云计算
-
cdn 测试 脚本怎么用,cdn 性能测试工具
cdn 测试脚本的核心价值在于通过模拟真实用户请求,量化边缘节点的响应延迟、命中率及故障恢复能力,从而为业务稳定性提供数据支撑,在2026年的数字化基础设施环境中,内容分发网络(CDN)已不再是简单的静态资源加速工具,而是融合了边缘计算、智能调度与安全防御的综合体,对于运维工程师和技术决策者而言,仅凭肉眼观察监……
-
cdn加速图片怎么用,cdn加速图片是什么
CDN加速图片是提升网站加载速度、降低服务器带宽成本并优化移动端用户体验的最有效技术手段,建议优先选择具备全球节点覆盖且支持WebP/AVIF格式自动转换的头部云服务商,在2026年的数字营销环境中,图片资源往往占据网页总大小的60%以上,若未采用内容分发网络(CDN)进行加速,用户访问延迟将显著增加,直接导致……
-
CDN带宽流量怎么算,CDN带宽流量费用
2026年CDN带宽与流量的核心结论是:带宽决定传输速度上限,流量决定计费成本总量,二者通过“峰值带宽”与“总流量”的耦合关系共同决定业务体验与支出效率,建议采用“带宽保底+流量阶梯”或“按量付费+智能调度”的组合策略以优化ROI,核心逻辑与计费模式解析理解CDN(内容分发网络)的本质,是厘清带宽与流量关系的前……
-
如何挂载本地存储服务器?本地存储服务器配置教程
本地存储服务器挂载本地存储的核心在于通过操作系统内核直接映射物理磁盘到文件系统,以实现比网络存储更低延迟、更高吞吐量的数据读写性能,这是构建高性能数据库或高频交易系统的最佳实践,在数字化转型的深水区,数据不再是冰冷的代码,而是企业的核心资产,当企业选择将数据存储在本地服务器上时,如何高效、稳定地将这些物理硬盘……
-
cdn直播技术是什么,cdn直播技术怎么配置
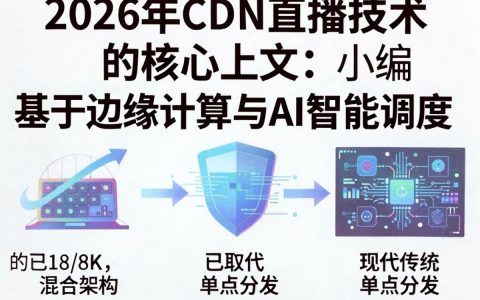
2026年CDN直播技术的核心结论是:基于边缘计算与AI智能调度的混合架构已取代传统单点分发,成为保障4K/8K超高清及VR直播低延迟、高并发的唯一标准方案,其综合成本较2023年降低约30%,延迟控制在200毫秒以内,直播分发架构的代际跃迁随着2026年元宇宙应用与全息通信的普及,传统CDN已无法满足海量并发……
-
如何本地搭建MySQL并迁移到RDS?本地MySQL迁移到RDS详细步骤
将本地MySQL迁移至阿里云RDS不仅是为了获得更稳定的云端存储,更是为了利用其自动备份、高可用架构及弹性扩容能力,彻底解决本地运维成本高、数据安全性差的痛点,很多开发者在业务初期习惯将MySQL部署在本地服务器或虚拟机上,这种模式在数据量小、并发低时确实简单直接,但随着业务增长,本地数据库的瓶颈逐渐显现:硬件……
-
cdn 带宽封顶怎么办,cdn 带宽封顶
CDN带宽封顶并非技术故障,而是运营商或云厂商为控制成本与防范滥用设定的硬性阈值,一旦触发将导致节点主动丢弃请求或返回503错误,需立即通过提升套餐、临时扩容或优化资源策略来解决, 为什么你的CDN会突然“断流”?1 触发封顶的核心机制解析CDN带宽封顶(Bandwidth Capping)本质是计费模型与风控……
-
本地测试程序怎么写?编写测试程序有哪些常用方法
编写本地测试程序的核心在于构建隔离环境、模拟真实数据并自动化执行验证,这能显著降低上线风险并提升开发效率,在软件开发的全生命周期中,本地测试往往是决定项目生死的关键环节,很多开发者习惯于直接部署到测试服务器,结果导致大量低级错误暴露在生产环境,不仅修复成本高昂,更严重损害用户体验,编写本地测试程序并非简单的代码……
-
cdn区块链是什么,cdn区块链技术应用
CDN与区块链结合并非概念炒作,而是通过去中心化存储与智能合约结算,在2026年已实质性解决传统CDN成本高、数据篡改风险及单点故障三大痛点,成为Web3.0内容分发基础设施的核心标准,技术底层逻辑:去中心化如何重构内容分发网络传统CDN依赖中心化的边缘节点,存在带宽垄断和数据隐私泄露风险,2026年,基于区块……
-
cdn url预热是什么,cdn url预热
CDN URL预热的核心结论是:通过主动将热点资源推送到边缘节点缓存,可将首屏加载速度提升30%-50%,显著降低源站压力并优化用户体验,是2026年高并发场景下的标准运维动作,在2026年的数字内容分发领域,CDN(内容分发网络)已不再仅仅是静态资源的加速通道,而是成为保障业务连续性与用户体验的关键基础设施……