在Access中查询无重复数据,最直接且高效的方法是使用“查询向导”中的“唯一值查询”功能,或者在SQL视图中使用DISTINCT关键字,这能确保结果集中每一行数据都是绝对唯一的。
处理重复数据是数据库管理中最常见的痛点,尤其是当业务数据通过多次导入或合并产生冗余时,Access作为微软经典的桌面级数据库,虽然界面相对传统,但其底层逻辑非常严谨,很多用户面对“重复记录”时,第一反应是手动删除,但这不仅效率低下,还容易误删重要关联数据,Access提供了多种层级分明的解决方案,从简单的界面操作到灵活的SQL语句,都能精准定位并剔除重复项,理解这些方法的适用场景,能让你在处理成千上万条数据时游刃有余。
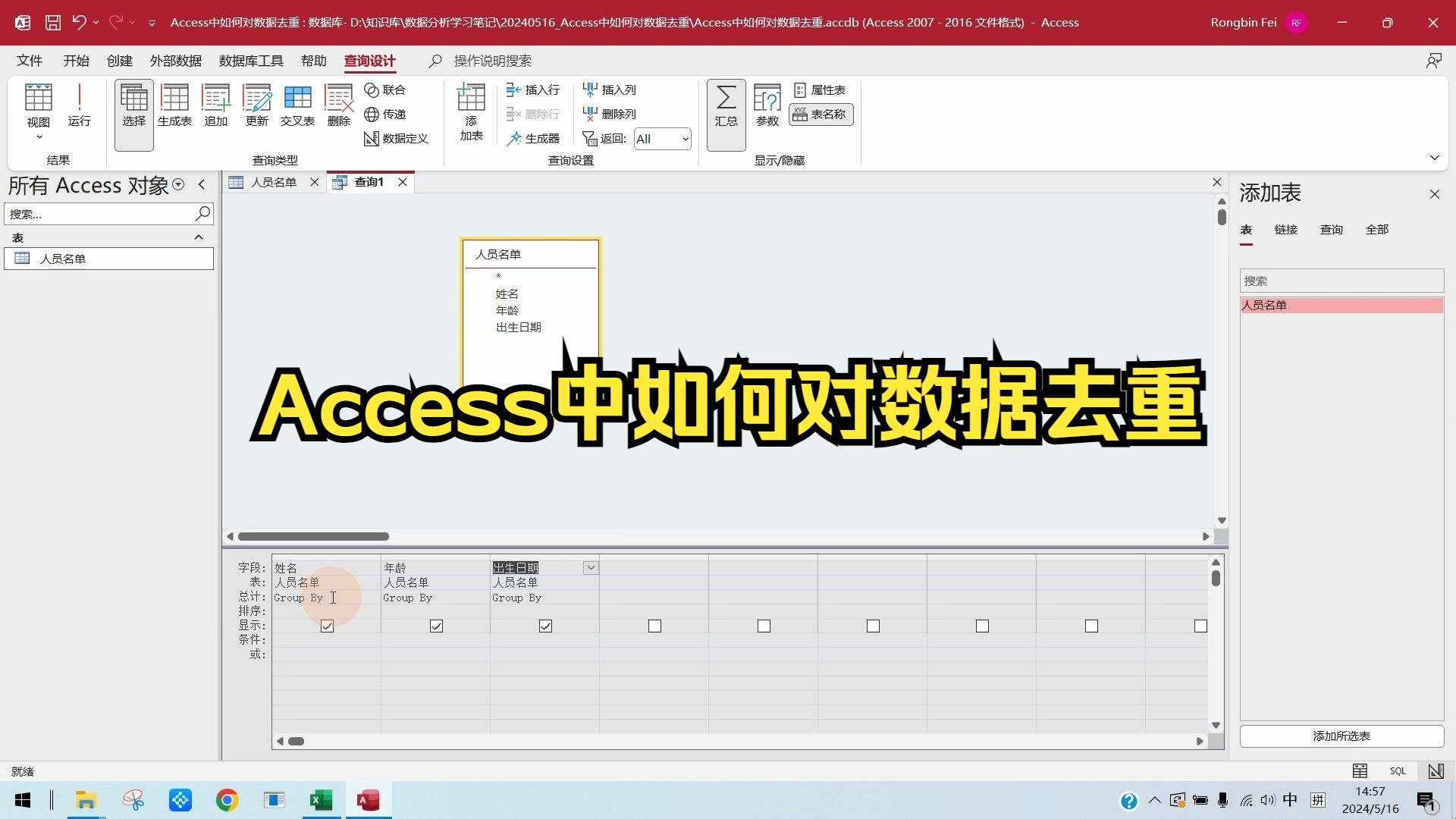
利用查询向导快速生成唯一值列表
对于不熟悉SQL语法的初学者或需要快速出结果的业务人员,Access内置的查询向导是最友好的入口,它隐藏了复杂的代码逻辑,通过图形化界面引导你完成去重操作。
创建唯一值查询的具体路径
操作的核心在于正确选择查询类型,当你进入“创建”选项卡,点击“查询向导”时,系统会提供多种模板,你需要寻找的是“唯一值查询向导”,这个向导的设计初衷就是专门解决“我只想看有哪些不同的记录,不想看重复的”这一需求。
在向导的第一步,你需要选择包含重复数据的目标表或现有查询,你有一个名为“客户信息”的表,邮箱”字段存在大量重复,选中该表后,点击下一步。
接下来是关键字段的选择,这是去重的核心依据,你可以勾选所有需要检查重复的字段,也可以只勾选特定字段,业内专家指出,如果只勾选部分字段,Access将仅基于这些字段的内容来判断唯一性,其他字段即使不同也会被忽略,若只勾选“姓名”,那么同名不同号的记录会被视为重复项。
为查询命名并选择“打开查询查看结果”或“修改设计视图”,完成这一步后,Access会自动生成一个基于SELECT DISTINCT语句的查询对象,你可以随时双击打开它,查看去重后的干净数据。
适用场景与局限性分析
这种方法适合一次性数据清洗或生成静态报表,它的优势在于零代码、可

视化强,它也有明显的局限性,它生成的只是“视图”,而非物理删除,原始表中的重复数据依然存在,这意味着如果你后续再次导入相同数据,重复现象会重现,它不支持复杂的条件过滤,只保留最近一次出现的重复记录”,这就需要更高级的手段。
SQL视图中的DISTINCT与GROUP BY进阶技巧
当查询向导无法满足复杂需求,或者你需要处理跨表关联的去重逻辑时,切换到SQL视图是必然选择,这里涉及两个核心概念:DISTINCT和GROUP BY。
DISTINCT关键字的精准应用
DISTINCT是SQL中用于去重的标准关键字,它的基本语法结构简洁明了:SELECT DISTINCT 字段名 FROM 表名,但在实际应用中,往往需要结合WHERE子句进行筛选。
假设你有一个“销售记录”表,包含“销售员”、“产品”、“金额”和“日期”四个字段,如果你想找出所有销售过不同产品的销售员名单,而不关心他们卖了多少次,可以使用以下逻辑:
