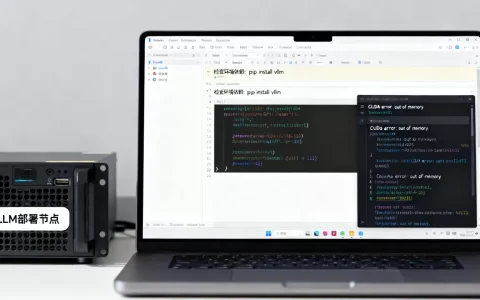
Ollama 安装大模型的核心在于通过官方命令行工具一键部署本地环境,实现数据隐私保护与离线推理,无需依赖云端 API 即可在个人设备上运行 Llama 3、Qwen 等主流模型。
随着人工智能技术的普及,越来越多的开发者和个人用户开始关注本地化部署大语言模型(LLM),这种趋势不仅源于对数据隐私的极致追求,也为了降低长期调用云端 API 的成本,Ollama 作为目前最流行的本地大模型运行框架之一,凭借其极简的安装流程和强大的模型库支持,成为了许多技术爱好者的首选工具,它屏蔽了底层复杂的深度学习框架差异,让用户只需关注模型本身,而非环境配置。

为什么选择 Ollama 进行本地部署
在决定安装之前,了解其核心优势有助于明确使用场景,业内专家指出,本地部署的最大价值在于数据主权,当你的代码、文档或敏感对话存储在本地硬盘而非云端服务器时,泄露风险将大幅降低。
隐私保护与数据安全
对于企业用户或注重隐私的个人而言,将模型运行在本地意味着数据永远不会离开你的设备,无论是处理内部代码库,还是分析个人日记,所有推理过程均在本地 CPU 或 GPU 上完成,这种隔离性消除了第三方服务商监听或存储数据的可能性,符合 GDPR 等严格的数据合规要求。
成本效益与无限调用
云端 API 通常按 token 数量计费,对于高频使用者来说,这是一笔不小的开支,相比之下,Ollama 是一次性安装,后续调用无额外费用,虽然硬件有初始投入,但长期来看,对于日均调用量较大的用户,本地部署的经济优势显著,行业共识认为,随着硬件性能的提升,本地推理的成本正在迅速逼近甚至低于云端服务。
Ollama 安装前的硬件与环境准备
在安装软件之前,确保硬件满足基本要求是避免后续报错的关键,Ollama 对内存和显存有一定的要求,不同规模的模型需要不同的资源分配。
系统兼容性检查
Ollama 支持 Windows、macOS 和 Linux 三大主流操作系统。
- macOS 用户:推荐使用 Apple Silicon 芯片(M1/M2/M3),因为统一内存架构能高效处理大模型权重加载,Intel 芯片也可运行,但速度较慢。
- Windows 用户:需确保安装了最新版本的 Windows 10 或 11,并启用 WSL2 或原生支持,NVIDIA 显卡用户需安装对应的 CUDA 驱动以加速推理。
- Linux 用户:大多数发行版均可直接通过脚本安装,需确保系统内核版本较新,以支持最新的 GPU 驱动特性。

内存与存储需求评估
模型大小直接决定了对 RAM 和 SSD 空间的需求。
| 模型规模 | 推荐内存 | 推荐存储 | 适用场景 |
|---|---|---|---|
| 7B 参数(如 Llama 3 8B) | 8GB – 16GB | 5GB – 10GB | 日常对话、代码辅助、轻量级任务 |
| 13B – 14B 参数 | 16GB – 32GB | 10GB – 20GB | 复杂推理、长文本分析、多轮对话 |
| 70B+ 参数 | 64GB 以上 | 40GB 以上 | 专业级应用、高精度逻辑推理 |
多数情况下,建议预留比最低要求多 20% 的内存空间,以应对操作系统和其他后台进程的资源占用。
Ollama 详细安装步骤
安装过程非常直观,主要分为下载、安装和验证三个阶段,以下以最常见的 macOS 和 Windows 为例进行说明。
macOS 系统安装指南
- 访问 Ollama 官方网站,点击“Download for Mac”按钮,下载
.pkg安装包。 - 双击运行安装包,按照向导提示完成安装,系统可能会询问是否允许应用更改,点击“允许”即可。
- 打开终端(Terminal),输入
ollama -v命令,如果返回版本号,说明安装成功。
Windows 系统安装指南
- 访问官网,下载 Windows 安装包。
- 运行安装程序,建议选择默认安装路径,以便系统自动配置环境变量。
- 安装完成后,打开命令提示符(CMD)或 PowerShell,输入
ollama -v验证安装。 - 若需使用 NVIDIA 显卡加速,请确保已安装 CUDA Toolkit 并配置好环境变量。
Linux 系统快速安装

