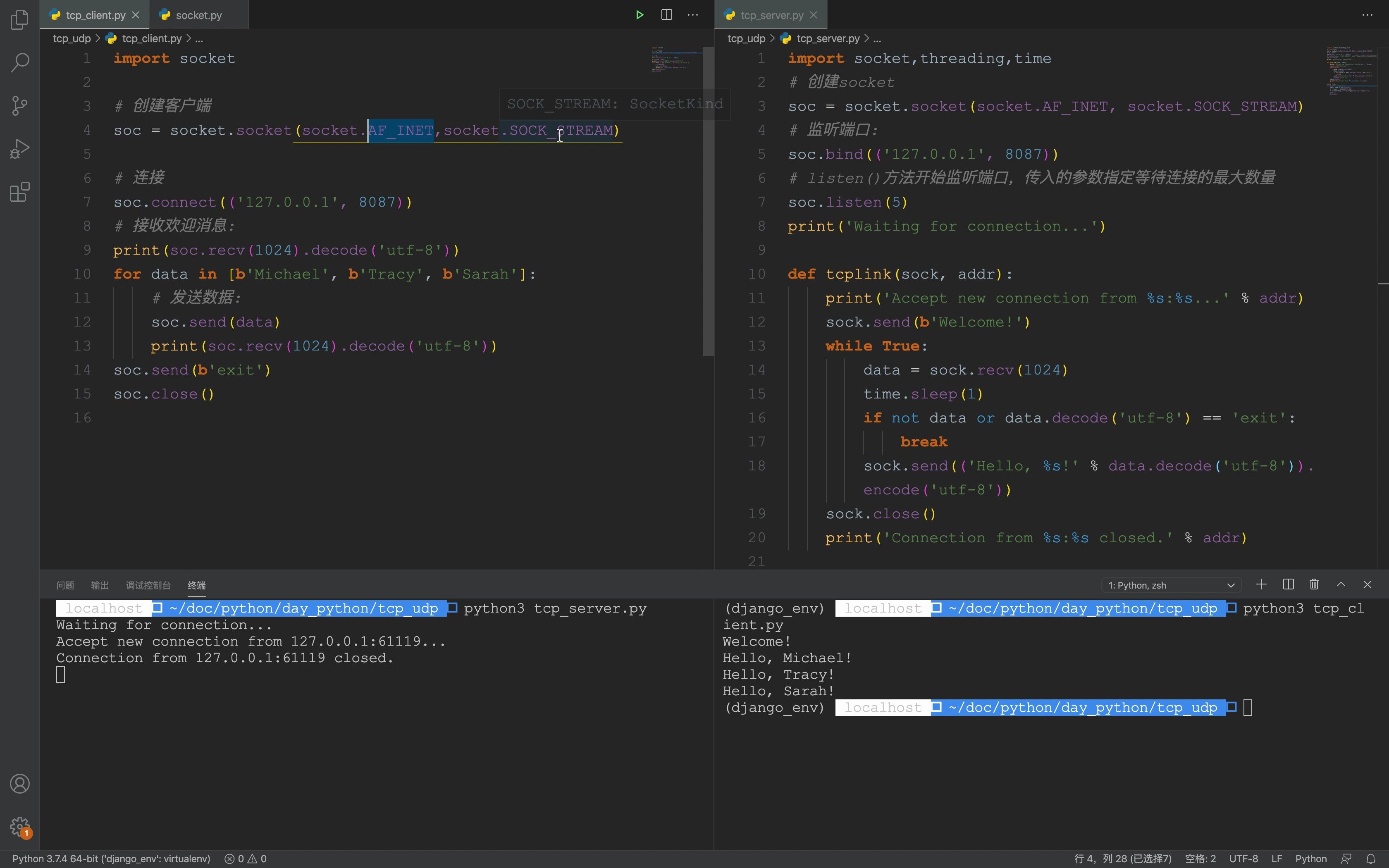
服务器与客户端通信的核心在于建立稳定、低延迟的双向数据通道,通过TCP/IP协议栈确保数据包完整有序地传输,并利用HTTP/HTTPS或WebSocket等应用层协议实现业务逻辑的高效交互。
在现代互联网架构中,无论是你点击网页加载图片,还是手机App实时接收推送通知,背后都是服务器和客户端通信在默默支撑,很多人觉得这只是简单的“发”和“收”,但实际上,这涉及到复杂的握手、验证、加密和状态维持过程,如果这一环节出现波动,轻则页面卡顿,重则数据丢失,理解其底层逻辑,对于优化用户体验和系统稳定性至关重要。
服务器和客户端通信的基础原理与协议选择
通信的本质是双方遵循同一套“语言”规则,在IT行业,这套规则就是网络协议,业内专家指出,选择合适的协议是构建高效通信系统的第一步。
TCP与UDP:可靠传输与极速响应的权衡
大多数传统Web应用依赖TCP(传输控制协议),它像是一个严谨的快递员,每发一个包裹都要确认对方签收,如果没收到就重发,这种机制保证了数据的完整性,适合网页浏览、文件下载等场景。
相比之下,UDP(用户数据报协议)更像是一个扔信筒的邮差,发出去就不管了,它没有握手过程,速度快,延迟极低,但可能丢包,它常用于视频会议、在线游戏等对实时性要求极高、允许少量丢包的场景。
HTTP/HTTPS与WebSocket:从单向到双向的演进
早期的Web通信主要依靠HTTP协议,这是一种“请求-响应”模式,客户端发起请求,服务器返回数据,然后连接断开,这种模式在静态页面时代足够用,但在现代动态应用中显得力不从心。
为了解决实时性问题,WebSocket应运而生,它允许在客户端和服务器之间建立一个持久的全双工连接,一旦连接建立,双方都可以随时主动发送数据,无需反复建立连接。
| 协议类型 | 连接方式 | 实时性 | 适用场景 | 安全性 |
|---|---|---|---|---|
| HTTP/HTTPS | 短连接,请求响应式 | 低,需轮询 | 网页浏览、API接口 | 高(HTTPS加密) |
| WebSocket | 长连接,全双工 | 极高,即时推送 | 聊天室、股票行情、在线游戏 | 高(WSS加密) |
| MQTT | 发布/订阅模式 | 高,轻量级 | 物联网设备、智能家居 | 中,依赖配置 |

服务器和客户端通信中的安全机制与数据加密
数据在公网上传输,就像在大街上寄明信片,任何人都可能看到内容,安全机制是通信中不可或缺的一环。
SSL/TLS加密:构建信任的通道
