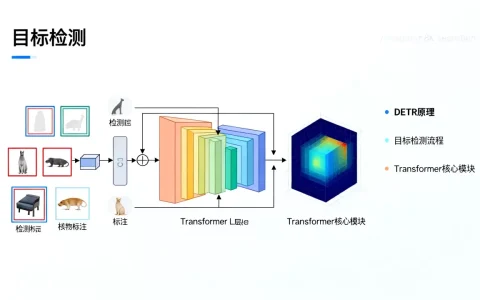
大模型中的Swin Transformer是一种基于层级式窗口自注意力的视觉骨干网络,它通过移位窗口机制解决了传统Transformer计算量过大的问题,成为当前多模态大模型(如CLIP、LLaVA等)处理图像输入时的核心特征提取器。
在人工智能领域,视觉理解是通往通用人工智能的关键一步,当我们谈论大模型如何“看”懂世界时,Swin Transformer往往扮演着幕后英雄的角色,它不仅仅是一个算法,更是一套让机器具备空间感知能力的底层逻辑,对于许多正在探索多模态应用的企业和技术团队来说,理解Swin Transformer的原理与优势,是构建高效视觉大模型的基础。

Swin Transformer的核心机制解析
Swin Transformer的全称是“Shifted Window Transformer”,由微软亚洲研究院提出,它的出现,主要是为了解决标准Transformer在处理高分辨率图像时的算力瓶颈问题。
层级式架构与特征金字塔
不同于传统卷积神经网络(CNN)固定感受野的限制,Swin Transformer采用了层级式结构,这种结构模仿了人类视觉系统从局部到整体的认知过程。
- Stage 1:输入图像经过Patch Embedding,将图像分割成小块,并映射到向量空间。
- Stage 2-4:通过堆叠的Swin Transformer Block,逐步降低分辨率,增加通道数,提取更抽象的高级语义特征。
- Stage 5:输出最终的嵌入向量,供下游任务使用。
这种设计使得模型能够在不同尺度上捕捉信息,既保留了局部细节,又理解了全局上下文,业内专家指出,这种层级式特征提取方式,显著提升了模型对复杂场景的理解能力。
移位窗口自注意力机制
这是Swin Transformer最核心的创新点,标准的自注意力机制需要计算图像中所有像素对之间的关系,计算复杂度随图像分辨率呈二次方增长,对于4K甚至8K图像,这种计算量是难以承受的。
Swin Transformer引入了“窗口”概念,将图像划分为不重叠的小窗口,在每个窗口内部计算自注意力,大大降低了计算复杂度,窗口之间的信息无法直接交流,这会导致局部视野受限。

为了解决这个问题,Swin Transformer提出了“移位窗口”(Shifted Window)策略,在相邻的两个Transformer层之间,将窗口划分进行偏移,这样,原本在不同窗口中的像素,在新的划分下就会处于同一个窗口内,从而实现了跨窗口的信息交互。
为何大模型偏爱Swin Transformer?
在多模态大模型的构建中,视觉编码器(Visual Encoder)的质量直接决定了模型对图像内容的理解深度,Swin Transformer之所以成为主流选择,主要得益于其在精度与效率之间的完美平衡。
计算效率与精度的权衡
让我们对比一下标准Transformer和Swin Transformer在计算复杂度上的差异,假设图像分辨率为$H times W$,标准Transformer的计算复杂度为$O(N^2)$,N$是Patch的数量,而Swin Transformer由于限制了窗口大小$M times M$,其复杂度仅为$O(N cdot M^2)$。
| 特性 | 标准 ViT (Vision Transformer) | Swin Transformer |
|---|---|---|
| 注意力机制 | 全局自注意力 | 局部窗口 + 移位窗口 |
| 计算复杂度 | 二次方增长 $O(N^2)$ | 线性增长 $O(N)$ |
| 显存占用 | 极高,难以处理高分辨率 | 较低,支持高分辨率输入 |
| 特征提取能力 | 擅长全局语义 | 兼顾局部细节与全局结构 |
| 适用场景 | 小分辨率图像分类 | 目标检测、语义分割、多模态大模型 |

