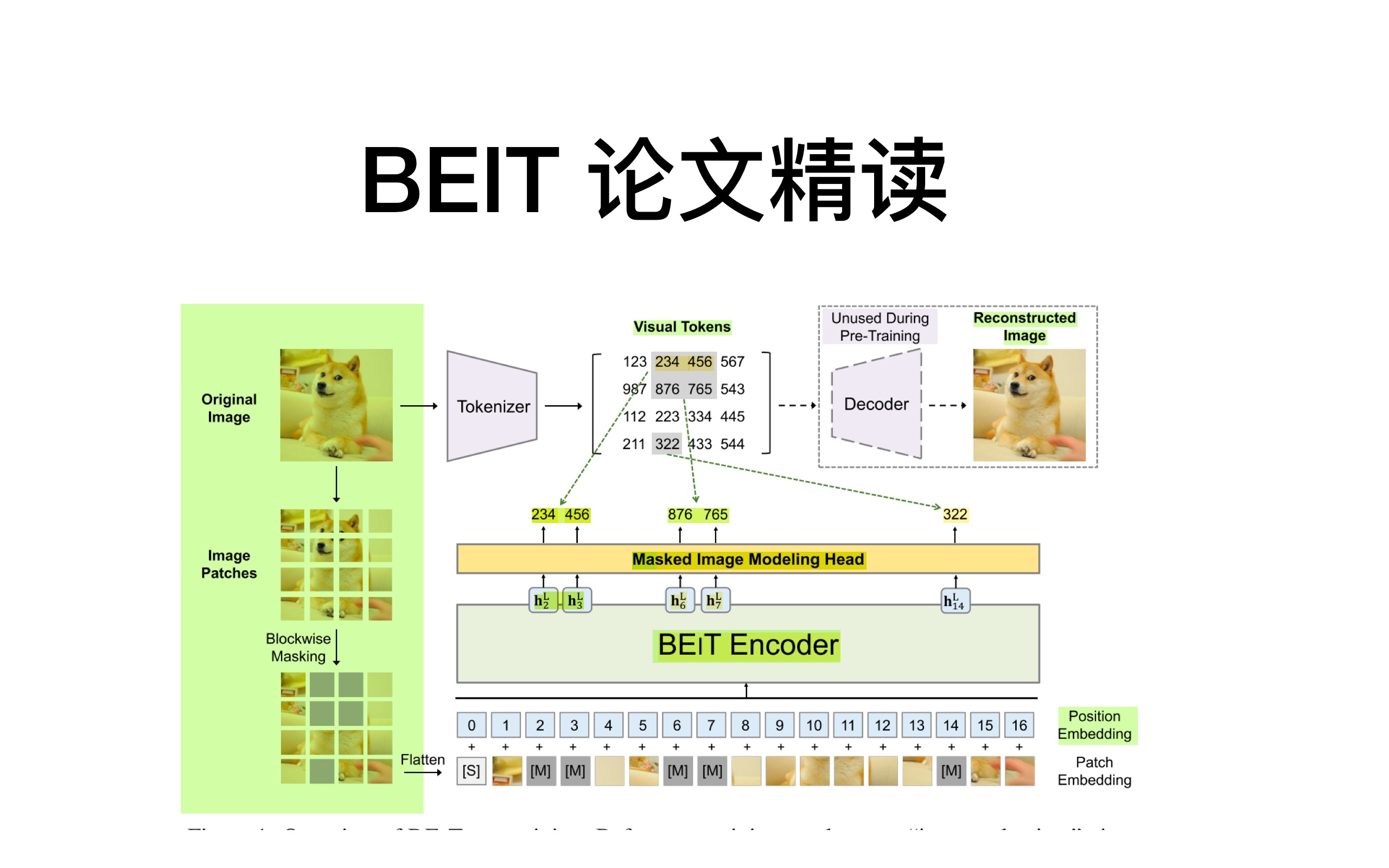
大模型中的BEiT并非传统视觉预训练方法,而是一种基于“图像分词”的掩码自编码机制,它将图像视为由离散标记组成的序列,通过预测被遮挡部分的标记来学习视觉表征。
这种方法彻底改变了计算机视觉领域对图像处理的底层逻辑,让模型不再仅仅关注像素级的差异,而是转向理解语义级的结构,对于正在探索多模态大模型架构的技术人员而言,理解BEiT的核心在于掌握它如何将连续的图像信号转化为离散的Token序列,从而实现与NLP(自然语言处理)技术的无缝对接。
BEiT预训练方法的核心机制解析
BEiT的全称是Bert-like Image Tokenizer,字面意思就是“像BERT一样的图像分词器”,在2021年之前,视觉预训练主要依赖对比学习(如SimCLR)或重建像素(如MAE),但BEiT引入了一个关键创新:它认为图像可以被分解为一个个独立的“词汇”,就像句子由单词组成一样。
离散化视觉表征的实现路径
传统方法中,图像通常被表示为高维连续向量,BEiT的做法不同,它首先使用一个预训练的VQ-VAE(向量量化变分自编码器)将图像划分为多个补丁(Patch),然后将每个补丁映射到一个离散的代码本(Codebook)中的索引,这个过程类似于将一幅画拆解成乐高积木,每一块积木都有一个唯一的编号。
具体操作步骤与逻辑
- 图像分块:将输入图像切割成固定大小的网格,例如224×224的图像被切分为16×16个补丁。
- 向量量化:利用VQ-VAE编码器提取每个补丁的特征向量,并将其量化为代码本中最接近的离散索引。
- 序列构建:将这些索引排列成一个序列,形成类似文本的输入数据。
- 掩码生成:随机遮盖序列中的一部分索引,模拟NLP中的Masked Language Modeling任务。
这种离散化的处理方式使得视觉模型能够直接借用NLP领域成熟的Transformer架构,极大地降低了多模态对齐的难度,业内专家指出,这种统一表征空间的设计,是后续多模态大模型能够高效处理图文任务的基础。