为了防止数据被窃听或篡改,业界普遍采用SSL(安全套接字层)或其继任者TLS(传输层安全)协议,当你在浏览器地址栏看到小锁图标时,说明当前通信已通过TLS加密。
这个过程涉及“握手”阶段:客户端和服务器交换公钥,协商加密算法,并验证服务器身份(通过数字证书),一旦握手成功,后续传输的数据都会经过加密处理,据工信部数据,目前主流浏览器已强制要求HTTPS,未加密的HTTP网站会被标记为“不安全”,这直接影响了用户的信任度和转化率。
身份认证:确保“对的人”在通信
除了通道安全,还需要确认通信对方的身份,常见的认证方式包括:
- API Key:简单的密钥验证,适合内部服务调用。
- OAuth 2.0:授权框架,允许用户在不提供密码的情况下授权第三方应用访问资源。
- JWT(JSON Web Token):一种紧凑的自包含令牌,常用于无状态的身份验证,服务器签发JWT,客户端在后续请求中携带该令牌,服务器验证签名即可确认身份,无需查询数据库,极大提升了性能。

高并发场景下的服务器和客户端通信优化策略
当用户量激增时,通信瓶颈往往出现在服务器端,如何保持流畅体验,需要一系列优化手段。
连接复用与Keep-Alive
HTTP/1.1引入了Keep-Alive机制,允许在同一个TCP连接上发送多个请求,这减少了频繁建立和断开连接带来的开销(RTT),对于高并发场景,启用连接复用可以显著降低服务器负载。
数据压缩与二进制协议
文本协议(如JSON)虽然易读,但体积较大,在带宽受限或移动网络环境下,使用GZIP或Brotli压缩可以减小传输体积,对于性能要求极高的场景,可以考虑使用Protobuf或MessagePack等二进制序列化格式,它们比JSON更小、解析更快。
负载均衡与集群部署
单台服务器无法应对所有请求,通过Nginx或HAProxy等负载均衡器,可以将流量分发到多台后端服务器,配合Redis等缓存层,将热点数据存储在内存中,减少数据库查询压力,从而提升整体通信效率。
服务器和客户端通信常见问题排查与调试技巧
当通信出现问题时,快速定位原因至关重要。
网络层故障排查
首先检查网络连通性,使用ping命令测试服务器IP的可达性,使用telnet或nc命令测试端口是否开放,如果端口不通,可能是防火墙拦截或服务器未启动服务。
应用层错误分析
如果网络通畅但业务异常,需查看HTTP状态码:
- 4xx系列:客户端错误,如404表示资源不存在,401表示未授权,403表示禁止访问。
- 5xx系列:服务器错误,如500表示内部服务器错误,502表示网关错误,503表示服务不可用。