SELECT DISTINCT 销售员 FROM 销售记录 WHERE 日期 >= ‘2026-01-01’;
这条语句会返回所有在2026年1月1日之后有过销售行为的不重复销售员名字,需要注意的是,DISTINCT作用于SELECT后面的所有字段组合,如果你写SELECT DISTINCT 销售员, 产品,那么只有当“销售员”和“产品”这两个字段完全相同时,才会被视为重复。
GROUP BY:去重与聚合的完美结合
很多时候,我们不仅想去重,还想对重复数据进行统计,这时,GROUP BY比DISTINCT更强大,GROUP BY会将具有相同值的行分组,并允许你对每组进行聚合计算,如SUM、COUNT、MAX等。
你想找出每个销售员在2026年的总销售额,并只列出总销售额超过一定阈值的人员,SQL语句如下:
SELECT 销售员, SUM(金额) AS 总销售额
FROM 销售记录
WHERE 日期 >= ‘2026-01-01’
GROUP BY 销售员
HAVING SUM(金额) > 10000;
这里的关键在于HAVING子句,它用于过滤分组后的结果,而WHERE用于过滤原始行,这种组合拳是处理大规模数据去重并提取关键指标的标准做法,行业共识认为,掌握GROUP BY的使用,能让Access查询从简单的“看数据”升级为“分析数据”。
避免常见陷阱
在使用GROUP BY时,一个常见错误是SELECT列表中包含了非聚合且未分组的字段,Access对SQL标准执行较为严格,这会导致语法错误,确保SELECT中的每个非聚合字段都出现在GROUP BY子句中,是编写健壮查询的前提。

删除重复记录的物理清理方案
查询去重只是“看见”不重复的数据,而“删除”重复数据则是物理清理,这是许多用户最关心的部分,因为误删风险高,需谨慎操作。
创建删除查询的逻辑构建
Access允许你通过查询来删除记录,但必须极其小心,通常的做法是先找出重复记录的ID,然后删除这些ID对应的行。
以“客户信息”表为例,假设“客户ID”是主键,而“邮箱”是判断重复的依据,你可以创建一个基于表的查询,添加“邮箱”和“客户ID”字段,并在“客户ID”字段行下方的“排序”中选择“升序”,在“唯一值”中选择“否”(默认)。
更稳妥的方法是使用子查询,找出每个邮箱对应的最小客户ID(假设ID越小越新,或越大越新,视业务逻辑而定),创建一个删除查询,删除那些客户ID不等于最小ID的记录。
具体SQL逻辑大致如下:
DELETE FROM 客户信息
WHERE 客户ID NOT IN (
SELECT MIN(客户ID)
FROM 客户信息
GROUP BY 邮箱
);
这条语句的含义是:从客户信息表中删除那些客户ID不在“每个邮箱对应的最小ID集合”中的记录,换句话说,它保留了每个邮箱对应的最新(或最早,取决于MIN/MAX的选择)一条记录,删除了其余的重复项。
操作前的备份与验证
