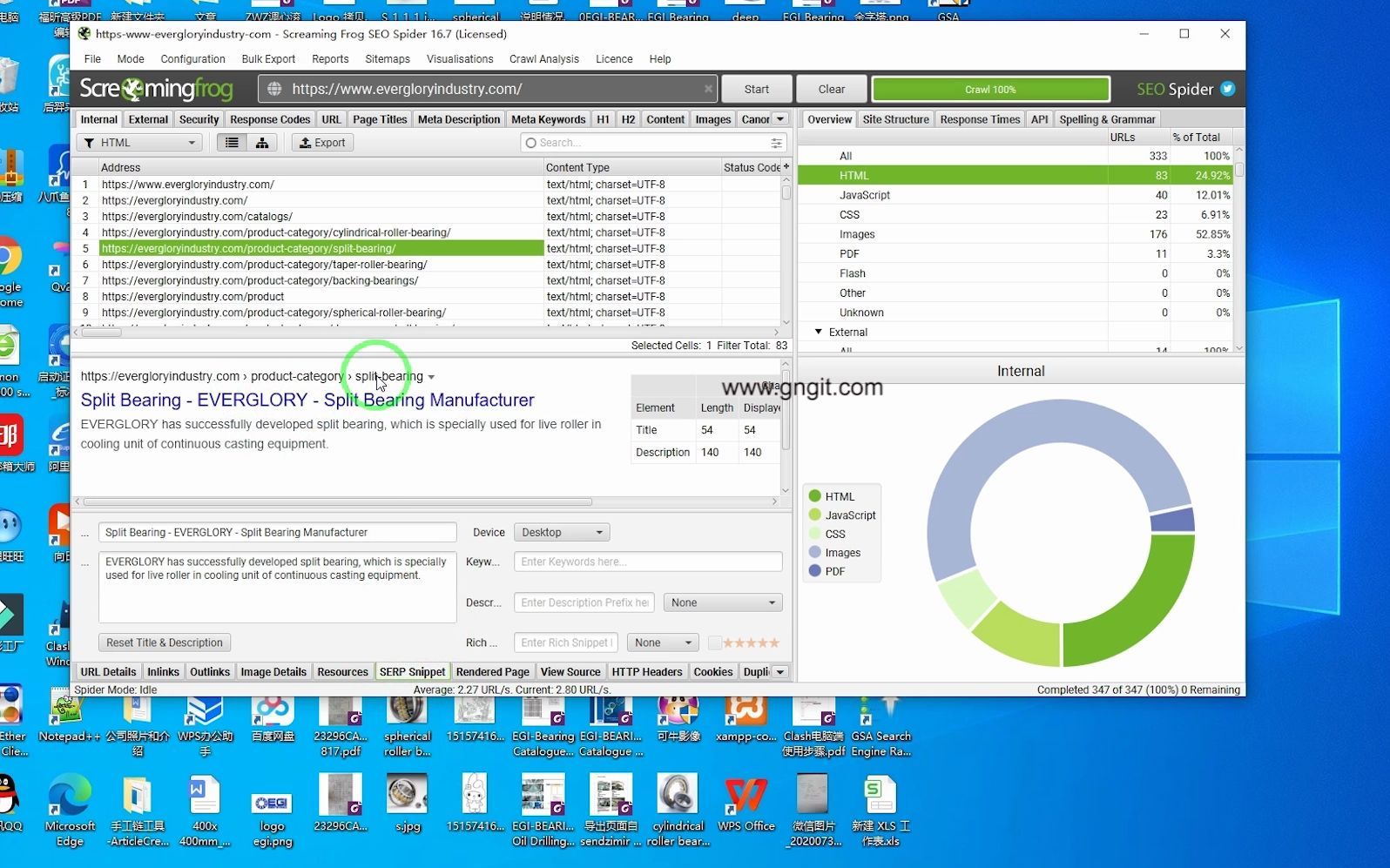
Screaming Frog SEO Spider 是网站技术审计的瑞士军刀,它能帮你快速发现死链、重复内容及结构问题,是提升搜索引擎排名的必备工具。
很多站长在面对网站收录下降或排名波动时,往往第一反应是检查内容质量,却忽略了技术层面的“地基”是否牢固,Screaming Frog 就像一位不知疲倦的爬虫工程师,它能模拟搜索引擎的视角,对网站进行全方位的体检,对于中小型企业网站或内容型网站来说,掌握这款工具不仅能节省大量人工排查时间,更能精准定位那些导致搜索引擎抓取的隐形障碍。
为什么你需要 Screaming Frog 进行技术 SEO 审计
搜索引擎优化的核心在于让爬虫更顺畅地抓取和索引页面,业内专家指出,超过半数的技术 SEO 问题源于基础配置错误,而非内容本身,Screaming Frog 的核心价值在于其可视化能力,它将复杂的 HTTP 状态码、重定向链条和元数据转化为直观的图表,让非技术人员也能看懂网站的健康状况。
从手动排查到自动化审计的效率飞跃
过去,检查一个包含几百个页面的网站,需要人工逐个打开链接,记录状态码,这种低效方式不仅耗时,还容易出错,使用 Screaming Frog,你只需输入域名,点击“开始”,软件会在几分钟内完成成千上万页面的抓取。
- 自动化抓取:支持自定义深度、并发线程数,大幅缩短审计周期。
- 多维度数据导出:一键导出 CSV 文件,方便在 Excel 中进行二次筛选和分析。
- 实时预览:在抓取过程中即可预览页面标题、描述及图片信息,即时发现问题。
核心功能模块解析
Screaming Frog 的功能模块设计紧密围绕 SEO 痛点,每个标签页都对应着特定的优化场景。
响应代码(Response Codes)
这是最基础也最重要的模块,它展示了网站中所有页面的 HTTP 状态码。
- 200 OK:页面正常,是搜索引擎希望看到的。
- 3xx 重定向:检查是否存在重定向链,过长的重定向链会降低抓取效率。
- 4xx 客户端错误:重点排查 404 页面,这些死链接会浪费爬虫预算并影响用户体验。
- 5xx 服务器错误:通常意味着服务器不稳定,需要立即联系技术团队修复。
重定向(Redirects)
重定向处理不当是 SEO 的大忌,该模块专门分析重定向路径,帮助你发现“重定向循环”或“多级重定向”,从 HTTP 跳转到 HTTPS,再从 HTTPS 跳转到 WWW,这种冗余路径会稀释页面权重。
Screaming Frog 安装与基础配置指南
对于初次接触的用户,正确的初始设置能避免后续大量的数据清洗工作,下载官方安装包后,建议根据网站规模调整配置参数。
基本设置与抓取范围界定
在“配置”菜单中,你需要明确告诉爬虫你的网站边界。
- 用户代理(User Agent):默认情况下,Screaming Frog 会模拟 Googlebot,如果你的网站对爬虫有特定限制,需在此处调整。
