云计算
-
m5526cdn是什么?m5526cdn参数及详细功能介绍
m5526cdn并非单一标准硬件型号,而是指代基于M.2接口、支持PCIe 4.0/5.0协议及NVMe协议的固态硬盘(SSD)通用规格标识,其核心优势在于提供远超SATA接口的读写速度与低功耗特性,适合2026年主流高性能计算场景,m5526cdn技术规格深度解析在2026年的存储市场语境中,“m5526cd……
-
vue如何引入cdn,vue项目引入cdn资源方法
在Vue项目中引入CDN资源,最推荐且符合现代工程化标准的方式是通过vite.config.js或webpack的externals配置项,将Vue核心库及常用插件从构建包中排除,并在index.html中通过<script>标签引入,从而显著减小打包体积并提升首屏加载速度,核心原理与优势分析为什么……
-
阿里云cdn解析失败怎么办,阿里云cdn解析
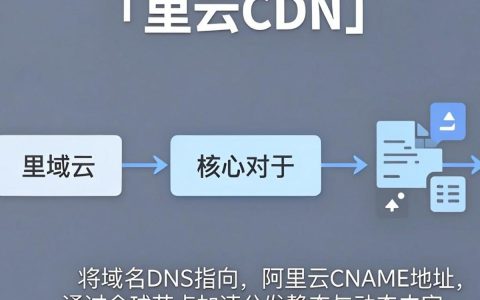
阿里云CDN解析的核心在于将域名DNS指向阿里云CNAME地址,通过全球节点加速分发静态与动态内容,实现毫秒级响应与高并发承载,是2026年企业构建高性能Web架构的基础设施标配,阿里云CDN解析的技术逻辑与核心优势在2026年的数字生态中,CDN(内容分发网络)已不再仅仅是简单的缓存服务器集群,而是融合了边缘……
-
如何创建密码服务集群与应用绑定关系?密码服务集群与应用绑定
创建密码服务集群与应用绑定关系(AssociateApps)的核心在于通过API建立应用与特定密码集群的逻辑关联,从而实现密钥的统一管理与安全调用,这是构建高可用密码基础设施的关键步骤,在数字化转型的深水区,密码服务不再仅仅是后台的一个模块,而是支撑业务安全的核心底座,当你面对庞大的应用集群时,手动配置每个应用……
-
迅雷cdn加速服务怎么用,迅雷cdn加速服务
迅雷CDN加速服务通过结合P2P技术与全球边缘节点,能为视频、游戏及大型文件下载提供显著的带宽优化与延迟降低效果,是2026年高并发场景下兼顾成本与体验的优选方案,在数字化转型的深水区,内容分发网络(CDN)已不再仅仅是静态资源的搬运工,而是演变为决定用户体验上限的关键基础设施,对于内容提供商而言,如何在保证高……
-
阿里云CDN缓存怎么设置,阿里云CDN缓存配置方法
阿里云CDN缓存的核心机制是通过边缘节点就近存储静态资源,利用TTL(生存时间)策略与主动刷新功能,将响应延迟降低至毫秒级,显著提升网站加载速度并降低源站负载,阿里云CDN缓存机制深度解析分发网络)并非简单的文件复制,而是基于智能调度系统的分布式存储架构,在2026年的技术语境下,阿里云CDN已全面融入AI驱动……
-
阿里cdn和网宿哪个更好用,阿里cdn网宿对比
2026年企业选型结论:若业务重心在大陆境内且追求极致性价比与合规稳定性,首选阿里CDN;若涉及跨国出海、海外节点覆盖或混合云架构,网宿科技(CDNetworks)具备更优的全球加速能力,在2026年的数字基础设施格局中,内容分发网络(CDN)已从单纯的“加速工具”演变为保障业务连续性、数据安全及用户体验的核心……
-
国内免费cdn加速,免费cdn加速哪家好
国内免费CDN加速并非无中生有,而是依托云厂商“基础套餐+资源置换”模式的有限服务,适合个人博客、小型测试站及低频访问项目,但在高并发、大带宽及稳定性上存在显著瓶颈,建议根据业务规模理性选择,在2026年的数字生态中,网络延迟与访问速度依然是决定用户体验的核心指标,对于大量中小开发者而言,服务器成本是首要考量……
-
CDN加速免费吗,CDN加速服务价格
CDN加速并非完全免费,目前主流厂商仅提供有限额的“免费套餐”或“新用户试用”,长期稳定运行且满足高并发需求的商业级CDN必须付费,在2026年的互联网基础设施环境中,随着4K/8K视频流媒体、云游戏及AI大模型应用的普及,网络带宽成本与传输延迟成为影响用户体验的核心指标,许多站长和企业决策者仍抱有“CDN完全……
-
北京备案撤销和放弃有什么区别?北京取消网站备案流程
“撤销备案”是主动注销原有ICP备案信息,而“放弃备案”通常指在审核期间或注销后不再维持备案资格,两者核心区别在于对已备案主体资格的处理方式及后续影响,建议根据是否保留网站运营需求谨慎选择,在互联网合规管理的语境下,备案状态直接关联着网站的生死存亡,许多站长在遇到服务器迁移、业务调整或不再运营网站时,常混淆“撤……