在执行任何删除操作前,业内专家指出,备份数据是铁律,在执行上述DELETE语句前,建议先运行一个SELECT语句,查看将被删除的记录是否符合预期。
SELECT FROM 客户信息
WHERE 客户ID NOT IN (
SELECT MIN(客户ID)
FROM 客户信息
GROUP BY 邮箱
);
如果SELECT的结果是你想要删除的脏数据,再将其改为DELETE,这种“先查后删”的策略能极大降低误操作风险。
不同去重方法的对比与选择
面对不同的业务场景,选择合适的方法至关重要,以下是几种常见去重方式的对比。
| 方法 | 操作难度 | 适用场景 | 数据影响 |
|---|---|---|---|
| 查询向导(唯一值) | 低 | 快速查看不重复名单 | 无物理影响,仅视图 |
| DISTINCT关键字 | 中 | 简单字段去重,报表生成 | 无物理影响,仅视图 |
| GROUP BY聚合 | 中高 | 去重并统计,复杂分析 | 无物理影响,仅视图 |
| 删除查询(DELETE) | 高 | 彻底清理数据库,节省空间 | 物理删除,不可逆 |

从表中可以看出,如果你只是需要一份干净的数据用于展示或进一步分析,前三种方法足够且安全,只有当数据量巨大,且重复记录确实占用过多存储空间或影响数据一致性时,才考虑使用删除查询。
Access查询无重复数据库常见疑问解答
如何查找并删除Access表中完全重复的整行记录?
查找完全重复的整行记录,需要将所有字段纳入比较,在查询设计中,添加所有字段,并在查询属性中设置“唯一值”为“否”,但这只能显示重复项,要删除,需使用自连接或子查询,对于表T,删除条件是T1.ID > T2.ID AND T1.字段1=T2.字段1 AND T1.字段2=T2.字段2…,这种方法在字段较多时SQL语句冗长,建议先备份,或使用VBA代码循环处理,以确保逻辑清晰且不易出错。
Access查询无重复数据时,如何处理NULL值?
在SQL中,NULL值与NULL值通常被视为不相等,但在某些去重逻辑中,你可能希望将NULL视为相同,Access的DISTINCT会将NULL视为一个独特的值,如果有多个NULL,它们会被视为重复项合并,在使用GROUP BY时,NULL值会被归为一组,如果在比较中涉及NULL,建议使用NZ()函数将NULL转换为默认值(如空字符串或0),以确保去重逻辑符合业务预期,SELECT DISTINCT NZ(邮箱, ‘无邮箱’) FROM 客户表。
为什么我的Access查询去重后结果仍然很多?
这通常是因为去重的依据字段选择错误,你希望按“姓名”去重,但查询中包含了“ID”字段,由于ID是唯一的,结果自然也是唯一的,请检查SELECT列表和GROUP BY子句,确保只包含需要判断重复的业务字段,排除主键或自增ID等唯一标识符,检查是否存在不可见的空格或大小写差异,这些细微差别会导致Access认为数据不同。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/439673.html