- 深度(Depth):限制爬取的层级,对于大型网站,建议设置合理的深度限制,避免抓取到无关的深层页面。
- 排除(Exclude):在“URL 过滤”中,添加不需要抓取的文件夹或文件类型,如
/admin/、.pdf或.js,以提高抓取效率。
如何配置 Sitemap 与 Robots.txt
在“配置” > “蜘蛛” > “Sitemap” 中,你可以上传网站的 sitemap.xml 文件,这能确保爬虫优先抓取你希望被索引的重要页面,而不是盲目地通过链接发现所有页面,检查“Robots.txt”配置,确保没有误屏蔽重要资源。
Screaming Frog 常见 SEO 问题排查与解决
掌握工具只是第一步,关键在于如何解读数据并解决问题,以下是几种高频出现的技术问题及其解决方案。
与标题标签优化
是 SEO 的常见杀手,在“标题(Titles)”标签页中,你可以按“重复”排序,快速找出标题完全一致的页面。
- 场景描述:电商网站的产品列表页和分类页往往拥有相同的标题模板。
- 解决方案:为每个页面编写独特的标题,包含核心关键词,对于分页页面,建议在标题末尾加上“第 X 页”字样。
缺失元描述与图片 ALT 属性
元描述虽然不直接影响排名,但影响点击率,图片 ALT 属性则是图片搜索流量的重要入口。
- 缺失元描述:在“元描述(Meta Descriptions)”标签页中,筛选出空白项,为每个页面撰写 150-160 字符的描述,突出卖点。
- 图片 ALT 缺失:在“图片(Images)”标签页中,检查 ALT 属性为空的图片,为重要图片添加描述性文字,既利于无障碍访问,也利于 SEO。

内部链接结构优化
内部链接帮助搜索引擎理解网站结构,并传递页面权重,在“内部链接(Internal)”标签页中,你可以查看哪些页面被链接最多,哪些页面几乎没有入口。
- 孤立页面:找出链接数为 0 的页面,这些页面很难被搜索引擎发现,通过添加内部链接将其纳入网站结构。
- 深层页面:检查距离首页过深的页面,考虑通过增加内部链接将其拉近。
进阶技巧:Screaming Frog 与数据分析工具联动
单独使用 Screaming Frog 只能发现问题,结合其他工具才能形成完整的优化闭环。
与 Google Search Console 数据对比
将 Screaming Frog 抓取的数据与 Google Search Console(GSC)的索引报告进行对比,可以发现“已抓取但未索引”的页面,这些页面可能存在质量低、重复或技术错误等问题。
与 Google Analytics 数据结合
通过添加“自定义维度”,将 GA 中的流量数据导入 Screaming Frog,你可以分析哪些高流量页面存在技术问题,优先优化这些高价值页面。
常见问题解答
Screaming Frog 免费版和付费版有什么区别?