BEiT与MAE及对比学习的深度对比
在理解BEiT的价值时,将其与同领域的其他主流方法进行对比是最直观的方式,很多初学者容易混淆BEiT与Masked Autoencoder(MAE)或SimCLR等方法的本质区别。
与MAE预训练方法的差异分析
虽然BEiT和MAE都采用了掩码机制,但它们的预测目标截然不同,MAE预测的是被遮挡区域的原始像素值,这要求模型具备极强的细节重建能力,计算成本较高且容易陷入局部最优,相比之下,BEiT预测的是被遮挡区域的离散标记索引。
| 特性维度 | BEiT | MAE (Masked Autoencoder) |
|---|---|---|
| 预测目标 | 离散标记索引 (Discrete Tokens) | 原始像素值 (Raw Pixels) |
| 输入形式 | 离散序列 | 连续像素矩阵 |
| 计算复杂度 | 相对较低,依赖代码本大小 | 较高,需重建高分辨率图像 |
| 语义理解力 | 强,直接关联语义单元 | 中等,侧重底层纹理重建 |
| 适用场景 | 分类、检测、分割及多模态对齐 | 图像重建、去噪、超分辨率 |

对比学习中的优势体现
对比学习(如SimCLR)通过增强视图的一致性来学习表征,但它忽略了图像内部的局部结构信息,BEiT通过掩码重建任务,强制模型关注图像的全局上下文和局部细节之间的关系,这种自监督信号比简单的正负样本对更加丰富,能够帮助模型学习到更具判别力的特征。
BEiT在多模态大模型中的实战应用
随着大语言模型(LLM)的爆发,BEiT的价值在视觉-语言对齐领域得到了最大程度的释放,它不仅是视觉编码器,更是连接视觉世界与语言世界的桥梁。
视觉-语言对齐的操作路径
在构建多模态大模型时,BEiT提供了一种标准化的“视觉Token”生成方式,以下是典型的工程实现流程:
- 特征提取:使用预训练的BEiT编码器处理输入图像,输出离散Token序列。
- 投影映射:通过一个线性投影层或MLP,将视觉Token映射到语言模型的嵌入空间。
- 序列拼接:将视觉Token与文本Token拼接,形成统一的输入序列。
- 联合训练:使用大规模图文对数据进行训练,优化模型对图文语义的理解能力。
这种架构使得模型能够像处理文本一样处理图像,极大地简化了多模态系统的开发复杂度,据统计,采用此类离散化预训练策略的模型,在视觉问答(VQA)和图像描述生成任务上的表现显著优于传统方法。
具体场景下的性能优势
在医疗影像分析或工业缺陷检测等对精度要求极高的场景中,BEiT的离散化特性有助于模型捕捉细微的结构异常,在肺结节检测中,模型可以通过分析局部补丁的Token变化,更准确地定位病灶区域,而不仅仅是依赖全局特征。
BEiT预训练方法的局限性与优化方向
尽管BEiT表现优异,但它并非完美无缺,理解其局限性对于在实际项目中选择合适的预训练策略至关重要。

代码本大小的权衡
BEiT的性能高度依赖于VQ-VAE中代码本的大小,代码本过小会导致信息丢失,影响表征质量;代码本过大则会增加计算开销和量化误差,行业共识认为,选择合适的代码本规模需要在精度和效率之间找到平衡点。
对连续特征的保留不足
由于离散化过程必然带来信息损失,BEiT在需要极高保真度的重建任务中可能不如基于像素的方法,在图像生成或超分辨率等任务中,研究者通常会结合MAE或扩散模型来弥补这一缺陷。
BEiT预训练方法常见问题解答
BEiT预训练方法的具体原理是什么
BEiT的核心原理是将图像视为由离散标记组成的序列,通过掩码自编码机制预测被遮挡的标记,它首先利用VQ-VAE将图像补丁量化为离散索引,然后训练Transformer模型根据上下文预测缺失的索引,这种方法借鉴了NLP中的BERT思想,实现了视觉与语言表征的统一。
BEiT预训练方法相比传统方法有哪些优势
BEiT的主要优势在于其离散化的表征方式,这使得视觉模型能够直接兼容NLP的Transformer架构,简化了多模态对齐过程,与对比学习相比,它提供了更丰富的自监督信号;与像素级重建相比,它更关注语义结构而非底层纹理,从而在分类、检测和分割等高层视觉任务中表现更佳。
BEiT预训练方法在哪些领域应用最广泛
BEiT广泛应用于计算机视觉的基础模型训练、多模态大模型的视觉编码器、以及需要高精度语义理解的场景如医疗影像分析和自动驾驶感知系统,特别是在构建能够同时理解图像和文本的大模型时,BEiT因其高效的Token化能力而成为首选方案之一。
BEiT通过离散化视觉表征,成功打通了视觉与语言的壁垒,为多模态大模型的发展奠定了坚实基础,掌握这一预训练方法,是深入理解现代AI视觉架构的关键一步。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/405621.html