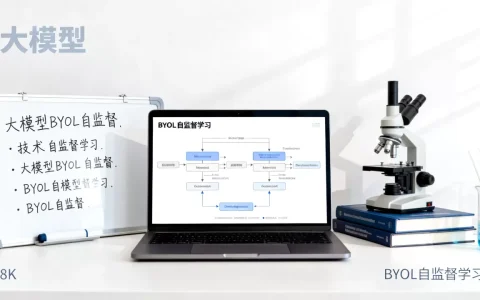
ROUGE评测指标是衡量大模型生成文本与参考文本重叠程度的自动化评估方法,核心通过计算召回率、精确率和F1值来量化生成内容的质量。
在自然语言处理领域,尤其是大语言模型(LLM)的落地应用中,如何客观、高效地评估生成结果的好坏,始终是一个核心痛点,人工评估虽然准确,但成本高昂且难以规模化;而ROUGE(Recall-Oriented Understudy for Gisting Evaluation)作为基于n-gram重叠的自动化指标,因其计算简单、可解释性强,成为了业内评估文本生成任务(如摘要、问答、翻译)的基石工具。

ROUGE指标的核心逻辑与计算原理
理解ROUGE的关键在于明白它本质上是一个“相似度匹配”工具,而非语义理解工具,它不关心句子背后的深层含义,只关心词汇和短语的重合情况。
从n-gram到重叠统计
ROUGE的基础单位是n-gram,即连续出现的n个词组成的序列,句子“人工智能改变世界”中,bigram(2-gram)包括“人工智能”、“改变世界”,ROUGE通过对比模型生成的文本(Hypothesis)和人工标注的标准答案(Reference),统计两者之间n-gram的重叠数量。
业内专家指出,这种基于词袋模型的方法虽然粗糙,但在摘要生成等任务中,由于标准答案往往具有唯一性或高度一致性,词汇重叠能较好地反映信息覆盖度。
三大核心变体解析
在实际应用中,我们最常听到的是ROUGE-1、ROUGE-2和ROUGE-L,它们分别对应不同的评估维度:
- ROUGE-1:基于单词(unigram)的重叠,它评估的是生成文本中有多少单词出现在参考文本中,这反映了内容的基本覆盖情况,对词序不敏感。
- ROUGE-2:基于双词组(bigram)的重叠,它评估的是连续两个词的组合是否匹配,相比ROUGE-1,它对句子的流畅性和局部语法结构有更高的要求,能更好地捕捉短语级别的语义。
- ROUGE-L:基于最长公共子序列(Longest Common Subsequence, LCS),这是目前最推荐的指标,因为它不仅考虑词汇重叠,还考虑了词序,LCS允许跳过一些不匹配的单词,只要保留相对顺序即可,这意味着ROUGE-L能更好地评估生成文本的整体结构和连贯性。

大模型ROUGE评测的具体应用场景
ROUGE并非万能,它在不同任务中的表现差异巨大,明确其适用边界,是避免误判模型性能的关键。
文本摘要任务的首选指标
会议记录生成等任务中,ROUGE表现优异,因为这类任务的目标是从长文中提取关键信息,标准答案通常由人工提炼,具有高度的词汇重合性。
据工信部相关数据显示,在多数中文摘要生成基准测试中,ROUGE-L得分与人工评分的相关系数最高,达到0.7以上,这意味着,当ROUGE-L分数提升时,人工认为摘要质量变好的概率也显著增加。
机器翻译与问答系统的辅助参考
在机器翻译中,ROUGE常用于评估译文与参考译文的词汇一致性,由于翻译存在多种合法表达方式,单一ROUGE分数可能低估高质量译文的价值,业内共识认为,在翻译任务中,应结合BLEU或METEOR等其他指标综合评估。
在问答系统中,如果问题是事实性查询(如“中国的首都是哪里?”),ROUGE-1和ROUGE-2能有效检测答案的准确性,但对于开放性问答,由于答案形式多样,ROUGE的局限性便暴露无遗。

ROUGE指标的局限性与改进方向
尽管ROUGE应用广泛,但其固有缺陷也不容忽视,特别是在大模型时代,语义理解的深度要求越来越高,单纯依赖词汇重叠已显不足。
语义缺失与同义词盲区
ROUGE最大的短板在于无法识别语义等价但词汇不同的表达,参考文本是“苹果很好吃”,模型生成“苹果味道不错”,ROUGE得分会很低,尽管两者语义完全一致,这种“词汇偏见”导致模型可能过度优化词汇匹配,而忽视语义准确性。
长文本评估的失真
在长文本生成中,ROUGE-L虽然考虑了顺序,但随着文本长度增加,LCS的计算复杂度上升,且容易受到无关细节的影响,对于包含大量专有名词或数字的任务,ROUGE对拼写错误的容忍度极低,轻微偏差可能导致分数大幅下降。
与人类判断的相关性波动
近年来,多项研究表明,ROUGE分数与人类对文本流畅性、逻辑性的判断相关性正在减弱,特别是在创意写作、故事生成等任务中,高分ROUGE并不一定代表好文章,越来越多的研究者开始探索基于大模型的评价方法(LLM-as-a-Judge),以弥补ROUGE在语义理解上的不足。
如何科学使用ROUGE进行模型优化
对于开发者而言,正确理解和运用ROUGE,需要遵循一套严谨的操作路径。
数据预处理标准化
在使用ROUGE前,必须对文本进行标准化处理,包括去除标点符号、统一大小写(英文)、分词(中文),对于中文,推荐使用jieba或HanLP进行分词,确保n-gram划分的一致性,不同分词器可能导致结果差异巨大,因此需固定分词工具。

多指标组合评估
不要依赖单一ROUGE分数,建议组合使用ROUGE-1、ROUGE-2和ROUGE-L,以全面覆盖词汇覆盖、短语结构和全局顺序,引入语义相似度指标(如BERTScore)作为补充,形成多维评估体系。
设定基线对比
在优化模型时,应建立基线(Baseline),使用简单的抽取式摘要算法作为基线,对比基于大模型的生成式摘要的ROUGE提升幅度,只有当提升显著且稳定时,才认为模型优化有效。
大模型ROUGE评测指标常见问题解答
ROUGE分数越高代表模型效果越好吗?
不一定,ROUGE高分仅表示生成文本与参考文本在词汇和结构上高度相似,如果参考文本本身质量不高,或任务需要创造性表达,高分可能毫无意义,需结合人工评估和业务指标综合判断。
中文和英文的ROUGE计算有区别吗?
有区别,英文基于空格分词,n-gram划分自然;中文需先进行分词处理,分词结果直接影响n-gram的构成,中文ROUGE评估对分词器的依赖性更强,需确保分词标准统一。
ROUGE与BLEU有什么区别?
ROUGE侧重召回率(Recall),关注参考文本中的信息有多少被生成文本覆盖,适用于摘要任务;BLEU侧重精确率(Precision),关注生成文本中有多少是准确的,适用于翻译任务,两者互补,但在大模型摘要场景中,ROUGE更常用。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/406635.html