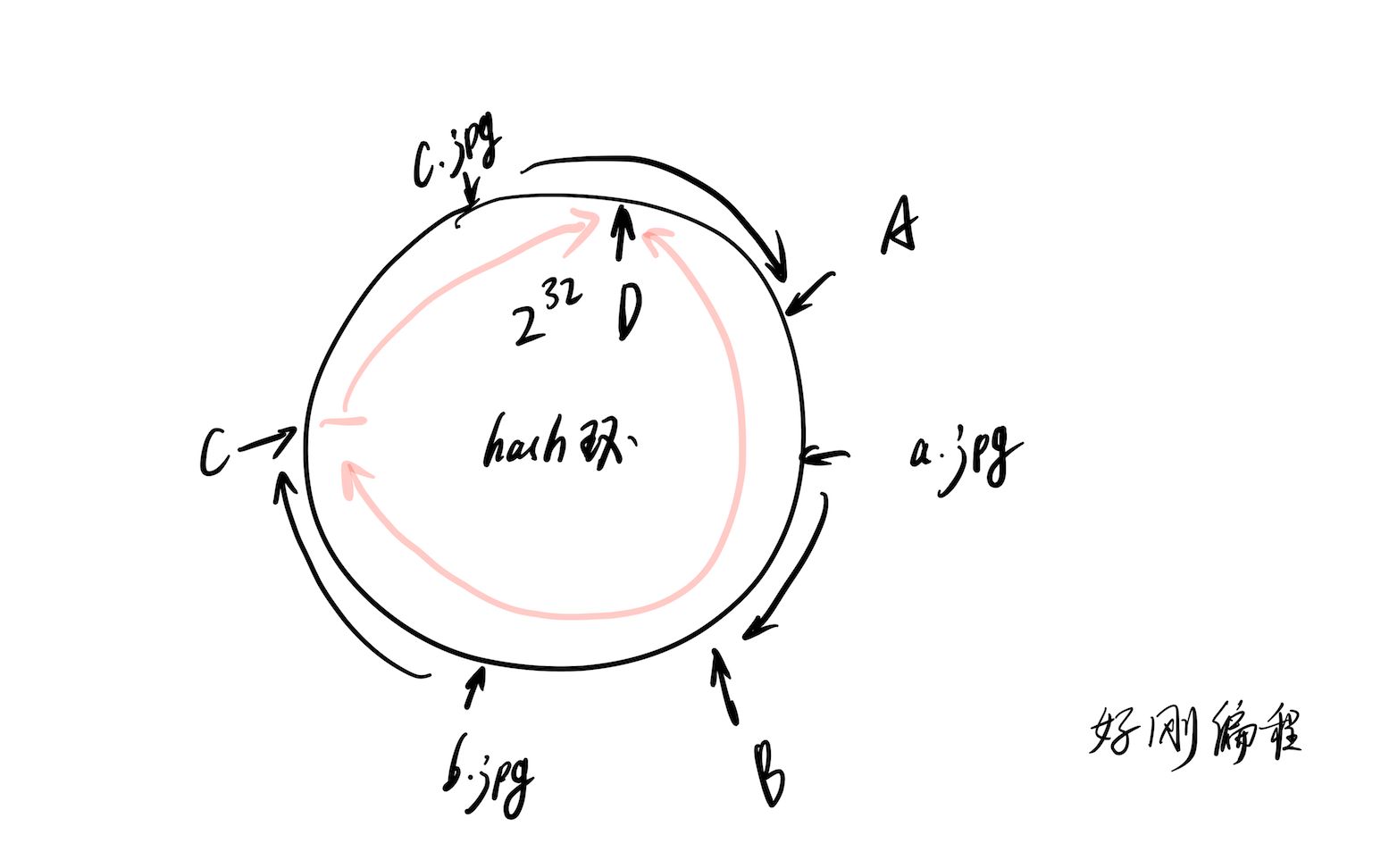
一致性哈希算法通过构建一个虚拟的“哈希环”,将数据和节点都映射到这个环上,从而巧妙地解决了上述问题,它的核心思想是将哈希空间组织成一个圆环,首尾相连。
哈希环的构建过程
具体操作上,系统首先计算出节点IP或主机名的哈希值,并按顺时针方向将其放置在哈希环上,这些点被称为“节点点”,对于每一个缓存Key,也计算其哈希值,并同样放置在环上,查找数据时,从Key对应的点出发,沿顺时针方向寻找第一个遇到的节点点,该节点即为数据的存储位置。
虚拟节点的引入
虽然上述逻辑解决了节点增减时的数据迁移问题,但它引入了一个新的问题:数据倾斜,如果节点在环上的分布不均匀,某些节点可能会承担过多的数据,为了解决这个问题,业界普遍采用“虚拟节点”技术,即每个物理节点在哈希环上对应多个虚拟节点,一个物理节点可以映射出100-200个虚拟节点,均匀分布在环上,这样,即使物理节点数量较少,也能通过虚拟节点实现数据的均匀分布,显著降低数据倾斜的概率。
分布式缓存一致性hash在实际场景中的优势对比
为了更清晰地展示一致性哈希的价值,我们可以将其与传统算法在几个关键维度上进行对比。
| 对比维度 | 传统取模算法 | 一致性哈希算法 |
|---|---|---|
| 节点增加时数据迁移量 | 约 (N-1)/N 的数据需要迁移 |
仅约 1/N 的数据需要迁移 |
| 节点减少时数据迁移量 | 约 (N-1)/N 的数据需要迁移 |
仅约 1/N
的数据需要迁移 |
| 数据分布均匀性 | 依赖哈希函数质量,易倾斜 | 通过虚拟节点可高度均匀 |
| 系统稳定性 | 节点变动导致大规模缓存失效 | 局部失效,系统整体稳定 |

高可用性的具体体现
在真实的生产环境中,服务器宕机或网络抖动是常态,当某个节点失效时,一致性哈希算法只会影响该节点顺时针方向下一个节点的数据负载,其他节点的数据分布保持不变,缓存命中率不会发生剧烈波动,这种局部故障隔离能力,对于金融交易、电商秒杀等高并发场景至关重要,因为它确保了系统在部分组件失效时,依然能够维持基本的服务能力。
弹性伸缩的经济效益
对于云原生环境下的企业来说,弹性伸缩是降低成本的关键,一致性哈希算法允许系统在不中断服务的情况下,动态地添加或移除节点,这意味着企业可以根据实时流量,按需购买或释放计算资源,而不必担心数据迁移带来的高昂成本和性能抖动,据工信部相关数据显示,采用高效缓存策略的企业,其基础设施利用率平均提升了较大比例,运维成本显著降低。
如何优化一致性哈希算法的性能与稳定性
