网页出现乱码通常是因为浏览器编码设置与网页实际编码不一致,或服务器响应头缺失charset声明,直接修改浏览器编码或修复服务器配置即可解决。
打开网页看到满屏的“锟斤拷”或问号,这种视觉冲击确实让人头疼,这不仅仅是显示问题,更是数据在传输和解析过程中“语言不通”的结果,当浏览器试图用一种编码规则(如UTF-8)去解读另一种编码规则(如GBK)生成的字节流时,字符映射就会出错,最终呈现为不可读的符号,解决这个问题,不需要复杂的编程知识,只需理清浏览器与服务器之间的“对话”逻辑。
网页乱码产生的核心原因与场景
理解乱码的成因是解决问题的前提,业内专家指出,乱码并非单一因素导致,而是编码标准、服务器配置、文件保存格式三者之间出现了断层。
浏览器编码猜测失误
大多数现代浏览器(如Chrome、Edge)默认使用UTF-8编码,如果网页开发者没有明确指定编码,或者指定的编码有误,浏览器就会启动“猜测机制”,这种猜测在中文网页上尤其容易出错,一个使用GBK编码编写的老旧中文网站,被浏览器误判为UTF-8,结果就是每个汉字变成两个或三个乱码字符,这种情况在访问一些未维护的老式企业官网或政府旧版系统时尤为常见。
服务器响应头缺失或错误
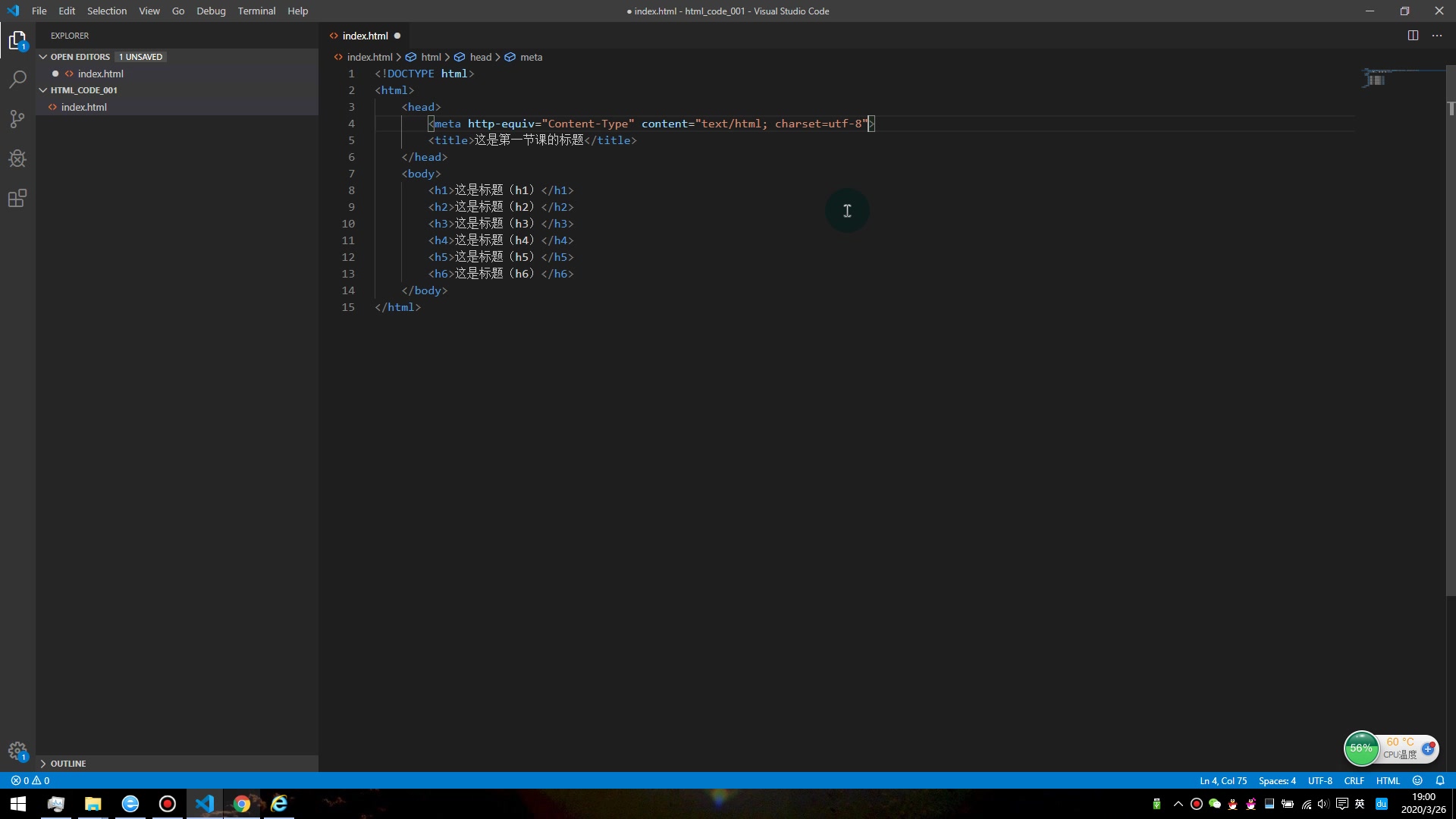
服务器在返回HTML文件时,必须通过HTTP响应头告知浏览器文件的字符集,如果服务器配置不当,缺少Content-Type: text/html; charset=utf-8这一关键信息,浏览器就只能盲猜,对于静态HTML文件,如果文件本身没有包含<meta charset="...">标签,且服务器未正确配置,乱码几乎是必然结果。
文件保存格式不匹配
开发者在编写代码时,使用的文本编辑器保存文件的编码格式,必须与网页声明的编码格式一致,如果网页声明使用UTF-8,但文件实际保存为ANSI(即GBK),即便服务器配置完美,用户端依然会看到乱码,这是新手开发者最容易犯的错误,尤其是在处理中文内容时。

快速排查与解决乱码的实操步骤
面对乱码,不要急于重装浏览器或联系技术支持,按照以下层级进行排查,90%的问题可以在两分钟内解决。
第一步:手动切换浏览器编码
这是最直接的验证方法,不同浏览器的操作路径略有不同,但逻辑一致。
- Chrome/Edge浏览器:右键点击页面空白处,选择“编码”(Encoding),如果看到“简体中文(GBK)”或“繁体中文(Big5)”选项,点击它,如果页面瞬间恢复正常,说明问题出在编码声明缺失。
- Firefox浏览器:点击菜单栏的“查看” -> “字符编码” -> 选择“简体中文”或“自动检测”。