Linux 用户可以使用一行命令完成安装,这是最便捷的方式。curl -fsSL https://ollama.com/install.sh | sh
安装完成后,同样通过 ollama -v 检查版本,对于使用 NVIDIA GPU 的 Linux 用户,还需安装 nvidia-container-toolkit 以启用 GPU 支持。
如何下载与运行大模型
安装好 Ollama 后,接下来的核心环节是获取模型,Ollama 内置了庞大的模型库,涵盖 Llama 3、Mistral、Qwen(通义千问)、Gemma 等多种开源模型。
使用命令行拉取模型
在终端中输入以下命令即可下载并运行模型:ollama run llama3
首次运行时,Ollama 会自动从官方仓库下载模型权重文件,下载速度取决于网络状况,国内用户若遇到连接超时,可配置镜像源或使用代理,下载完成后,你将进入交互式对话界面,可以直接输入问题,模型会即时回答。
模型选择与量化技术
为了在有限硬件上运行更大模型,Ollama 采用了量化技术。llama3:8b-q4_K_M 表示使用 4-bit 量化版本的 8B 模型,量化会在保持较高精度的同时,显著减少内存占用。
- Q4_K_M:平衡了速度与精度,适合大多数用户。
- Q8_0:高精度版本,适合对准确性要求极高的场景,但占用更多资源。
- F16:全精度版本,仅适用于拥有极大内存的高端工作站。
自定义模型与本地部署
除了官方模型,用户还可以导入本地 GGUF 格式的模型文件,只需创建一个 Modelfile,指定基础模型和量化参数,然后使用 ollama create 命令构建自定义模型,这种方式允许高级用户微调模型行为,或加载特定领域的数据集。
常见问题与优化建议
在实际使用过程中,用户可能会遇到一些典型问题,以下针对高频疑问提供解决方案。
如何查看已安装的模型?
在终端输入 ollama list 即可列出所有已下载的模型及其大小,若需删除不再需要的模型,可使用 ollama rm <模型名> 命令释放磁盘空间。

模型响应速度慢怎么办?
响应速度主要受硬件瓶颈影响。
- 检查 GPU 占用:使用任务管理器或 `nvidia-smi` 确认 GPU 是否被正确调用,若未调用,检查驱动和环境变量配置。
- 减少并发请求:本地资源有限,避免同时运行多个大模型实例。
- 调整量化等级:若内存不足,尝试降低量化位数,如从 Q8 降至 Q4。
如何实现 API 调用?
Ollama 默认启动一个本地 API 服务器,地址为 http://localhost:11434,开发者可以使用 Python、JavaScript 等语言通过 HTTP 请求与该服务器交互,实现将本地大模型集成到自己的应用中,使用 requests 库发送 POST 请求到 /api/generate 端点,即可获取模型生成内容。
Ollama安装大模型教程常见问题解答
Q1:Ollama 支持哪些具体的大模型?
Ollama 支持数百种开源模型,包括但不限于 Meta 的 Llama 3、Mistral AI 的 Mistral、阿里巴巴的 Qwen(通义千问)、Google 的 Gemma 以及 Microsoft 的 Phi 系列,用户可通过 ollama pull <模型名> 命令获取任意支持的模型。
Q2:安装 Ollama 后,如何确保数据完全本地化?
Ollama 默认将所有模型文件存储在本地磁盘,推理过程完全在本地 CPU 或 GPU 上执行,不向任何外部服务器发送数据,除非用户主动配置代理或修改网络设置,否则所有交互均在本地闭环完成,确保数据隐私。
Q3:Windows 用户遇到 CUDA 错误该如何解决?
若出现 CUDA 相关错误,首先确认 NVIDIA 显卡驱动已更新至最新版本,并安装了与驱动匹配的 CUDA Toolkit,检查系统环境变量中是否正确添加了 CUDA 路径,若仍无法解决,可尝试使用 CPU 模式运行,虽然速度较慢,但能保证基本功能可用。
通过上述步骤,你可以轻松在本地搭建起强大的人工智能助手,Ollama 以其简洁的设计和强大的兼容性,降低了大模型的使用门槛,让每个人都能拥有专属的 AI 伙伴,掌握这一工具,意味着你已迈出了本地化 AI 应用的关键一步。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/400696.html