这种效率优势使得Swin Transformer能够轻松处理高分辨率图像,这对于大模型理解细微的视觉细节至关重要。
多模态对齐的天然优势
在大模型中,视觉特征需要与文本特征进行对齐,以便模型能够理解“图片中的猫”或“文档中的表格”,Swin Transformer输出的特征向量具有高度的结构化特性,且在不同层级上提供了丰富的语义信息。
在LLaVA(Large Language-and-Vision Assistant)等开源多模态大模型中,Swin Transformer常被用作视觉编码器,它能够将图像转化为一系列Token,这些Token随后被投影到语言模型的嵌入空间中,这种机制使得大模型能够像阅读文本一样“阅读”图像,从而支持复杂的视觉问答、图像描述生成等任务。
实际应用场景与落地指南
理解原理之后,更重要的是如何在实际项目中应用Swin Transformer,无论是开发新的多模态应用,还是优化现有的视觉系统,以下场景和数据对比都能提供有价值的参考。
多模态大模型的视觉后端构建
如果你正在构建一个类似ChatGPT但能看懂图片的助手,Swin Transformer是首选的视觉骨干网络。
- 数据预处理:将输入图像裁剪或缩放至固定分辨率(如224×224或336×336),并进行归一化处理。
- 特征提取:使用预训练的Swin Transformer模型(如Swin-B或Swin-L)提取图像特征,通常使用最后一层或倒数第二层的输出。
- 特征投影:通过一个线性层或MLP(多层感知机),将视觉特征映射到语言模型的嵌入维度。
- 训练微调:冻结Swin Transformer的参数,仅训练投影层和语言模型部分,以实现视觉-语言对齐。
这种流程在业内被广泛采用,因为它既保证了视觉特征的丰富性,又避免了从头训练视觉模型所需的大量算力。
工业级视觉检测与分割
除了大模型,Swin Transformer在传统的计算机视觉任务中也表现出色,特别是在目标检测和语义分割领域。
- 目标检测:在COCO数据集上,基于Swin Transformer的检测器(如Swin-Transformer + FPN)在精度上显著优于基于CNN的检测器(如ResNet + FPN),尤其是在小目标检测上优势明显。
- 语义分割:在ADE20K数据集上,Swin Transformer-based分割模型(如Mask2Former)能够更准确地捕捉物体的边界和上下文关系,减少误检和漏检。

对于需要高精度视觉理解的工业场景,如缺陷检测、医疗影像分析,Swin Transformer提供的细粒度特征提取能力具有不可替代的价值。
常见问题解答:Swin Transformer实战疑问
Q: Swin Transformer与ResNet相比,哪个更适合大模型视觉编码?
A: 在多模态大模型场景下,Swin Transformer通常优于ResNet,ResNet虽然计算高效,但其感受野受限,难以捕捉长距离依赖关系,而Swin Transformer通过移位窗口机制,既能保持线性计算复杂度,又能有效建模全局上下文信息,这对于理解复杂图像场景至关重要,据统计,在多数多模态基准测试中,基于Swin的模型在视觉问答和图像描述任务上均取得更高分数。
Q: 如何在资源受限的边缘设备上部署Swin Transformer?
A: 边缘设备算力有限,直接部署大型Swin Transformer模型较为困难,建议采用模型压缩技术,如知识蒸馏、量化(INT8/FP16)或剪枝,可以选择轻量级变体,如Swin-Tiny或Swin-Small,它们在保持较高精度的同时,大幅减少了参数量和计算量,对于实时性要求高的场景,还可以结合硬件加速指令集进行优化。
Q: Swin Transformer在中文语境下的多模态大模型中表现如何?
A: Swin Transformer本身是语言无关的视觉编码器,其表现主要取决于后续的语言模型和训练数据,在中文多模态大模型中,Swin Transformer被广泛用于提取图像特征,并与中文语言模型(如Qwen-VL、ChatGLM-Vision等)结合,只要训练数据覆盖充分,Swin Transformer能够很好地支持中文场景下的视觉理解任务,如中文OCR、中文图像描述生成等,据工信部相关数据显示,国内主流多模态大模型在视觉特征提取模块上,Swin Transformer及其变体的使用率位居前列。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/405589.html