云计算
-
cdn国外厂家有哪些,cdn国外厂家哪家好
2026年访问海外业务首选CDN国外厂家,Cloudflare、Akamai及Fastly凭借全球节点覆盖与AI驱动的安全防护能力,成为跨国企业构建低延迟、高可用网络基础设施的核心选择,在全球数字化加速融合的背景下,中国企业出海及海外用户访问国内业务的需求日益复杂,传统的单一线路加速已无法满足2026年对实时交……
-
2017年cdn行业现状,2017年cdn行业市场规模多大
2017年CDN行业正处于从“带宽价格战”向“内容安全与智能化服务”转型的关键拐点,头部厂商通过构建全球节点网络与强化Web安全防护,确立了以“安全+加速”为核心的竞争壁垒,这一年,中国互联网基础设施迎来了深刻的结构性调整,随着移动互联网红利的见顶和云计算概念的普及,传统的单纯提供带宽分发的CDN模式已难以为继……
-
cdn设置不兼容怎么办?cdn配置报错解决方法
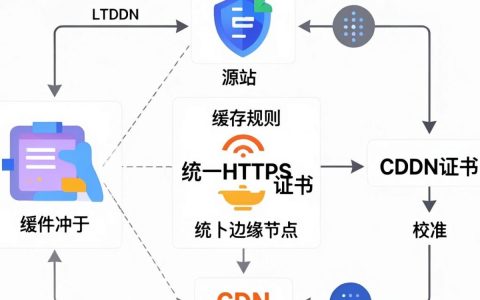
CDN设置不兼容的核心原因在于源站协议、缓存规则与CDN边缘节点配置存在逻辑冲突,解决的关键在于统一HTTPS证书、校准缓存TTL及排查WAF策略拦截,在2026年的Web架构中,内容分发网络(CDN)已成为标配,但“设置不兼容”导致的加载失败、回源超时或安全拦截仍是企业运维的高频痛点,这并非单一技术故障,而是……
-
七牛公共CDN是什么,七牛云存储CDN加速
七牛公共CDN在2026年仍是中小企业及初创团队获取低成本、高可用静态资源加速服务的最佳选择,其核心优势在于极致的性价比与免运维的稳定性,但在高并发动态场景下需配合私有化部署方案,七牛公共CDN的核心价值与适用场景在2026年的数字内容分发市场中,CDN(内容分发网络)已从单纯的“加速工具”演变为“业务稳定性基……
-
nw111.cdn是什么,nw111.cdn链接打不开怎么办
2026年【nw111.cdn】作为新一代智能边缘分发节点,通过动态路径优化与AI预测缓存技术,显著降低高并发场景下的延迟,是追求极致加载速度与稳定性的企业首选解决方案,在数字化转型的深水区,内容分发网络(CDN)已不再仅仅是静态资源的加速器,而是演变为决定用户体验与业务转化的核心基础设施,随着2026年5G……
-
加cdn的好处是什么,CDN加速原理
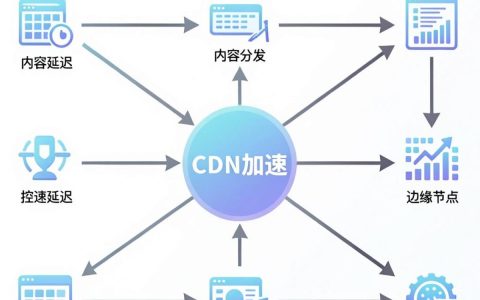
CDN(内容分发网络)的核心价值在于通过边缘节点就近分发资源,将首屏加载速度提升30%-50%,显著降低源站带宽成本,并有效抵御高频DDoS攻击,是2026年保障网站高可用性与用户体验的基础设施标配, 性能跃升:从“快”到“极速”的技术逻辑在2026年的移动互联网环境下,用户对页面加载的容忍度已降至毫秒级,CD……
-
国内cdn厂商对比哪家强?国内cdn厂商对比
2026年国内CDN厂商对比结论:若追求极致性价比与海量小文件分发,推荐阿里云与腾讯云;若侧重视频直播低延迟与边缘计算深度融合,网宿科技与白山云更具优势;跨国业务则首选腾讯云国际版或AWS CloudFront,在2026年的数字内容分发领域,CDN(内容分发网络)已不再仅仅是静态资源的加速器,而是演变为集边缘……
-
包周期到底划不划算?包年包月哪个更省钱
包周期模式通过预付固定费用锁定长期服务权益,虽在初期投入上高于按需付费,但在业务稳定、用量可预测的场景下,能显著降低综合成本并简化财务管理,是追求预算可控性的企业首选方案,包周期模式的核心逻辑与适用场景在云计算和SaaS服务领域,计费方式的选择直接决定了企业的运营成本结构,包周期,本质上是一种“以时间换空间”的……
-
直播cdn加速原理是什么,直播cdn加速原理
直播CDN加速的核心原理是通过将内容分发至离用户最近的边缘节点,利用智能调度系统实现“就近接入、就近回源”,从而将延迟降低至毫秒级并大幅缓解源站压力,在2026年的超高清直播时代,观众对4K/8K及低延迟互动的要求已呈指数级增长,传统的单点服务器架构已无法支撑亿级并发流量,CDN(内容分发网络)成为保障直播流畅……
-
cdn架构图详解,cdn是什么
CDN架构的核心在于通过全球分布的边缘节点缓存内容,利用智能调度系统将用户请求导向最优节点,从而显著降低延迟并提升加载速度,2026年主流架构已全面向边缘计算与AI动态调度融合演进,CDN架构的核心逻辑与演进趋势Content Delivery Network(内容分发网络)并非简单的服务器集群,而是一个复杂的……