尽管一致性哈希算法已经非常成熟,但在极端场景下,仍有一些优化手段可以提升其表现。
合理设置虚拟节点数量
虚拟节点的数量并非越多越好,过多的虚拟节点会增加哈希表的内存占用和查找复杂度,业内共识认为,对于大多数应用场景,每个物理节点映射100-200个虚拟节点是一个较为合理的平衡点,具体数量应根据集群规模和数据量级进行调整,并通过压测验证。
处理哈希冲突与边界情况
在实际编码中,需要处理哈希值冲突的情况,如果两个不同的Key或节点映射到了环上的同一个点,需要定义明确的优先级规则,例如按节点ID排序,对于空环或只有一个节点的情况,也需要进行特殊处理,确保算法的鲁棒性。

监控与告警机制
部署一致性哈希集群后,必须建立完善的监控体系,重点关注缓存命中率、节点负载差异、数据迁移频率等指标,一旦发现某个节点负载异常偏高,或命中率突然下降,应及时触发告警,排查是否是虚拟节点分布不均或热点Key集中导致的。
分布式缓存一致性hash常见问题解答
一致性哈希算法是否支持动态修改虚拟节点数量?
支持,在大多数主流缓存中间件(如Redis Cluster、Memcached等)中,虚拟节点的数量是配置项,当需要调整数据分布均匀度时,可以通过修改配置并重启节点或重新平衡集群来实现,但需要注意的是,修改虚拟节点数量会触发一定程度的数据重分布,建议在业务低峰期进行操作,并提前评估迁移耗时。
一致性哈希算法在跨地域部署中表现如何?
一致性哈希算法本身是逻辑层面的映射,不直接感知物理地理位置,在跨地域部署中,通常结合“分片”策略使用,将不同地域的用户数据映射到不同的物理集群,而在每个集群内部使用一致性哈希进行负载均衡,这样可以减少跨地域网络延迟,同时保持集群内部的扩展性。
一致性哈希算法的哈希函数选择有什么讲究?
哈希函数的选择直接影响数据分布的均匀性和计算效率,常用的哈希函数包括MurmurHash、CityHash、XXHash等,MurmurHash因其良好的分布性和较高的计算速度,被广泛应用于分布式系统中,选择哈希函数时,应优先考虑其抗冲突能力和计算性能,避免使用MD5或SHA1等计算开销较大的算法,除非对安全性有极高要求。
一致性哈希算法通过其独特的哈希环和虚拟节点机制,为分布式缓存提供了卓越的扩展性和稳定性,在实际应用中,结合合理的虚拟节点配置和完善的监控体系,能够充分发挥其优势,支撑起大规模高并发业务的稳定运行。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/459413.html