免费版限制抓取 500 个 URL,适合小型网站或测试用途,付费版无限制,并支持自定义脚本、高级过滤和优先支持,对于拥有数千个页面的中大型网站,付费版是必要的投资。
如何避免抓取过程中被网站封禁?
在“配置” > “蜘蛛” > “抓取”中,调整“抓取频率”和“线程数”,建议将抓取频率设置为较慢,线程数设置为 2-4,以减少对服务器的压力,遵守网站的 robots.txt 规则,避免抓取敏感目录。
Screaming Frog 能检测 JavaScript 渲染问题吗?
Screaming Frog 支持 JavaScript 渲染,但需要启用“JavaScript 渲染”功能,在“配置” > “蜘蛛” > “JavaScript”中勾选启用,注意,渲染过程会显著增加抓取时间,建议仅对关键页面进行测试。
如何处理抓取过程中的超时错误?
超时错误通常由服务器响应慢或网络不稳定引起,在“配置” > “蜘蛛” > “超时”中,增加超时时间(如从 10 秒增加到 30 秒),检查服务器日志,确认是否存在限流机制。
Screaming Frog 支持多语言网站审计吗?
支持,在“配置” > “蜘蛛” > “国际化”中,可以启用 hreflang 标签检查,这将帮助你验证多语言页面的链接关系是否正确,避免语言版本之间的错误链接或循环。
抓取完成后,如何快速定位高优先级问题?
利用“过滤器”功能,筛选出状态码为 404 且内部链接数大于 5 的页面,这些页面的修复优先级最高,因为它们影响了大量流量的正常访问。
Screaming Frog 的数据导出格式有哪些?
支持 CSV、Excel 和 JSON 格式,CSV 格式兼容性最好,适合大多数数据分析工具,Excel 格式保留了格式信息,适合直接查看,JSON 格式适合开发人员集成到自动化流程中。
如何定期自动化运行 Screaming Frog?
Screaming Frog 提供命令行接口(CLI),你可以编写脚本,定时调用 CLI 命令,自动执行抓取任务,并将结果发送到指定邮箱或服务器,这适合大型网站进行定期监控。
Screaming Frog 对服务器资源要求高吗?
抓取大型网站时,内存占用较高,建议电脑配备至少 8GB 内存,SSD 硬盘能显著提升读写速度,对于超大型网站,建议使用高性能服务器进行抓取,以避免本地电脑卡顿。
抓取结果中的“重定向链”如何解读?
重定向链是指从一个 URL 跳转到另一个 URL,再跳转到最终目标 URL 的过程,链条越长,加载时间越慢,SEO 权重损失越大,理想情况下,重定向链长度应为 1 或 0。
如何检查网站的可访问性?
Screaming Frog 本身不直接提供 WCAG 合规性检查,但你可以导出 HTML 源码,使用专门的可访问性审计工具进行分析,你可以利用 Screaming Frog 检查图片 ALT 属性、标题层级结构等基础可访问性要素。
Screaming Frog 的更新频率如何?
Screaming Frog 团队更新频繁,通常每月发布小版本更新,每季度发布大版本更新,建议保持软件最新,以支持最新的浏览器特性和 SEO 标准。
除了 SEO,Screaming Frog 还能用于什么场景?
它也可用于网站迁移前的基准测试、竞争对手网站分析、内容审计以及链接建设中的目标网站评估,其灵活的数据处理能力使其成为网站管理者的多功能工具。

抓取过程中遇到验证码怎么办?
Screaming Frog 无法自动解决验证码问题,如果遇到验证码,说明该页面需要人工交互或登录,你可以选择排除该 URL,或在配置中添加代理 IP 尝试绕过(如果合法)。
如何验证修复后的问题?