如果切换编码后页面恢复正常,但刷新后又变乱码,说明网页开发者未正确设置持久化的编码声明,建议联系网站管理员反馈。
第二步:检查网页源码中的Meta标签
如果手动切换编码无效,或者你希望从根源修复,需要检查网页源码,右键点击页面,选择“查看网页源代码”(或按Ctrl+U)。
在<head>标签区域内,寻找以下代码:
<meta charset="UTF-8">
或者较旧的标准:
<meta http-equiv="Content-Type" content="text/html; charset=gbk">
- 情况A:找不到上述代码,这意味着网页缺少编码声明,如果你拥有该网页的编辑权限,立即在
<head>内添加<meta charset="UTF-8">,这是目前互联网的标准做法。 - 情况B:代码存在但编码错误,网页包含大量中文,但声明为
charset=iso-8859-1,将声明修改为charset=utf-8或charset=gbk(视文件实际保存格式而定)。
第三步:验证服务器配置与文件保存
对于网站管理员或开发者,需要确保服务器和文件的一致性。
-

文件保存
:使用Notepad++或VS Code等编辑器打开HTML文件,查看右下角的编码状态,如果显示“ANSI”,而网页声明为UTF-8,请点击“编码”->“转为UTF-8编码”,然后保存。 - 服务器配置:检查Apache或Nginx配置文件。
- Apache:在
.htaccess文件中添加AddDefaultCharset UTF-8。 - Nginx:在
nginx.conf的http或server块中添加charset utf-8;。
- Apache:在

不同场景下的乱码特殊处理
除了通用的HTML页面,特定场景下的乱码问题有其特殊性,了解这些场景,能避免走弯路。
下载文件时的乱码问题
当你在浏览器中下载TXT、CSV或Excel文件时,如果文件名或内容显示为乱码,通常是因为文件名编码问题。
- 文件名乱码:服务器在返回下载文件时,HTTP头中的
Content-Disposition字段若未正确编码文件名(如使用RFC 5987标准),浏览器无法识别中文文件名,解决方法是服务器端对文件名进行Base64或URL编码。 - 内容乱码:下载的CSV文件如果用Excel打开显示乱码,是因为Excel默认使用系统区域设置(如GBK)打开,而文件可能是UTF-8,先用记事本打开CSV,另存为时选择“编码:ANSI”或“UTF-8 with BOM”,即可在Excel中正常显示。
移动端与PC端显示差异
有时PC端正常,手机端乱码,或反之,这通常与移动浏览器的默认编码设置或视口元标签有关。
- 检查Viewport:确保HTML头部包含