使用浏览器开发者工具的Network面板,可以直观地查看请求头、响应头、请求耗时和响应内容,重点关注“Timing”标签,分析等待时间(TTFB)和下载时间,判断瓶颈是在网络传输还是服务器处理。
日志监控与链路追踪
在生产环境中,日志是排查问题的金矿,确保应用服务器和Web服务器都开启了详细日志,结合ELK(Elasticsearch, Logstash, Kibana)或Prometheus+Grafana等监控工具,可以实时追踪请求链路,快速发现异常节点。

服务器和客户端通信的未来趋势与技术演进
随着5G和边缘计算的普及,通信模式正在发生深刻变化。
QUIC协议:下一代传输层标准
QUIC(Quick UDP Internet Connections)是基于UDP的传输协议,由Google提出并逐渐成为IETF标准,它内置了加密(TLS 1.3),解决了TCP队头阻塞问题,实现了更快的连接建立(0-RTT)和更好的弱网适应性,QUIC有望取代TCP成为Web通信的主流底层协议。
边缘计算与就近服务
传统架构中,所有请求都回到中心数据中心处理,延迟较高,边缘计算将计算和存储能力下沉到离用户更近的边缘节点,这样,服务器和客户端通信的距离缩短,延迟大幅降低,特别适合视频直播、IoT设备管理等场景。
服务器和客户端通信Q&A
为什么我的API接口在移动端响应慢而在PC端正常?
这通常与网络环境和协议优化有关,移动网络可能存在高延迟或不稳定,而PC端通常使用有线宽带,移动端屏幕较小,可能不需要传输大量非关键数据,但接口若未做差异化处理,仍会返回完整JSON,导致解析耗时,建议针对移动端接口进行数据裁剪,启用GZIP压缩,并考虑使用WebSocket或GraphQL以减少请求次数。
WebSocket连接频繁断开的常见原因有哪些?
主要原因包括:1. 中间网络设备(如防火墙、负载均衡器)超时断开空闲连接,需配置心跳包(Heartbeat)维持连接;2. 服务器资源不足导致崩溃或重启;3. 客户端网络切换(如WiFi切4G)导致IP变化,需实现重连机制;4. 协议版本不兼容或SSL证书过期。
如何判断当前通信瓶颈是在网络还是服务器处理?
通过观察请求的时间分布,等待服务器响应”(TTFB)时间很长,而“内容下载”时间很短,说明瓶颈在服务器端(如数据库查询慢、逻辑复杂),如果TTFB很短,但“内容下载”时间长,说明瓶颈在网络带宽或数据传输量上,若两者都长,则可能是服务器负载过高或网络拥塞。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/451780.html