Hash系统负载均衡的核心在于通过哈希算法将请求均匀分发至后端节点,既解决了静态IP轮询的热点不均问题,又通过一致性哈希技术有效降低了节点变动带来的缓存失效风险,是构建高可用分布式系统的基石。
在分布式架构日益复杂的今天,如何保证海量用户请求能够平稳、高效地分发到不同的服务器节点上,是每一个系统架构师必须面对的难题,传统的轮询或随机算法虽然实现简单,但在实际生产环境中往往会导致某些节点负载过高,而其他节点闲置,甚至因为节点宕机引发雪崩效应,Hash系统负载均衡正是为了解决这一痛点而生的技术方案,它通过数学算法将用户特征或服务ID映射到具体的服务器节点上,实现了请求的稳定性和局部性。
Hash负载均衡的核心原理与实现机制
Hash负载均衡并非单一的技术,而是一系列基于哈希函数的策略集合,其基本逻辑是将客户端的请求参数(如IP地址、Session ID、URL等)作为输入,经过哈希函数计算后得到一个数值,再通过取模运算确定该请求应该由哪一台服务器处理。
传统取模哈希的局限性
最基础的实现方式是“哈希取模法”,假设我们有N台服务器,当请求到来时,计算 Hash(Request) % N 的结果,如果结果指向第i台服务器,则该请求由第i台处理,这种方法在服务器数量固定时表现良好,但一旦服务器扩容或缩容,整个哈希空间就会发生剧烈变化。
业内专家指出,当新增一台服务器时,N变为N+1,绝大多数原本分配给其他节点的请求都会重新计算哈希值,导致大量请求被重新路由到新的节点,这种“哈希震荡”不仅造成后端服务的瞬时压力激增,还会导致前端缓存(如CDN或本地缓存)大面积失效,严重影响用户体验。

一致性哈希算法的优化方案
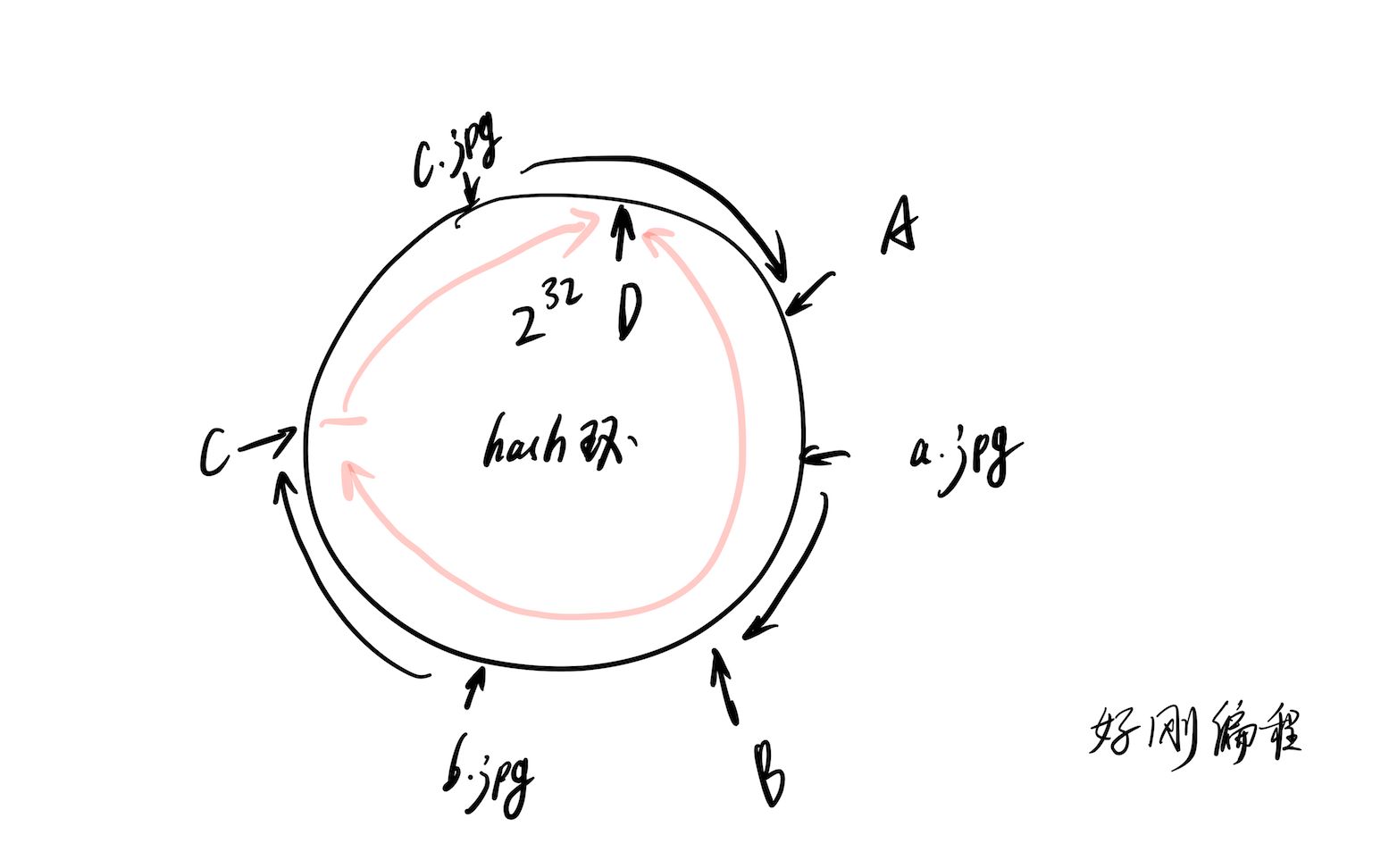
为了解决上述问题,一致性哈希算法(Consistent Hashing)应运而生,它将哈希空间组织成一个虚拟的环形结构,范围从0到2^32-1,服务器节点和请求数据都通过哈希函数映射到这个环上。
节点分布与请求路由
在处理请求时,系统沿顺时针方向查找距离请求哈希值最近的服务器节点,这种机制的优势在于,当增加或删除一个节点时,只有受影响的少量请求需要重新路由,大部分数据依然保持在原有的节点上,新增节点只会影响其逆时针方向到下一个节点之间的那部分数据,从而极大地减少了数据迁移量。
虚拟节点技术的应用
尽管一致性哈希解决了震荡问题,但如果物理节点数量较少,它们在环上的分布可能不均匀,导致负载倾斜,为了解决这个问题,引入了“虚拟节点”的概念,每个物理服务器在环上对应多个虚拟节点,这些虚拟节点均匀分布在哈希环上,通过调整虚拟节点的数量,可以精细控制负载均衡的粒度,确保各物理服务器的负载趋于均衡。
场景化部署与性能对比分析
不同的业务场景对负载均衡的要求各不相同,选择合适的Hash策略,需要结合具体的业务特征和数据量级进行考量。
缓存系统中的最佳实践
在Redis或Memcached等缓存系统中,一致性哈希是标配方案,因为缓存数据具有极强的局部性,频繁的数据迁移会导致缓存命中率下降,使用一致性哈希,可以确保同一用户的数据尽可能落在同一台缓存服务器上,减少跨节点访问带来的网络开销。
配置示例与参数调优
在实际配置中,建议为每台物理服务器设置至少100-200个虚拟节点,虚拟节点的分布应尽可能均匀,可以使用MD5或SHA1等强哈希函数生成虚拟节点的位置,还需定期监控各节点的负载情况,动态调整虚拟节点权重,以应对硬件性能差异带来的负载不均。

