云计算
-
本地测试程序怎么写?编写测试程序有哪些常用方法
编写本地测试程序的核心在于构建隔离环境、模拟真实数据并自动化执行验证,这能显著降低上线风险并提升开发效率,在软件开发的全生命周期中,本地测试往往是决定项目生死的关键环节,很多开发者习惯于直接部署到测试服务器,结果导致大量低级错误暴露在生产环境,不仅修复成本高昂,更严重损害用户体验,编写本地测试程序并非简单的代码……
-
cdn区块链是什么,cdn区块链技术应用
CDN与区块链结合并非概念炒作,而是通过去中心化存储与智能合约结算,在2026年已实质性解决传统CDN成本高、数据篡改风险及单点故障三大痛点,成为Web3.0内容分发基础设施的核心标准,技术底层逻辑:去中心化如何重构内容分发网络传统CDN依赖中心化的边缘节点,存在带宽垄断和数据隐私泄露风险,2026年,基于区块……
-
cdn url预热是什么,cdn url预热
CDN URL预热的核心结论是:通过主动将热点资源推送到边缘节点缓存,可将首屏加载速度提升30%-50%,显著降低源站压力并优化用户体验,是2026年高并发场景下的标准运维动作,在2026年的数字内容分发领域,CDN(内容分发网络)已不再仅仅是静态资源的加速通道,而是成为保障业务连续性与用户体验的关键基础设施……
-
便宜好用的云服务器怎么选?云服务器计费模式有哪些
选择云服务器时,核心在于平衡性能与预算,建议优先关注按量付费的灵活性及首年优惠力度,避免为闲置资源买单,在2026年的云计算市场,”便宜好用”早已不是简单的低价竞争,而是对资源利用率、计费透明度和运维效率的综合考量,许多初创团队和个人开发者在选型时,往往被复杂的计费模型劝退,或者因盲目追求低价而陷入性能瓶颈,找……
-
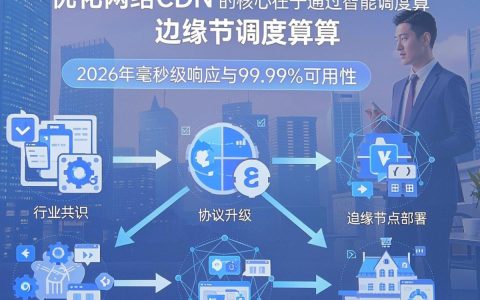
优化网络CDN卡顿怎么办,CDN加速服务价格
优化网络CDN的核心在于通过智能调度算法、边缘节点部署及协议升级,实现毫秒级响应与99.99%可用性,2026年行业共识表明,混合云架构与AI驱动的动态加速是提升用户体验的关键路径,CDN优化的核心逻辑与技术演进在2026年的数字生态中,CDN已不再仅仅是静态资源的分发网络,而是演变为包含计算、安全与智能调度在……
-
北京短信通知平台接口怎么用?短信通知接口哪家便宜
北京短信通知平台通过集成标准化API接口,能够以秒级速度向全国用户发送验证码、业务提醒及营销信息,是企业在数字化运营中不可或缺的基础通信设施,在移动互联网高度渗透的今天,短信依然是触达用户最稳定、打开率最高的渠道之一,对于身处北京乃至全国的企业而言,选择一款稳定高效的短信通知平台,不仅仅是技术对接的问题,更是关……
-
cdn自建组网靠谱吗,cdn自建组网
CDN自建组网并非简单的服务器堆砌,而是通过智能调度算法、边缘节点分布式部署及协议优化,实现内容分发效率提升30%-50%并显著降低带宽成本的核心技术架构,2026年已成为中大型互联网企业保障高并发稳定性的标配方案,CDN自建组网的核心逻辑与技术架构在2026年的数字化基础设施环境中,传统公有云CDN虽便捷,但……
-
cdn缓存攻击是什么,cdn缓存攻击怎么防御
CDN缓存攻击并非传统意义上的DDoS流量洪峰,而是利用CDN缓存机制缺陷或配置错误,通过构造特定请求耗尽源站带宽、CPU或内存资源的“逻辑型”攻击,其核心特征是低带宽消耗、高源站负载,且难以被传统WAF完全拦截, 认知重构:什么是CDN缓存攻击?攻击本质与原理传统认知中,DDoS攻击依赖海量IP发起TCP/U……
-
微软云CDN加速慢怎么办,微软云CDN配置教程
微软云CDN(Azure CDN)凭借与Azure生态的深度集成、全球边缘节点覆盖及企业级安全防护,是2026年构建高性能、高可用Web应用的首选方案,尤其适合已有Azure基础设施或追求云原生架构的企业用户,微软云CDN核心优势与架构解析在2026年的云计算市场,内容分发网络(CDN)已不仅仅是加速工具,更是……
-
BMS是什么意思?删除按钮具体有什么作用
BMS是电池管理系统(Battery Management System)的缩写,而“删除”按钮通常指在软件界面中移除文件或数据的操作指令,两者分别属于硬件控制与软件交互的不同领域概念,在数字化生活与新能源技术并行的今天,这两个词汇经常出现在不同的语境中,容易让非专业人士产生混淆,BMS作为新能源汽车和储能系统……