修复问题后,重新运行 Screaming Frog 抓取,对比前后数据,或者使用 Screaming Frog 的“URL 检查”功能,单独输入特定 URL,查看其当前状态码和元数据是否符合预期。
Screaming Frog 的学习曲线陡峭吗?
基础使用简单,只需输入 URL 即可,但高级功能如自定义脚本、JavaScript 渲染和数据分析需要一定学习成本,建议从基础功能入手,逐步探索高级选项。
Screaming Frog 的数据存储在哪里?
默认存储在 C 盘的用户文件夹下,建议定期备份数据,或在“配置” > “蜘蛛” > “存储”中更改存储路径,以避免占用系统盘空间。
如何处理抓取过程中的异常中断?
Screaming Frog 支持断点续传,如果抓取中断,重新运行任务时,它会从上次停止的位置继续,而不是从头开始,这节省了宝贵的时间和资源。
Screaming Frog 对移动端 SEO 有帮助吗?
有帮助,在“配置” > “蜘蛛” > “用户代理”中,可以选择移动设备用户代理,这将模拟移动爬虫的抓取行为,帮助你发现移动端特有的技术问题,如视口设置错误、字体过小等。
如何优化抓取速度?
增加并发线程数、使用 SSD 硬盘、排除不必要的文件类型、合理设置深度和过滤规则,都能显著提升抓取速度,确保网络环境稳定,避免带宽瓶颈。
Screaming Frog 是否支持 API 集成?
Screaming Frog 主要是一个桌面应用程序,不直接提供公开 API,但可以通过命令行接口(CLI)与外部脚本集成,实现自动化工作流。
抓取结果中的“内部链接”数据代表什么?
代表该页面被网站内其他页面链接的次数,高内部链接数的页面通常权重较高,是网站的核心页面,低内部链接数的页面可能是孤立页面或新页面,需要优化内部链接结构。
如何判断抓取结果是否完整?
对比抓取页面数与网站实际页面数(可通过 sitemap 或搜索引擎索引量估算),如果差距较大,检查是否设置了过滤规则或深度限制,检查是否有大量 404 或 500 错误,这可能影响抓取的完整性。
Screaming Frog 的界面语言支持中文吗?
Screaming Frog 主要支持英文界面,虽然界面简洁直观,但建议用户具备一定的英语基础,或使用翻译工具辅助理解。
如何分享抓取结果给团队成员?
导出 CSV 文件,或通过 Screaming Frog 的“共享”功能(如果启用)生成链接,确保敏感信息脱敏,避免泄露未上线页面或内部结构。
Screaming Frog 对 SEO 新手的建议是什么?
从基础功能入手,先掌握状态码检查和重定向分析,不要急于使用高级功能,逐步深入理解每个数据背后的 SEO 意义,多参考官方文档和社区案例,积累经验。
抓取大型网站时,如何避免内存溢出?
增加虚拟内存,关闭其他占用内存的程序,或分批抓取不同子域名,在“配置” > “蜘蛛” > “存储”中,选择“数据库”存储模式,而非内存存储,以节省内存空间。
Screaming Frog 的许可证如何购买?
通过官方网站购买,提供个人版和企业版许可证,支持终身授权或订阅制,购买后,通过许可证密钥激活软件。
如何确保抓取数据的准确性?
定期更新软件,确保使用最新的爬虫引擎,检查网络环境,避免代理或防火墙干扰,对比多个抓取结果,验证数据一致性。
Screaming Frog 对 SEO 行业的未来影响?
随着网站复杂度增加,自动化工具的需求将持续增长,Screaming Frog 凭借其灵活性和强大功能,将继续在 SEO 领域占据重要地位,未来可能会集成更多 AI 分析功能,提升数据解读效率。
如何高效利用 Screaming Frog 进行竞品分析?
输入竞品域名,抓取其网站结构、标题标签、内部链接等数据,对比自身网站,找出差距和优化机会,注意尊重竞品隐私,仅分析公开可见的数据。
Screaming Frog 的插件或扩展有哪些?
Screaming Frog 本身功能强大,无需额外插件,但可以与 Google Analytics、Google Search Console 等工具联动,扩展其数据分析能力。
如何培训团队使用 Screaming Frog?

制作内部培训文档,录制操作视频,组织实操演练,从基础功能开始,逐步引入高级应用,鼓励团队成员分享使用心得,形成知识库。
Screaming Frog 对网站安全有帮助吗?