微服务架构中的服务发现
在Kubernetes或Service Mesh等微服务架构中,Hash负载均衡常用于基于会话粘性的流量分发,在支付系统中,同一用户的多次操作必须路由到同一实例,以保证事务的一致性。
基于Header的哈希策略
除了基于IP或URL,还可以基于HTTP Header中的特定字段(如User-ID、Trace-ID)进行哈希,这种方式更加灵活,能够适应复杂的业务逻辑,但需要注意的是,哈希字段的选取应具有足够的熵值,避免因为字段值分布不均导致负载倾斜。
常见问题与故障排查指南
在实际运维过程中,Hash负载均衡可能会遇到一些典型问题,了解这些问题的成因及解决方案,有助于快速恢复系统稳定性。
热点Key问题
即使使用了Hash负载均衡,如果某个Key(如热门商品ID)的请求量极大,仍然会导致对应节点负载过高,这种现象被称为“热点Key”。
解决方案
- 本地缓存:在每个节点上增加本地缓存,减少对后端存储的直接访问。
- 动态分片:将热点Key进一步拆分为多个子Key,分散到不同节点上。
- 读写分离:将读请求路由到只读副本,减轻主节点压力。
节点宕机后的数据恢复
当某个节点宕机时,其上的数据需要迁移到其他节点,如果数据量巨大,迁移过程可能耗时较长,导致服务不可用。
预取与预热机制
为避免数据迁移期间的性能抖动,可以采用预取机制,在节点下线前,提前将其上的数据异步迁移到其他节点,建立数据预热机制,在节点上线后,快速加载热点数据,确保服务快速恢复。

Hash负载均衡的未来演进趋势
随着云原生技术的发展,Hash负载均衡也在不断演进,传统的静态配置正在被动态调度算法所取代,智能负载均衡器能够根据实时负载情况,动态调整哈希策略,实现更精细化的流量控制。
智能哈希与机器学习
近年来,部分头部云厂商开始尝试将机器学习算法引入负载均衡领域,通过分析历史流量模式,预测未来的负载趋势,动态调整哈希函数的参数,从而实现更优的负载均衡效果。
边缘计算中的分布式哈希
在边缘计算场景下,网络延迟成为主要瓶颈,分布式哈希表(DHT)技术被广泛应用于边缘节点的数据定位与路由,确保数据能够在离用户最近的地方被访问,进一步提升系统响应速度。
Hash系统负载均衡常见问题解答
一致性哈希与传统取模哈希的主要区别是什么?
一致性哈希通过虚拟环结构解决了节点增减时的哈希震荡问题,而传统取模哈希在节点变化时会导致大部分请求重新路由,一致性哈希更适合节点动态变化的分布式系统,如缓存集群和微服务架构。
如何选择合适的哈希算法?
选择哈希算法时需考虑计算效率和分布均匀性,MD5和SHA1分布均匀但计算较慢,MurmurHash和CityHash计算速度快且分布良好,是高性能场景下的首选,对于大多数业务场景,MurmurHash3是平衡性能与分布性的最佳选择。
Hash负载均衡是否适用于所有业务场景?
Hash负载均衡适用于需要会话粘性或数据局部性的场景,如缓存、数据库分片等,但对于无状态服务或需要全局负载均衡的场景,DNS轮询或反向代理负载均衡可能更为合适,需根据业务特性灵活选择。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/450362.html