<meta name="viewport" content="width=device-width, initial-scale=1.0">。 - 字体缺失:手机端可能缺少特定中文字体,导致fallback字体显示异常,看似乱码,检查CSS中的
font-family设置,确保包含通用无衬线字体如"PingFang SC", "Microsoft YaHei", sans-serif。
预防乱码的最佳实践建议
与其事后修复,不如事前预防,遵循以下规范,可以彻底杜绝乱码问题。

统一使用UTF-8编码
UTF-8是互联网的通用语言,支持全球绝大多数字符,除非有极特殊的遗留系统兼容需求,否则所有新开发的网页、API接口、数据库连接都应强制使用UTF-8。
标准化HTTP响应头
服务器应始终在HTTP响应头中明确指定字符集,不要依赖浏览器猜测,对于动态生成的内容(如PHP、Python、Java后端),确保输出流的编码设置为UTF-8。
编辑器与项目配置一致
在IDE(如VS Code、WebStorm)中设置默认文件编码为UTF-8,在Git仓库中配置.gitattributes文件,强制文本文件以UTF-8存储,避免版本控制过程中的编码转换错误。
定期测试多语言环境
在发布前,使用不同浏览器(Chrome、Firefox、Safari)和不同操作系统(Windows、macOS、Android、iOS)进行跨平台测试,特别关注中文、日文、韩文等东亚字符的显示效果。
常见疑问解答
网页乱码怎么快速修复?
首先尝试在浏览器中右键选择“编码”,手动切换为“简体中文(GBK)”或“UTF-8”,如果页面恢复正常,说明是编码声明缺失,若无效,检查网页源码中<head>部分是否有<meta charset="...">标签,并确保其值与文件实际保存编码一致,对于开发者,需检查服务器配置是否强制指定了正确的charset。
为什么有的网页只有标题乱码?
乱码通常是因为数据库读取数据时编码不一致,或前端模板引擎渲染时未正确转义,检查数据库连接字符串是否指定了`characterEncoding=utf8`,确保HTML文件的``声明正确,且服务器返回的Content-Type头中包含正确的charset参数。
乱码会影响SEO排名吗?
会,搜索引擎爬虫在抓取网页时,如果无法正确解析内容,会导致索引失败或内容识别错误,直接影响关键词匹配和排名,用户体验差会导致跳出率升高,间接降低SEO表现,确保网页编码正确,是SEO基础技术优化的一部分。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/327355.html