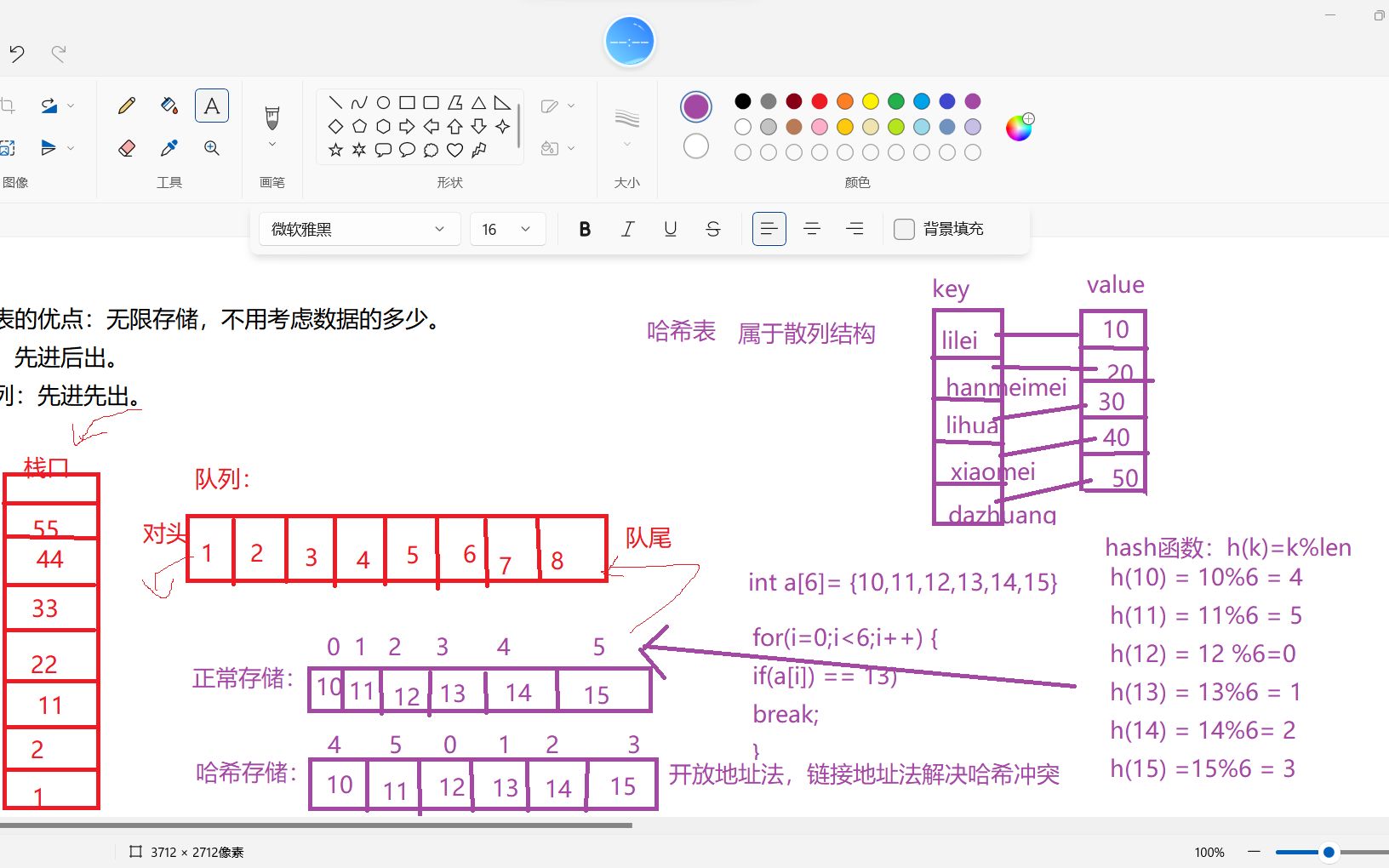
Hash存储又称为哈希存储或散列存储,其核心机制是通过哈希函数将键值映射到存储位置,从而实现接近O(1)时间复杂度的高效数据检索。
这种存储方式并非简单的“把数据扔进桶里”,而是一套精密的数学映射逻辑,在2026年的技术语境下,随着物联网设备激增和实时数据分析需求的爆发,理解Hash存储的底层逻辑与选型策略,已成为架构师和开发者必须掌握的硬核技能,它不仅是数据库索引的基石,更是分布式缓存、区块链账本等前沿技术的核心组件。
Hash存储的核心原理与运作机制
要理解Hash存储,首先要打破“线性查找”的思维定势,传统数组或链表在查找特定元素时,往往需要逐个比对,效率随数据量呈线性下降,而Hash存储通过一个特定的算法哈希函数,将任意长度的输入(键)转换为固定长度的输出(哈希值),这个输出值直接对应存储空间的地址。
哈希函数的关键作用
哈希函数的质量直接决定了存储系统的性能,一个优秀的哈希函数需要具备三个特征:确定性、均匀性和快速计算。
- 确定性:相同的输入必须始终产生相同的输出,这是数据可找回的前提。
- 均匀性:输入数据的微小变化应导致输出结果的巨大差异,确保数据均匀分布在存储桶中,避免某些桶过载而其他桶闲置。
- 快速计算:哈希运算本身必须极快,不能成为系统瓶颈。
业内专家指出,现代高性能存储系统多采用MurmurHash或CityHash等非加密级哈希算法,因为它们在速度和均匀性之间取得了最佳平衡,而非追求MD5或SHA系列的高安全性。