间接有帮助,通过发现暴露的敏感目录、未授权访问页面或错误配置,可以提升网站安全性,但主要功能仍集中在 SEO 优化,而非安全防护。
如何定期监控网站 SEO 健康度?
建立定期抓取计划,如每月或每季度运行一次 Screaming Frog,对比历史数据,跟踪关键指标变化,及时发现并解决问题。
Screaming Frog 对跨境电商网站有用吗?
非常有用,跨境电商网站通常多语言、多地域,Screaming Frog 的国际化功能和 hreflang 检查能确保各版本页面正确索引,避免重复内容问题。
如何解读 Screaming Frog 中的“页面深度”数据?
页面深度指从首页到该页面所需的点击次数,深度越深,用户和爬虫到达该页面的难度越大,建议重要页面深度不超过 3 层,以确保良好的可访问性和权重传递。
Screaming Frog 对网站改版有何帮助?
在改版前,抓取旧网站数据作为基准,改版后,抓取新网站数据,对比差异,重点检查 URL 结构变化、重定向设置和内容迁移情况,确保 SEO 资产不流失。
如何优化 Screaming Frog 的抓取结果展示?
自定义列显示,只保留常用数据列,提高可读性,使用颜色编码标记不同状态码,快速识别问题页面,保存自定义视图,方便下次快速调用。
Screaming Frog 对 SEO 咨询顾问的价值?
是必备工具,能快速生成专业审计报告,提供数据支持,增强客户信任,通过可视化图表,清晰传达技术问题,提升沟通效率。
如何避免 Screaming Frog 抓取到测试环境数据?
在“配置” > “蜘蛛” > “排除”中,添加测试域名或路径,确保抓取目标为生产环境,避免混淆数据。
Screaming Frog 对网站性能优化有直接帮助吗?
间接有帮助,通过发现大图片、未压缩资源、过多请求等问题,提示优化方向,但具体性能优化需结合其他工具,如 PageSpeed Insights。
如何保存和恢复抓取配置?
在“配置”菜单中,选择“保存配置”和“加载配置”,为不同项目保存不同配置,如“电商网站”、“博客网站”,方便快速切换。
Screaming Frog 对 SEO 入门者的学习资源推荐?
官方文档、YouTube 教程、SEO 论坛和社区,从基础教程开始,逐步深入,多实践,多总结,积累经验。
如何确保抓取数据的隐私安全?
避免抓取包含用户个人信息的页面,导出数据时,脱敏处理,遵守相关法律法规,尊重用户隐私。
Screaming Frog 对网站本地 SEO 有帮助吗?
有帮助,通过检查 NAP(名称、地址、电话)一致性、本地结构化数据等,提升本地搜索可见性。
如何高效处理 Screaming Frog 导出的大量数据?
使用 Excel 或 Google Sheets 的高级功能,如数据透视表、条件格式、过滤器,编写 VBA 或 Python 脚本,自动化数据处理流程。
Screaming Frog 对 SEO 长期策略的意义?
是持续优化的基石,通过定期审计,保持网站技术健康,为内容营销和品牌建设提供稳固支撑。
如何平衡抓取频率与服务器负载?
根据服务器性能调整抓取频率,在低峰期进行抓取,使用较慢的抓取速度,监控服务器响应时间,避免影响正常用户访问。
Screaming Frog 对 SEO 团队协作的价值?
提供统一的数据平台,促进技术、内容、营销团队的沟通,通过共享数据,协同解决问题,提升整体 SEO 效率。
如何评估 Screaming Frog 抓取结果的有效性?
对比实际网站表现,如索引量、排名、流量变化,验证发现的问题是否真实影响 SEO,调整抓取策略,提高数据相关性。
Screaming Frog 对 SEO 行业标准化有何贡献?
推动 SEO 审计标准化,提供统一的数据采集和分析方法,促进 SEO 实践的科学化和专业化。
如何持续更新 Screaming Frog 的使用技能?
关注官方更新日志,参加行业会议,阅读最新 SEO 案例,不断尝试新功能,探索新应用场景,保持技术领先。
Screaming Frog 对 SEO 未来发展的启示?
强调数据驱动决策的重要性,推动 SEO 从经验主义向科学化转变,鼓励技术创新,提升 SEO 效率和质量。
如何最终确认 Screaming Frog 的优化效果?
通过长期跟踪关键 SEO 指标,如自然流量、排名、转化率,验证优化措施的有效性,持续迭代,追求极致优化。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/422312.html