冲突处理策略
由于哈希值空间有限,而输入数据无限,哈希冲突是不可避免的现象,即两个不同的键映射到了同一个存储地址,解决冲突主要有两种主流方案:
链地址法(Chaining)
这是最常见的方式,每个存储桶不仅存储数据,还维护一个链表,当发生冲突时,新数据被添加到该桶的链表末尾,Redis的字典结构就广泛采用了这种机制,其优势在于实现简单,扩容时只需重新哈希即可,劣势是链表过长会导致查找效率退化。
开放寻址法(Open Addressing)
当发生冲突时,系统按照某种探测序列(如线性探测、二次探测)寻找下一个可用的空桶,这种方法缓存友好性极高,因为数据在内存中是连续存放的,但缺点是删除操作复杂,且随着负载因子增加,性能急剧下降。
Hash存储在不同场景下的选型对比
在实际工程落地中,没有绝对的“最好”,只有“最合适”,开发者需要根据业务场景,在Hash存储与关系型数据库对比时做出理性选择。
高性能缓存场景
在需要亚毫秒级响应的场景下,如用户会话管理、热点商品缓存,Hash存储是首选。
- 优势:读写速度极快,支持丰富的数据结构(如String, Hash, List, Set, ZSet)。
- 劣势:数据持久化能力弱,断电或重启可能导致数据丢失(除非配置了RDB或AOF)。
- 典型应用:Redis, Memcached。
海量日志与监控数据存储
对于时间序列数据或日志分析,传统的Hash存储往往力不从心,基于LSM-Tree(Log-Structured Merge-Tree)的存储引擎更具优势,如RocksDB。

LSM-Tree与B+Tree的区别
传统数据库多用B+Tree,适合随机读;而LSM-Tree将随机写转化为顺序写,极大提升了写入吞吐量。
| 特性 | B+Tree (MySQL InnoDB) | LSM-Tree (RocksDB) |
|---|---|---|
| 写入性能 | 中等(需维护树结构平衡) | 极高(顺序追加写) |
| 读取性能 | 高(随机读优化好) | 中等(需合并多层MemTable) |
| 空间开销 | 较低 | 较高(需定期压缩合并) |
分布式Hash存储的扩展与挑战
单机Hash存储受限于内存和磁盘容量,当数据量达到TB甚至PB级别时,必须引入分布式架构,这里涉及一个关键概念:分布式Hash存储架构设计。
一致性哈希算法
在分布式系统中,如果采用简单的取模算法(Hash(key) % N),当节点数量N发生变化(如扩容或宕机)时,大部分数据键的映射位置都会失效,导致大规模数据迁移,系统抖动剧烈。
一致性哈希(Consistent Hashing)通过将哈希值空间组织成一个虚拟的圆环,节点和数据都映射到这个圆环上,当节点增加时,只有圆环上相邻的一小部分数据需要迁移,极大地降低了系统震荡。
虚拟节点的作用
为了解决数据倾斜问题(即某些物理节点负载过重),引入了虚拟节点,一个物理节点对应多个虚拟节点分布在哈希环上,使得数据分布更加均匀。
2026年Hash存储的技术趋势与优化
随着硬件技术的进步,Hash存储也在不断演进。

内存与存储融合
近年来,CXL(Compute Express Link)等新技术的普及,使得内存池化成为可能,Hash存储不再局限于单机内存,而是可以构建跨越多台服务器的超大内存空间,进一步提升了缓存命中率。
智能索引优化
AI技术开始介入存储引擎优化,通过机器学习模型预测数据访问模式,系统可以动态调整哈希表的负载因子,甚至预加载热点数据到更快的存储层级,实现“预测性缓存”。
常见问题解答(Hash存储相关)
Hash存储与关系型数据库的核心区别是什么?
Hash存储专注于键值对的快速存取,不支持复杂的多表关联查询和事务ACID特性,适合结构化程度低、读取频率高的场景,关系型数据库则强调数据的一致性和完整性,支持SQL复杂查询,适合需要强一致性和复杂业务逻辑的场景。
如何解决Hash存储中的数据倾斜问题?
数据倾斜通常由热点Key或哈希算法不均引起,解决方案包括:1. 使用一致性哈希算法配合虚拟节点分散负载;2. 对热点Key进行拆分或单独缓存;3. 定期监控存储桶分布,动态调整哈希函数或扩容节点。
Hash存储在区块链中的应用原理是什么?
在区块链中,Hash存储用于构建默克尔树(Merkle Tree),确保交易数据的完整性和不可篡改性,每个区块包含前一个区块的哈希值,形成链式结构,任何数据的微小改动都会导致哈希值剧变,从而被网络识别为非法数据。
Hash存储不仅是技术的基石,更是应对数据爆炸时代的利器,掌握其原理与选型,能让系统在速度与容量之间找到最佳平衡点。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/454459.html